ELASTIC 5.2部署并收集nginx日志
2017-02-10 16:50
543 查看
elastic 5.2集群安装笔记
设计架构如下:
nginx_json_log -》filebeat -》logstash -》elasticsearch -》kibana
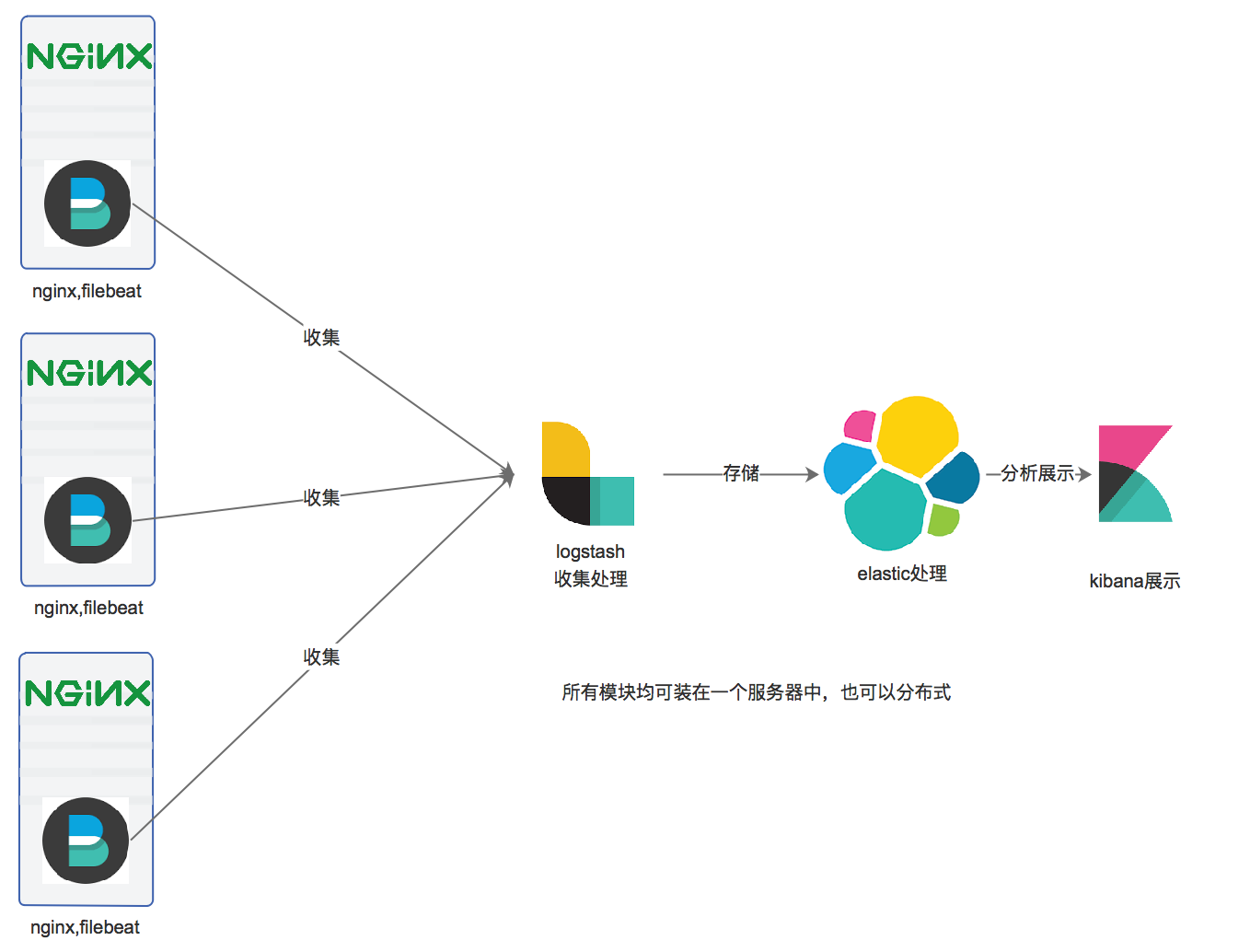
系统版本Centos7.2
nginx格式为json,如何定义为json请自行百度。
kibana展示如下

wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.2.0-x86_64.rpm
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.0.rpm
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.2.0-x86_64.rpm
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.2.0.rpm
rpm -ivh elasticsearch-5.2.0.rpm
rpm -ivh kibana-5.2.0-x86_64.rpm
rpm -ivh logstash-5.2.0.rpm
yum install java-1.8.0-openjdk -y #logstash 和 elasticsearch启动需要jdk1.8以上版本,推荐使用oracle的jdk。
ES启动前系统调试
关闭ESlinux
暂时关闭iptables
修改IO调度算法为noop #不是SSD不用调整
cat /sys/block/sda/queue/scheduler
noop deadline [cfq](默认是cfq)
echo "noop" >/sys/block/sda/queue/scheduler
cat /sys/block/sda/queue/scheduler
[noop] deadline cfq(变为noop)
#增大文件描述符
ulimit -n 65536
echo -ne "
* soft nofile 65536
* hard nofile 65536
" >>/etc/security/limits.conf
#修改系统线程限制
echo -ne "
* soft nproc 2048
* hard nproc 4096
" >>/etc/security/limits.conf
修改系统限制一个进程可以拥有的VMA(虚拟内存区域)的数量
若无参数请增加
vim /etc/sysctl.conf
vm.max_map_count = 262144
设置降低交换分区的使用优先级
vim /etc/sysctl.conf
vm.swappiness = 1
ES启动前elasticsearch.yml配置
cat /etc/elasticsearch/jvm.options
-Xms16g
-Xmx16g
注:按需调整,配置物理机内存的50%,但不要超过31G。
cat /etc/elasticsearch/elasticsearch.yml
#集群名称
cluster.name: ESTACK
#节点名称
node.name: ESTACK01
#数据路径
path.data: /opt/elk/elasticsearch-data/
#若有交换分区,请开启此项配置(我的服务器没有交换分区,故没有打开)
#禁用swap内存交换
##若开启此选项,你需要修改/usr/lib/systemd/system/elasticsearch.service文件,并设置LimitMEMLOCK=infinity,
##修改/etc/sysconfig/elasticsearch文件,设置MAX_LOCKED_MEMORY=unlimited,最后执行systemctl daemon-reloa & systemctl restart elasticsearch
#bootstrap.memory_lock: true
#监听地址
network.host: 10.1.74.53
#最小成集群节点数,防止脑裂
discovery.zen.minimum_master_nodes: 2
#单播ES节点地址。
discovery.zen.ping.unicast.hosts:
- 10.1.73.229
- 10.1.74.53
- 10.1.74.54
配置完毕启动即可 systemctl start elasticsearch
logstash安装与使用
安装包完毕后,将配置文件放入目录
/etc/logstash/conf.d 下
配置文件举例
cdnlogs.conf
input {
beats {
port => 5044
}
}
filter{
json{
source => "message"
}
geoip {
source => "ip"
#geoip是从IP字段中,获取IP地址,并匹配这个地址的地方,最后生成地区的索引和坐标新增到ES的数据中。
#logstash5x以上的geoip库已直接集成在logstash中,2.x需要单独指定,建议直接用logstash5x以上版本
target => "geoip"
}
}
output {
elasticsearch {
hosts => "10.1.74.53:9200"
manage_template => false
index => "cdnlogs-%{+YYYY.MM}"
document_type => "cdnlogs"
}
}
启动logstash
screen -S logstash
screen这个命令请先百度学习一下。
./bin/logstash -f routerlogs.conf
启动后的logstash会监听5044端口,beats发送过来的数据会被logstash进行接收,处理(geoip增加访问用户的地址)和输出到elasticsearch中。
配置kibana
主要配置
vim /etc/kibana/kibana.yml
#server.port: 5601
#server.host: "127.0.0.1"
#elasticsearch.url: "http://127.0.0.1:9200"
配置完毕后启动即可 systemctl start kibana
配置filebeat
在需要收集日志的服务器上安装filebeat
注意,收集的日志必须为json格式!
安装完毕后修改配置文件
vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
# Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations.
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/cdn.log
json.keys_under_root: true
output.logstash:
# The Logstash hosts
hosts: ["42.15.38.132:5044"]
配置完毕启动即可,
至此,日志会经过
filebeat -》logstash -》 elasticsearch -》kibana 展示到你的面前,祝玩的愉快。

设计架构如下:
nginx_json_log -》filebeat -》logstash -》elasticsearch -》kibana
系统版本Centos7.2
nginx格式为json,如何定义为json请自行百度。
kibana展示如下
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.2.0-x86_64.rpm
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.0.rpm
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.2.0-x86_64.rpm
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.2.0.rpm
rpm -ivh elasticsearch-5.2.0.rpm
rpm -ivh kibana-5.2.0-x86_64.rpm
rpm -ivh logstash-5.2.0.rpm
yum install java-1.8.0-openjdk -y #logstash 和 elasticsearch启动需要jdk1.8以上版本,推荐使用oracle的jdk。
ES启动前系统调试
关闭ESlinux
暂时关闭iptables
修改IO调度算法为noop #不是SSD不用调整
cat /sys/block/sda/queue/scheduler
noop deadline [cfq](默认是cfq)
echo "noop" >/sys/block/sda/queue/scheduler
cat /sys/block/sda/queue/scheduler
[noop] deadline cfq(变为noop)
#增大文件描述符
ulimit -n 65536
echo -ne "
* soft nofile 65536
* hard nofile 65536
" >>/etc/security/limits.conf
#修改系统线程限制
echo -ne "
* soft nproc 2048
* hard nproc 4096
" >>/etc/security/limits.conf
修改系统限制一个进程可以拥有的VMA(虚拟内存区域)的数量
若无参数请增加
vim /etc/sysctl.conf
vm.max_map_count = 262144
设置降低交换分区的使用优先级
vim /etc/sysctl.conf
vm.swappiness = 1
ES启动前elasticsearch.yml配置
cat /etc/elasticsearch/jvm.options
-Xms16g
-Xmx16g
注:按需调整,配置物理机内存的50%,但不要超过31G。
cat /etc/elasticsearch/elasticsearch.yml
#集群名称
cluster.name: ESTACK
#节点名称
node.name: ESTACK01
#数据路径
path.data: /opt/elk/elasticsearch-data/
#若有交换分区,请开启此项配置(我的服务器没有交换分区,故没有打开)
#禁用swap内存交换
##若开启此选项,你需要修改/usr/lib/systemd/system/elasticsearch.service文件,并设置LimitMEMLOCK=infinity,
##修改/etc/sysconfig/elasticsearch文件,设置MAX_LOCKED_MEMORY=unlimited,最后执行systemctl daemon-reloa & systemctl restart elasticsearch
#bootstrap.memory_lock: true
#监听地址
network.host: 10.1.74.53
#最小成集群节点数,防止脑裂
discovery.zen.minimum_master_nodes: 2
#单播ES节点地址。
discovery.zen.ping.unicast.hosts:
- 10.1.73.229
- 10.1.74.53
- 10.1.74.54
配置完毕启动即可 systemctl start elasticsearch
logstash安装与使用
安装包完毕后,将配置文件放入目录
/etc/logstash/conf.d 下
配置文件举例
cdnlogs.conf
input {
beats {
port => 5044
}
}
filter{
json{
source => "message"
}
geoip {
source => "ip"
#geoip是从IP字段中,获取IP地址,并匹配这个地址的地方,最后生成地区的索引和坐标新增到ES的数据中。
#logstash5x以上的geoip库已直接集成在logstash中,2.x需要单独指定,建议直接用logstash5x以上版本
target => "geoip"
}
}
output {
elasticsearch {
hosts => "10.1.74.53:9200"
manage_template => false
index => "cdnlogs-%{+YYYY.MM}"
document_type => "cdnlogs"
}
}
启动logstash
screen -S logstash
screen这个命令请先百度学习一下。
./bin/logstash -f routerlogs.conf
启动后的logstash会监听5044端口,beats发送过来的数据会被logstash进行接收,处理(geoip增加访问用户的地址)和输出到elasticsearch中。
配置kibana
主要配置
vim /etc/kibana/kibana.yml
#server.port: 5601
#server.host: "127.0.0.1"
#elasticsearch.url: "http://127.0.0.1:9200"
配置完毕后启动即可 systemctl start kibana
配置filebeat
在需要收集日志的服务器上安装filebeat
注意,收集的日志必须为json格式!
安装完毕后修改配置文件
vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
# Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations.
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/cdn.log
json.keys_under_root: true
output.logstash:
# The Logstash hosts
hosts: ["42.15.38.132:5044"]
配置完毕启动即可,
至此,日志会经过
filebeat -》logstash -》 elasticsearch -》kibana 展示到你的面前,祝玩的愉快。
谢土豪
如果有帮到你的话,请赞赏我吧!

相关文章推荐
- CentOS_6.5安装Nginx+PHP+MySQL
- centos7编译安装nginx
- nginx 静态目录配置规则
- WNMP(Windows + Nginx + PHP + MySQL) 安装
- nginx防盗链设置
- nginx css或js无法加载的问题
- 取消nginx对js css文件的缓存
- 【thinkphp 5 在nginx 环境下路由无法生效(404 500错误 )的解决方法】
- zabbix监控nginx性能状态
- salt部署nginx
- [nginx] 脚本引擎
- Nginx的Tornado的配置
- Nginx配置
- nginx 日志清理
- 借助LANMT构架,简析ngnix的使用
- 浅谈一个网页打开的全过程(涉及DNS、CDN、Nginx负载均衡等)
- 让nginx 支持pathinfo
- Linux下Nginx快捷启动关闭设置
- 图片服务器搭建
- nginx安装与配置