Android面试题详细整理系列(三)
2017-02-14 22:07
423 查看
以下这些面试题都是笔者在(2017年2月-2017年3月)这段时间所面试Android工程师的总结而来,面试的公司包括巨头xx等,还有新贵公司如dd在线科技,gg金融,zk网,momo科技,zbj等,还有小型活力公司如软都科技,星云颜值,英克科技等,不足之处,还望各位不吝赐教。
1.java中线程同步的方法有哪些?
为什么要线程同步
java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(如数据的增删改查),将会导致数据不准确,相互之间产生冲突,因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,从而保证了该变量的唯一性和准确性。
保证同步的方法
1.同步方法
即有synchronized关键字修饰的方法。
由于java的每个对象都有一个内置锁,当用此关键字修饰方法时,
内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。
代码如:
public synchronized void save(){}
注: synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类
2.同步代码块
即有synchronized关键字修饰的语句块。
被该关键字修饰的语句块会自动被加上内置锁,从而实现同步
代码如:
synchronized(object){
}
注:同步是一种高开销的操作,因此应该尽量减少同步的内容。
通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
代码实例:
3.使用特殊域变量(volatile)实现线程同步(提供了可见性)
a.volatile关键字为域变量的访问提供了一种免锁机制,
b.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新,
c.因此每次使用该域就要重新计算,而不是使用寄存器中的值
d.volatile不会提供任何原子操作,它也不能用来修饰final类型的变量
例如:
在上面的例子当中,只需在account前面加上volatile修饰,即可实现线程同步。
代码实例:
注:多线程中的非同步问题主要出现在对域的读写上,如果让域自身避免这个问题,则就不需要修改操作该域的方法。
用final域,有锁保护的域和volatile域可以避免非同步的问题。
4.使用重入锁实现线程同步
在JavaSE5.0中新增了一个java.util.concurrent包来支持同步。
ReentrantLock类是可重入、互斥、实现了Lock接口的锁,
它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力
ReenreantLock类的常用方法有:
ReentrantLock() : 创建一个ReentrantLock实例
lock() : 获得锁
unlock() : 释放锁
注:ReentrantLock()还有一个可以创建公平锁的构造方法,但由于能大幅度降低程序运行效率,不推荐使用
例如:
在上面例子的基础上,改写后的代码为:
代码实例:
注:关于Lock对象和synchronized关键字的选择:
a.最好两个都不用,使用一种java.util.concurrent包提供的机制, 能够帮助用户处理所有与锁相关的代码。
b.如果synchronized关键字能满足用户的需求,就用synchronized,因为它能简化代码
c.如果需要更高级的功能,就用ReentrantLock类,此时要注意及时释放锁,否则会出现死锁,通常在finally代码释放锁
5.使用局部变量实现线程同步
如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
ThreadLocal 类的常用方法
ThreadLocal() : 创建一个线程本地变量
get() : 返回此线程局部变量的当前线程副本中的值
initialValue() : 返回此线程局部变量的当前线程的"初始值"
set(T value) : 将此线程局部变量的当前线程副本中的值设置为value
例如:
在上面例子基础上,修改后的代码为:
代码实例:
a.ThreadLocal与同步机制都是为了解决多线程中相同变量的访问冲突问题。
b.前者采用以"空间换时间"的方法,后者采用以"时间换空间"的方式
2.HashMap的实现原理
1. HashMap概述:
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
2. HashMap的数据结构:
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
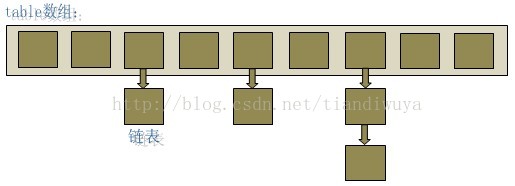
从上图中可以看出,HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组。
3. HashMap的存取实现:
从上面的源代码中可以看出:当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
4.HashMap、HashTable的区别,以及ConcurrentHashMap的了解
HashTable的应用非常广泛,HashMap是新框架中用来代替HashTable的类,也就是说建议使用HashMap,不要使用HashTable。
1.HashTable的方法是同步的,HashMap未经同步,所以在多线程场合要手动同步HashMap这个区别就像Vector和ArrayList一样。
2.HashTable不允许null值(key和value都不可以),HashMap允许null值(key和value都可以)。
3.HashTable有一个contains(Object value),功能和containsValue(Object value)功能一样。
4.HashTable使用Enumeration,HashMap使用Iterator。 以上只是表面的不同,它们的实现也有很大的不同。
5.HashTable中hash数组默认大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
6.哈希值的使用不同,HashTable直接使用对象的hashCode,而HashMap重新计算hash值,而且用与代替求模。
HashMap不是线程安全的,因此多线程操作时需要格外小心。在JDK1.5中,伟大的Doug Lea给我们带来了concurrent包,从此Map也有安全的ConcurrentHashMap。
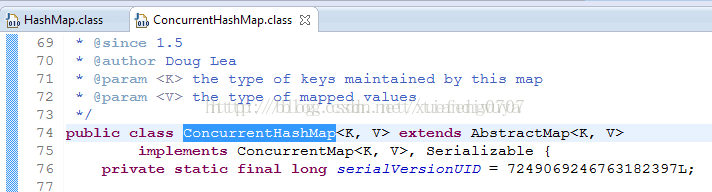
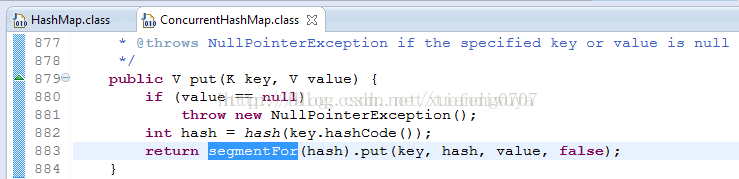
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
5.java的内存回收机制以及类的加载机制
在Java中,当没有对象引用指向原先分配给某个对象的内存时,该内存便成为垃圾。JVM的一个系统级线程会自动释放该内存块。垃圾收集意味着程序不再需要的对象是"无用信息",这些信息将被丢弃。当一个对象不再被引用的时候,内存回收它占领的空间,以便空间被后来的新对象使用。事实上,除了释放没用的对象,垃圾收集也可以清除内存记录碎片。由于创建对象和垃圾收集器释放丢弃对象所占的内存空间,内存会出现碎片。碎片是分配给对象的内存块之间的空闲内存洞。碎片整理将所占用的堆内存移到堆的一端,JVM将整理出的内存分配给新的对象。
垃圾收集能自动释放内存空间,减轻编程的负担。这使Java 虚拟机具有一些优点。首先,它能使编程效率提高。在没有垃圾收集机制的时候,可能要花许多时间来解决一个难懂的存储器问题。在用Java语言编程的时候,靠垃圾收集机制可大大缩短时间。其次是它保护程序的完整性, 垃圾收集是Java语言安全性策略的一个重要部份。
垃圾收集的算法分析
Java语言规范没有明确地说明JVM使用哪种垃圾回收算法,但是任何一种垃圾收集算法一般要做2件基本的事情:(1)发现无用信息对象;(2)回收被无用对象占用的内存空间,使该空间可被程序再次使用。
大多数垃圾回收算法使用了根集(root set)这个概念;所谓根集就量正在执行的Java程序可以访问的引用变量的集合(包括局部变量、参数、类变量),程序可以使用引用变量访问对象的属性和调用对象的方法。垃圾收集首选需要确定从根开始哪些是可达的和哪些是不可达的,从根集可达的对象都是活动对象,它们不能作为垃圾被回收,这也包括从根集间接可达的对象。而根集通过任意路径不可达的对象符合垃圾收集的条件,应该被回收。下面介绍几个常用的算法。
1、 引用计数法(Reference Counting Collector)
引用计数法是唯一没有使用根集的垃圾回收的法,该算法使用引用计数器来区分存活对象和不再使用的对象。一般来说,堆中的每个对象对应一个引用计数器。当每一次创建一个对象并赋给一个变量时,引用计数器置为1。当对象被赋给任意变量时,引用计数器每次加1当对象出了作用域后(该对象丢弃不再使用),引用计数器减1,一旦引用计数器为0,对象就满足了垃圾收集的条件。
基于引用计数器的垃圾收集器运行较快,不会长时间中断程序执行,适宜地必须 实时运行的程序。但引用计数器增加了程序执行的开销,因为每次对象赋给新的变量,计数器加1,而每次现有对象出了作用域生,计数器减1。
2、tracing算法(Tracing Collector)
tracing算法是为了解决引用计数法的问题而提出,它使用了根集的概念。基于tracing算法的垃圾收集器从根集开始扫描,识别出哪些对象可达,哪些对象不可达,并用某种方式标记可达对象,例如对每个可达对象设置一个或多个位。在扫描识别过程中,基于tracing算法的垃圾收集也称为标记和清除(mark-and-sweep)垃圾收集器.
3、compacting算法(Compacting Collector)
为了解决堆碎片问题,基于tracing的垃圾回收吸收了Compacting算法的思想,在清除的过程中,算法将所有的对象移到堆的一端,堆的另一端就变成了一个相邻的空闲内存区,收集器会对它移动的所有对象的所有引用进行更新,使得这些引用在新的位置能识别原来 的对象。在基于Compacting算法的收集器的实现中,一般增加句柄和句柄表。
4、copying算法(Coping Collector)
该算法的提出是为了克服句柄的开销和解决堆碎片的垃圾回收。它开始时把堆分成 一个对象 面和多个空闲面, 程序从对象面为对象分配空间,当对象满了,基于coping算法的垃圾 收集就从根集中扫描活动对象,并将每个 活动对象复制到空闲面(使得活动对象所占的内存之间没有空闲洞),这样空闲面变成了对象面,原来的对象面变成了空闲面,程序会在新的对象面中分配内存。
一种典型的基于coping算法的垃圾回收是stop-and-copy算法,它将堆分成对象面和空闲区域面,在对象面与空闲区域面的切换过程中,程序暂停执行。
5、generation算法(Generational Collector)
stop-and-copy垃圾收集器的一个缺陷是收集器必须复制所有的活动对象,这增加了程序等待时间,这是coping算法低效的原因。在程序设计中有这样的规律:多数对象存在的时间比较短,少数的存在时间比较长。因此,generation算法将堆分成两个或多个,每个子堆作为对象的一代(generation)。由于多数对象存在的时间比较短,随着程序丢弃不使用的对象,垃圾收集器将从最年轻的子堆中收集这些对象。在分代式的垃圾收集器运行后,上次运行存活下来的对象移到下一最高代的子堆中,由于老一代的子堆不会经常被回收,因而节省了时间。
6、adaptive算法(Adaptive Collector)
在特定的情况下,一些垃圾收集算法会优于其它算法。基于Adaptive算法的垃圾收集器就是监控当前堆的使用情况,并将选择适当算法的垃圾收集器。
类加载机制
JVM的类加载是通过ClassLoader及其子类来完成的,类的层次关系和加载顺序可以由下图来描述:
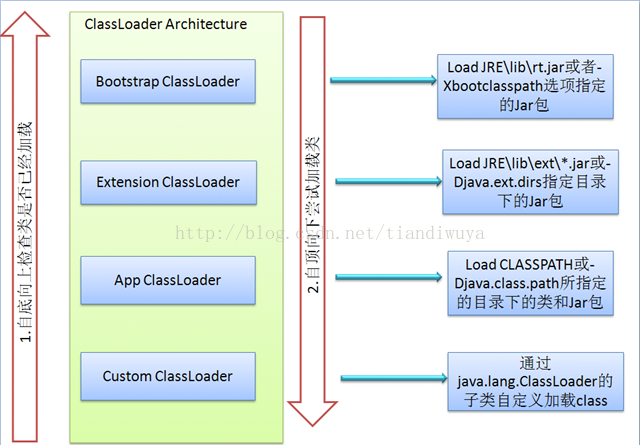
1)Bootstrap ClassLoader
负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类
2)Extension ClassLoader
负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包
3)App ClassLoader
负责记载classpath中指定的jar包及目录中class
4)Custom ClassLoader
属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个classloader已加载就视为已加载此类,保证此类只所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
6.如何判断两个链表相交?
采用快慢指针方法,遍历两个表分别知道两个表的长度a, b。然后让长表先走|a-b|步后,短表再开始走,直到相同。时间复杂度为o(m+n),具体的解决思路,可以看看这篇文章判断两个链表是否相交并找出交点
在写作本篇博客的时候,借鉴了很多同行的博客,在此感谢zhangshixi,xuefeng0707,小小中,南蛮虫等
我是kris,See you next time!!!
java笔记--关于线程同步(5种同步方式)
深入Java集合学习系列:HashMap的实现原理 (zhangshixi)
HashMap与ConcurrentHashMap的区别 (xuefeng0707)
HashTable 和 HashMap 的区别 (小小中)
java内存回收机制 (南蛮虫)
JVM原理讲解和调优
1.java中线程同步的方法有哪些?
为什么要线程同步
java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(如数据的增删改查),将会导致数据不准确,相互之间产生冲突,因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,从而保证了该变量的唯一性和准确性。
保证同步的方法
1.同步方法
即有synchronized关键字修饰的方法。
由于java的每个对象都有一个内置锁,当用此关键字修饰方法时,
内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。
代码如:
public synchronized void save(){}
注: synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类
2.同步代码块
即有synchronized关键字修饰的语句块。
被该关键字修饰的语句块会自动被加上内置锁,从而实现同步
代码如:
synchronized(object){
}
注:同步是一种高开销的操作,因此应该尽量减少同步的内容。
通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
代码实例:
/**
* 线程同步的运用
*
* @author XIEHEJUN
*
*/
public class SynchronizedThread {
class Bank {
private int account = 100;
public int getAccount() {
return account;
}
/**
* 用同步方法实现
*
* @param money
*/
public synchronized void save(int money) {
account += money;
}
/**
* 用同步代码块实现
*
* @param money
*/
public void save1(int money) {
synchronized (this) {
account += money;
}
}
}
class NewThread implements Runnable {
private Bank bank;
public NewThread(Bank bank) {
this.bank = bank;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
// bank.save1(10);
bank.save(10);
System.out.println(i + "账户余额为:" + bank.getAccount());
}
}
}
/**
* 建立线程,调用内部类
*/
public void useThread() {
Bank bank = new Bank();
NewThread new_thread = new NewThread(bank);
System.out.println("线程1");
Thread thread1 = new Thread(new_thread);
thread1.start();
System.out.println("线程2");
Thread thread2 = new Thread(new_thread);
thread2.start();
}
public static void main(String[] args) {
SynchronizedThread st = new SynchronizedThread();
st.useThread();
}
}3.使用特殊域变量(volatile)实现线程同步(提供了可见性)
a.volatile关键字为域变量的访问提供了一种免锁机制,
b.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新,
c.因此每次使用该域就要重新计算,而不是使用寄存器中的值
d.volatile不会提供任何原子操作,它也不能用来修饰final类型的变量
例如:
在上面的例子当中,只需在account前面加上volatile修饰,即可实现线程同步。
代码实例:
//只给出要修改的代码,其余代码与上同
class Bank {
//需要同步的变量加上volatile
private volatile int account = 100;
public int getAccount() {
return account;
}
//这里不再需要synchronized
public void save(int money) {
account += money;
}
}注:多线程中的非同步问题主要出现在对域的读写上,如果让域自身避免这个问题,则就不需要修改操作该域的方法。
用final域,有锁保护的域和volatile域可以避免非同步的问题。
4.使用重入锁实现线程同步
在JavaSE5.0中新增了一个java.util.concurrent包来支持同步。
ReentrantLock类是可重入、互斥、实现了Lock接口的锁,
它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力
ReenreantLock类的常用方法有:
ReentrantLock() : 创建一个ReentrantLock实例
lock() : 获得锁
unlock() : 释放锁
注:ReentrantLock()还有一个可以创建公平锁的构造方法,但由于能大幅度降低程序运行效率,不推荐使用
例如:
在上面例子的基础上,改写后的代码为:
代码实例:
//只给出要修改的代码,其余代码与上同
class Bank {
private int account = 100;
//需要声明这个锁
private Lock lock = new ReentrantLock();
public int getAccount() {
return account;
}
//这里不再需要synchronized
public void save(int money) {
lock.lock();
try{
account += money;
}finally{
lock.unlock();
}
}
}注:关于Lock对象和synchronized关键字的选择:
a.最好两个都不用,使用一种java.util.concurrent包提供的机制, 能够帮助用户处理所有与锁相关的代码。
b.如果synchronized关键字能满足用户的需求,就用synchronized,因为它能简化代码
c.如果需要更高级的功能,就用ReentrantLock类,此时要注意及时释放锁,否则会出现死锁,通常在finally代码释放锁
5.使用局部变量实现线程同步
如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
ThreadLocal 类的常用方法
ThreadLocal() : 创建一个线程本地变量
get() : 返回此线程局部变量的当前线程副本中的值
initialValue() : 返回此线程局部变量的当前线程的"初始值"
set(T value) : 将此线程局部变量的当前线程副本中的值设置为value
例如:
在上面例子基础上,修改后的代码为:
代码实例:
/只改Bank类,其余代码与上同
public class Bank{
//使用ThreadLocal类管理共享变量account
private static ThreadLocal<Integer> account = new ThreadLocal<Integer>(){
@Override
protected Integer initialValue(){
return 100;
}
};
public void save(int money){
account.set(account.get()+money);
}
public int getAccount(){
return account.get();
}
} 注:ThreadLocal与同步机制 a.ThreadLocal与同步机制都是为了解决多线程中相同变量的访问冲突问题。
b.前者采用以"空间换时间"的方法,后者采用以"时间换空间"的方式
2.HashMap的实现原理
1. HashMap概述:
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
2. HashMap的数据结构:
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
从上图中可以看出,HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
……
}可以看出,Entry就是数组中的元素,每个 Map.Entry 其实就是一个key-value对,它持有一个指向下一个元素的引用,这就构成了链表。3. HashMap的存取实现:
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return nul
126f7
l;
}从上面的源代码中可以看出:当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
4.HashMap、HashTable的区别,以及ConcurrentHashMap的了解
HashTable的应用非常广泛,HashMap是新框架中用来代替HashTable的类,也就是说建议使用HashMap,不要使用HashTable。
1.HashTable的方法是同步的,HashMap未经同步,所以在多线程场合要手动同步HashMap这个区别就像Vector和ArrayList一样。
2.HashTable不允许null值(key和value都不可以),HashMap允许null值(key和value都可以)。
3.HashTable有一个contains(Object value),功能和containsValue(Object value)功能一样。
4.HashTable使用Enumeration,HashMap使用Iterator。 以上只是表面的不同,它们的实现也有很大的不同。
5.HashTable中hash数组默认大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
6.哈希值的使用不同,HashTable直接使用对象的hashCode,而HashMap重新计算hash值,而且用与代替求模。
HashMap不是线程安全的,因此多线程操作时需要格外小心。在JDK1.5中,伟大的Doug Lea给我们带来了concurrent包,从此Map也有安全的ConcurrentHashMap。
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
5.java的内存回收机制以及类的加载机制
在Java中,当没有对象引用指向原先分配给某个对象的内存时,该内存便成为垃圾。JVM的一个系统级线程会自动释放该内存块。垃圾收集意味着程序不再需要的对象是"无用信息",这些信息将被丢弃。当一个对象不再被引用的时候,内存回收它占领的空间,以便空间被后来的新对象使用。事实上,除了释放没用的对象,垃圾收集也可以清除内存记录碎片。由于创建对象和垃圾收集器释放丢弃对象所占的内存空间,内存会出现碎片。碎片是分配给对象的内存块之间的空闲内存洞。碎片整理将所占用的堆内存移到堆的一端,JVM将整理出的内存分配给新的对象。
垃圾收集能自动释放内存空间,减轻编程的负担。这使Java 虚拟机具有一些优点。首先,它能使编程效率提高。在没有垃圾收集机制的时候,可能要花许多时间来解决一个难懂的存储器问题。在用Java语言编程的时候,靠垃圾收集机制可大大缩短时间。其次是它保护程序的完整性, 垃圾收集是Java语言安全性策略的一个重要部份。
垃圾收集的算法分析
Java语言规范没有明确地说明JVM使用哪种垃圾回收算法,但是任何一种垃圾收集算法一般要做2件基本的事情:(1)发现无用信息对象;(2)回收被无用对象占用的内存空间,使该空间可被程序再次使用。
大多数垃圾回收算法使用了根集(root set)这个概念;所谓根集就量正在执行的Java程序可以访问的引用变量的集合(包括局部变量、参数、类变量),程序可以使用引用变量访问对象的属性和调用对象的方法。垃圾收集首选需要确定从根开始哪些是可达的和哪些是不可达的,从根集可达的对象都是活动对象,它们不能作为垃圾被回收,这也包括从根集间接可达的对象。而根集通过任意路径不可达的对象符合垃圾收集的条件,应该被回收。下面介绍几个常用的算法。
1、 引用计数法(Reference Counting Collector)
引用计数法是唯一没有使用根集的垃圾回收的法,该算法使用引用计数器来区分存活对象和不再使用的对象。一般来说,堆中的每个对象对应一个引用计数器。当每一次创建一个对象并赋给一个变量时,引用计数器置为1。当对象被赋给任意变量时,引用计数器每次加1当对象出了作用域后(该对象丢弃不再使用),引用计数器减1,一旦引用计数器为0,对象就满足了垃圾收集的条件。
基于引用计数器的垃圾收集器运行较快,不会长时间中断程序执行,适宜地必须 实时运行的程序。但引用计数器增加了程序执行的开销,因为每次对象赋给新的变量,计数器加1,而每次现有对象出了作用域生,计数器减1。
2、tracing算法(Tracing Collector)
tracing算法是为了解决引用计数法的问题而提出,它使用了根集的概念。基于tracing算法的垃圾收集器从根集开始扫描,识别出哪些对象可达,哪些对象不可达,并用某种方式标记可达对象,例如对每个可达对象设置一个或多个位。在扫描识别过程中,基于tracing算法的垃圾收集也称为标记和清除(mark-and-sweep)垃圾收集器.
3、compacting算法(Compacting Collector)
为了解决堆碎片问题,基于tracing的垃圾回收吸收了Compacting算法的思想,在清除的过程中,算法将所有的对象移到堆的一端,堆的另一端就变成了一个相邻的空闲内存区,收集器会对它移动的所有对象的所有引用进行更新,使得这些引用在新的位置能识别原来 的对象。在基于Compacting算法的收集器的实现中,一般增加句柄和句柄表。
4、copying算法(Coping Collector)
该算法的提出是为了克服句柄的开销和解决堆碎片的垃圾回收。它开始时把堆分成 一个对象 面和多个空闲面, 程序从对象面为对象分配空间,当对象满了,基于coping算法的垃圾 收集就从根集中扫描活动对象,并将每个 活动对象复制到空闲面(使得活动对象所占的内存之间没有空闲洞),这样空闲面变成了对象面,原来的对象面变成了空闲面,程序会在新的对象面中分配内存。
一种典型的基于coping算法的垃圾回收是stop-and-copy算法,它将堆分成对象面和空闲区域面,在对象面与空闲区域面的切换过程中,程序暂停执行。
5、generation算法(Generational Collector)
stop-and-copy垃圾收集器的一个缺陷是收集器必须复制所有的活动对象,这增加了程序等待时间,这是coping算法低效的原因。在程序设计中有这样的规律:多数对象存在的时间比较短,少数的存在时间比较长。因此,generation算法将堆分成两个或多个,每个子堆作为对象的一代(generation)。由于多数对象存在的时间比较短,随着程序丢弃不使用的对象,垃圾收集器将从最年轻的子堆中收集这些对象。在分代式的垃圾收集器运行后,上次运行存活下来的对象移到下一最高代的子堆中,由于老一代的子堆不会经常被回收,因而节省了时间。
6、adaptive算法(Adaptive Collector)
在特定的情况下,一些垃圾收集算法会优于其它算法。基于Adaptive算法的垃圾收集器就是监控当前堆的使用情况,并将选择适当算法的垃圾收集器。
类加载机制
JVM的类加载是通过ClassLoader及其子类来完成的,类的层次关系和加载顺序可以由下图来描述:
1)Bootstrap ClassLoader
负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类
2)Extension ClassLoader
负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包
3)App ClassLoader
负责记载classpath中指定的jar包及目录中class
4)Custom ClassLoader
属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个classloader已加载就视为已加载此类,保证此类只所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
6.如何判断两个链表相交?
采用快慢指针方法,遍历两个表分别知道两个表的长度a, b。然后让长表先走|a-b|步后,短表再开始走,直到相同。时间复杂度为o(m+n),具体的解决思路,可以看看这篇文章判断两个链表是否相交并找出交点
在写作本篇博客的时候,借鉴了很多同行的博客,在此感谢zhangshixi,xuefeng0707,小小中,南蛮虫等
我是kris,See you next time!!!
java笔记--关于线程同步(5种同步方式)
深入Java集合学习系列:HashMap的实现原理 (zhangshixi)
HashMap与ConcurrentHashMap的区别 (xuefeng0707)
HashTable 和 HashMap 的区别 (小小中)
java内存回收机制 (南蛮虫)
JVM原理讲解和调优

相关文章推荐
- Android面试题详细整理系列(二)
- Android面试题详细整理系列(一)
- 常见Android面试题及答案(详细整理)
- 常见Android面试题及答案(详细整理)
- 2011Android技术面试整理附有详细答案(包括百度、新浪、中科软等多家公司笔试面试题)
- 常见Android面试题及答案(详细整理)
- 常见Android面试题及答案(详细整理)
- 常见Android面试题及答案(详细整理)
- 常见Android面试题及答案(详细整理)
- 2011Android技术面试整理附有详细答案(包括百度、新浪、中科软等多家公司笔试面试题)
- 常见Android面试题及答案(详细整理)
- 2011Android技术面试整理附有详细答案(包括百度、新浪、中科软等多家公司笔试面试题)
- 常见Android面试题及答案(详细整理)
- Android面试题及答案(详细整理)
- 常见Android面试题及答案(详细整理)
- 常见Android面试题及答案(详细整理)
- 2011Android技术面试整理附有详细答案(包括百度、新浪、中科软等多家公司笔试面试题)
- android中service和aidl详细整理
- android中service和aidl详细整理
- [分类整理IV]微软等100题系列V0.1版:字符串+数组面试题集锦