一致性hash-java实现treemap版
2017-02-15 16:35
260 查看
把不同号段的数据储存在不同的机器上,以用来分散压力。假如我们有一百万个QQ号,十台机器,,如何划分呢?
最简单粗暴的方法是用QQ号直接对10求余,结果为0-9 分别对应上面的十台机器。比如QQ号为 23900 的用户在编号为0的机器 23901的用户在编号为1的机器,以此类推。那么问题来了,现在QQ用户急剧上升 由一百万涨到了五百万,显然10台机器已经无能为力
了,于是我们扩充到25台。这个时候我们发现以前的数据全乱了。完蛋!只能跑路了……
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object)%N 难以满足单调性要求。
所以在保证合理分散的情况下,我们还是是可拓展的。这就是一致性hash,一致性hash 算法都是将 value 映射到一个 32 位的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,当有数据过来按顺时针找到离他最近的一个点,这个点,就是我要的节点机器。如下图:
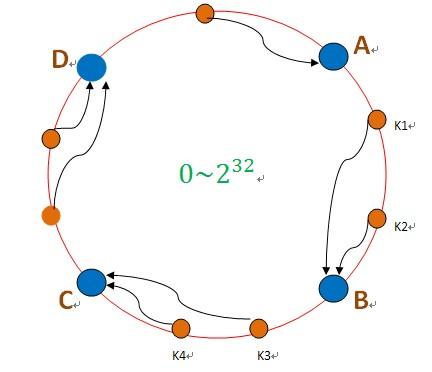
hash("192.168.128.670") ---->A //根据服务器IP hash出去生成节点
hash("192.168.148.670") ---->C //根据服务器IP hash出去生成节点
hash("81288812") ----> k1 //根据QQ号 hash出去生成值 ----->顺时针找到机器
hash("8121243812") ----> k4 //根据QQ号 hash出去生成值 ----->顺时针找到机器
这样当有新的机器加进来,旧的机器去掉,影响的也是一小部分的数据。这样看似比较完美了,,但假如其中一个节点B数据激增,挂了,所有数据会倒到C--->C也扛不住了---->所有数据会倒到D ……以此类推,最终全挂了!整个世界清静了!!!
显然,这种方式因为数据的不平均导致服务挂了。所以我们的一致性hash还需要具有平衡性。
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
为解决平衡性,一致性hash引入了虚拟节点”的概念。“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。这样我们如果有25台服务器,每台虚拟成10个,就有250个虚拟节点。这样就保证了每个节点的负载不会太大,压力均摊,有事大家一起扛!!!
hash("192.168.128.670#36kr01") ---->A //根据服务器IP hash出去生成节点
hash("192.168.128.670#36kr02") ---->B //根据服务器IP hash出去生成节点
hash("192.168.128.670#36kr03") ---->B //根据服务器IP hash出去生成节点
……
final 虚拟节点+murmurhash成了我们的解决方案:
最简单粗暴的方法是用QQ号直接对10求余,结果为0-9 分别对应上面的十台机器。比如QQ号为 23900 的用户在编号为0的机器 23901的用户在编号为1的机器,以此类推。那么问题来了,现在QQ用户急剧上升 由一百万涨到了五百万,显然10台机器已经无能为力
了,于是我们扩充到25台。这个时候我们发现以前的数据全乱了。完蛋!只能跑路了……
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object)%N 难以满足单调性要求。
所以在保证合理分散的情况下,我们还是是可拓展的。这就是一致性hash,一致性hash 算法都是将 value 映射到一个 32 位的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,当有数据过来按顺时针找到离他最近的一个点,这个点,就是我要的节点机器。如下图:
hash("192.168.128.670") ---->A //根据服务器IP hash出去生成节点
hash("192.168.148.670") ---->C //根据服务器IP hash出去生成节点
hash("81288812") ----> k1 //根据QQ号 hash出去生成值 ----->顺时针找到机器
hash("8121243812") ----> k4 //根据QQ号 hash出去生成值 ----->顺时针找到机器
这样当有新的机器加进来,旧的机器去掉,影响的也是一小部分的数据。这样看似比较完美了,,但假如其中一个节点B数据激增,挂了,所有数据会倒到C--->C也扛不住了---->所有数据会倒到D ……以此类推,最终全挂了!整个世界清静了!!!
显然,这种方式因为数据的不平均导致服务挂了。所以我们的一致性hash还需要具有平衡性。
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
为解决平衡性,一致性hash引入了虚拟节点”的概念。“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。这样我们如果有25台服务器,每台虚拟成10个,就有250个虚拟节点。这样就保证了每个节点的负载不会太大,压力均摊,有事大家一起扛!!!
hash("192.168.128.670#36kr01") ---->A //根据服务器IP hash出去生成节点
hash("192.168.128.670#36kr02") ---->B //根据服务器IP hash出去生成节点
hash("192.168.128.670#36kr03") ---->B //根据服务器IP hash出去生成节点
……
final 虚拟节点+murmurhash成了我们的解决方案:
class Shard<S> { // S类封装了机器节点的信息 ,如name、password、ip、port等
private TreeMap<Long, S> nodes; // 虚拟节点
private List<S> shards; // 真实机器节点
private final int NODE_NUM = 100; // 每个机器节点关联的虚拟节点个数
public Shard(List<S> shards) {
super();
this.shards = shards;
init();
}
private void init() { // 初始化一致性hash环
nodes = new TreeMap<Long, S>();
for (int i = 0; i != shards.size(); ++i) { // 每个真实机器节点都需要关联虚拟节点
final S shardInfo = shards.get(i);
for (int n = 0; n < NODE_NUM; n++)
// 一个真实机器节点关联NODE_NUM个虚拟节点
nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
}
}
public S getShardInfo(String key) {
SortedMap<Long, S> tail = nodes.tailMap(hash(key)); // 沿环的顺时针找到一个虚拟节点
if (tail.size() == 0) {
return nodes.get(nodes.firstKey());
}
return tail.get(tail.firstKey()); // 返回该虚拟节点对应的真实机器节点的信息
}
/**
* MurMurHash算法,是非加密HASH算法,性能很高,
* 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免)
* 等HASH算法要快很多,而且据说这个算法的碰撞率很低.
* http://murmurhash.googlepages.com/ */
private Long hash(String key) {
ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
int seed = 0x1234ABCD;
ByteOrder byteOrder = buf.order();
buf.order(ByteOrder.LITTLE_ENDIAN);
long m = 0xc6a4a7935bd1e995L;
int r = 47;
long h = seed ^ (buf.remaining() * m);
long k;
while (buf.remaining() >= 8) {
k = buf.getLong();
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
if (buf.remaining() > 0) {
ByteBuffer finish = ByteBuffer.allocate(8).order(
ByteOrder.LITTLE_ENDIAN);
// for big-endian version, do this first:
// finish.position(8-buf.remaining());
finish.put(buf).rewind();
h ^= finish.getLong();
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
buf.order(byteOrder);
return h;
}
}

相关文章推荐
- 6. 一致性Hash 算法的Java实现
- 分布式缓存的一致性Hash的Java实现
- 【策略】一致性Hash算法(Hash环)的java代码实现
- 一致性Hash 算法的Java实现
- hash一致性java实现
- redis---一致性hash特性及java实现
- java实现分布式环境Hash一致性
- 一致性Hash Java实现版
- 深入Java集合学习系列:ConcurrentHashSet简单实现
- Java实现一致性Hash算法
- 一致性hash的C++实现
- Memcached-Java-Client 如何开启一致性hash?
- 使用JAVA实现PHP中hash_hmac 函数
- Hash哈希(二)一致性Hash(C++实现)
- Java String中的hashCode函数 以BKDR Hash Function实现
- 一致性hash C++实现
- 使用HashRing实现python下的一致性hash
- ngx_lua 一致性hash实现
- libmemcached的一致性hash实现源码分析
- TrafficServer一致性Hash的实现分析