Spark RDDs vs DataFrames vs SparkSQL
2017-02-14 15:54
381 查看
简介
Spark的 RDD、DataFrame 和 SparkSQL的性能比较。
2方面的比较
单条记录的随机查找
aggregation聚合并且sorting后输出
使用以下Spark的三种方式来解决上面的2个问题,对比性能。
Using RDD’s
Using DataFrames
Using SparkSQL
数据源
在HDFS中3个文件中存储的9百万不同记录
每条记录11个字段
总大小 1.4 GB
实验环境
HDP 2.4
Hadoop version 2.7
Spark 1.6
HDP Sandbox
测试结果
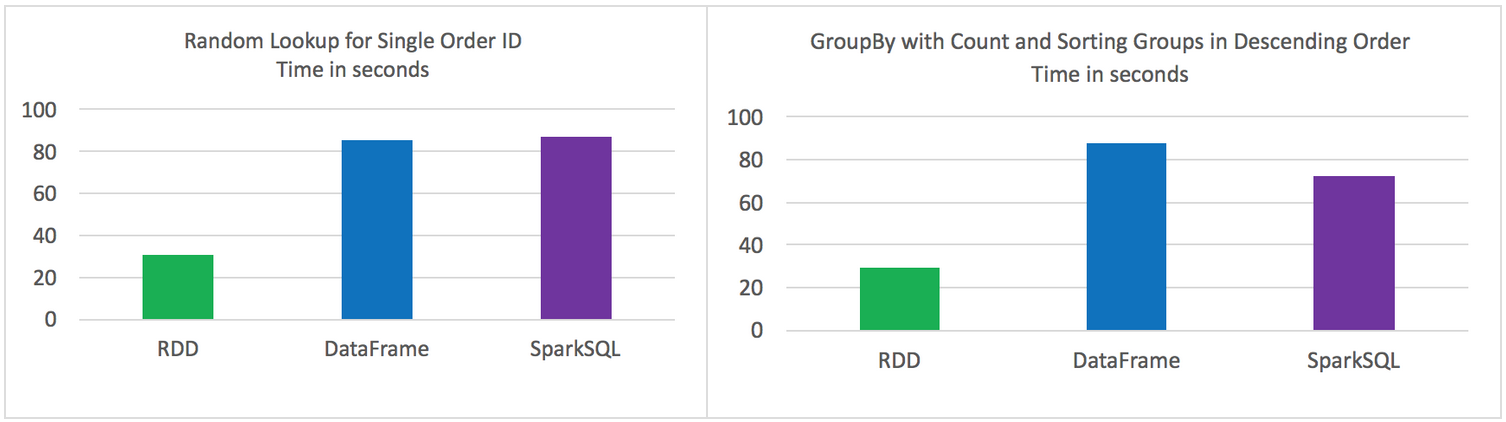
原始的RDD 比 DataFrames 和 SparkSQL性能要好
DataFrames 和 SparkSQL 性能差不多
使用DataFrames 和 SparkSQL 比 RDD 操作更直观
Jobs都是独立运行,没有其他job的干扰
2个操作
Random lookup against 1 order ID from 9 Million unique order ID's
GROUP all the different products with their total COUNTS and SORT DESCENDING by product name
代码
RDD Random Lookup
DataFrame Random Lookup
SparkSQL Random Lookup
RDD with GroupBy, Count, and Sort Descending
DataFrame with GroupBy, Count, and Sort Descending
SparkSQL with GroupBy, Count, and Sort Descending
原文:https://community.hortonworks.com/articles/42027/rdd-vs-dataframe-vs-sparksql.html
Spark的 RDD、DataFrame 和 SparkSQL的性能比较。
2方面的比较
单条记录的随机查找
aggregation聚合并且sorting后输出
使用以下Spark的三种方式来解决上面的2个问题,对比性能。
Using RDD’s
Using DataFrames
Using SparkSQL
数据源
在HDFS中3个文件中存储的9百万不同记录
每条记录11个字段
总大小 1.4 GB
实验环境
HDP 2.4
Hadoop version 2.7
Spark 1.6
HDP Sandbox
测试结果
原始的RDD 比 DataFrames 和 SparkSQL性能要好
DataFrames 和 SparkSQL 性能差不多
使用DataFrames 和 SparkSQL 比 RDD 操作更直观
Jobs都是独立运行,没有其他job的干扰
2个操作
Random lookup against 1 order ID from 9 Million unique order ID's
GROUP all the different products with their total COUNTS and SORT DESCENDING by product name
代码
RDD Random Lookup
#!/usr/bin/env python
from time import time
from pyspark import SparkConf, SparkContext
conf = (SparkConf()
.setAppName("rdd_random_lookup")
.set("spark.executor.instances", "10")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf)
t0 = time()
path = "/data/customer_orders*"
lines = sc.textFile(path)
## filter where the order_id, the second field, is equal to 96922894
print lines.map(lambda line: line.split('|')).filter(lambda line: int(line[1]) == 96922894).collect()
tt = str(time() - t0)
print "RDD lookup performed in " + tt + " seconds"DataFrame Random Lookup
#!/usr/bin/env python
from time import time
from pyspark.sql import *
from pyspark import SparkConf, SparkContext
conf = (SparkConf()
.setAppName("data_frame_random_lookup")
.set("spark.executor.instances", "10")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf)
sqlContext = SQLContext(sc)
t0 = time()
path = "/data/customer_orders*"
lines = sc.textFile(path)
## create data frame
orders_df = sqlContext.createDataFrame( \
lines.map(lambda l: l.split("|")) \
.map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \
country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) )
## filter where the order_id, the second field, is equal to 96922894
orders_df.where(orders_df['order_id'] == 96922894).show()
tt = str(time() - t0)
print "DataFrame performed in " + tt + " seconds"SparkSQL Random Lookup
#!/usr/bin/env python
from time import time
from pyspark.sql import *
from pyspark import SparkConf, SparkContext
conf = (SparkConf()
.setAppName("spark_sql_random_lookup")
.set("spark.executor.instances", "10")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf)
sqlContext = SQLContext(sc)
t0 = time()
path = "/data/customer_orders*"
lines = sc.textFile(path)
## create data frame
orders_df = sqlContext.createDataFrame( \
lines.map(lambda l: l.split("|")) \
.map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \
country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) )
## register data frame as a temporary table
orders_df.registerTempTable("orders")
## filter where the customer_id, the first field, is equal to 96922894
print sqlContext.sql("SELECT * FROM orders where order_id = 96922894").collect()
tt = str(time() - t0)
print "SparkSQL performed in " + tt + " seconds"RDD with GroupBy, Count, and Sort Descending
#!/usr/bin/env python
from time import time
from pyspark import SparkConf, SparkContext
conf = (SparkConf()
.setAppName("rdd_aggregation_and_sort")
.set("spark.executor.instances", "10")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf)
t0 = time()
path = "/data/customer_orders*"
lines = sc.textFile(path)
counts = lines.map(lambda line: line.split('|')) \
.map(lambda x: (x[5], 1)) \
.reduceByKey(lambda a, b: a + b) \
.map(lambda x:(x[1],x[0])) \
.sortByKey(ascending=False)
for x in counts.collect():
print x[1] + '\t' + str(x[0])
tt = str(time() - t0)
print "RDD GroupBy performed in " + tt + " seconds"DataFrame with GroupBy, Count, and Sort Descending
#!/usr/bin/env python
from time import time
from pyspark.sql import *
from pyspark import SparkConf, SparkContext
conf = (SparkConf()
.setAppName("data_frame_aggregation_and_sort")
.set("spark.executor.instances", "10")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf)
sqlContext = SQLContext(sc)
t0 = time()
path = "/data/customer_orders*"
lines = sc.textFile(path)
## create data frame
orders_df = sqlContext.createDataFrame( \
lines.map(lambda l: l.split("|")) \
.map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \
country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) )
results = orders_df.groupBy(orders_df['product_desc']).count().sort("count",ascending=False)
for x in results.collect():
print x
tt = str(time() - t0)
print "DataFrame performed in " + tt + " seconds"SparkSQL with GroupBy, Count, and Sort Descending
#!/usr/bin/env python
from time import time
from pyspark.sql import *
from pyspark import SparkConf, SparkContext
conf = (SparkConf()
.setAppName("spark_sql_aggregation_and_sort")
.set("spark.executor.instances", "10")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf)
sqlContext = SQLContext(sc)
t0 = time()
path = "/data/customer_orders*"
lines = sc.textFile(path)
## create data frame
orders_df = sqlContext.createDataFrame(lines.map(lambda l: l.split("|")) \
.map(lambda r: Row(product=r[5])))
## register data frame as a temporary table
orders_df.registerTempTable("orders")
results = sqlContext.sql("SELECT product, count(*) AS total_count FROM orders GROUP BY product ORDER BY total_count DESC")
for x in results.collect():
print x
tt = str(time() - t0)
print "SparkSQL performed in " + tt + " seconds"原文:https://community.hortonworks.com/articles/42027/rdd-vs-dataframe-vs-sparksql.html

相关文章推荐
- 2.sparkSQL--DataFrames与RDDs的相互转换
- Spark SQL and DataFrames
- Spark SQL, DataFrames and Datasets Guide
- Apache Spark 2.0中使用DataFrames和SQL
- Spark SQL, DataFrames and Datasets Guide
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
- Spark SQL,DataFrames and DataSets Guide官方文档翻译
- Spark SQL概述,DataFrames,创建DataFrames的案例,DataFrame常用操作(DSL风格语法),sql风格语法
- Spark SQL和DataFrames支持的数据格式
- Spark SQL and DataFrame Guide(1.4.1)——之DataFrames
- SPARK SQL - update MySql table using DataFrames and JDBC
- 【Spark 2.0官方文档】Spark SQL、DataFrames以及Datasets指南
- Spark SQL RDD与DataFrames相互转换
- Spark SQL, DataFrames 和 Datasets 指南
- 【Spark 2.0官方文档】Spark SQL、DataFrames以及Datasets指南
- SparkSQL(Spark-1.4.0)实战系列(一)——DataFrames基础
- Spark -9:Spark SQL, DataFrames and Datasets 编程指南
- 《Spark 官方文档》Spark SQL, DataFrames 以及 Datasets 编程指南
- 《Spark 官方文档》Spark SQL, DataFrames 以及 Datasets 编程指南
- Spark SQL and DataFrames Version 1.6