反反爬虫策略
2017-02-03 00:00
204 查看
爬虫,反爬虫,反反爬虫之间斗争恢弘壮阔!爬虫大量爬取网站上数据会对服务器的带宽,计算能力等资源占用,同时网站所有者不大乐意自己网站数据被他人随意收集,必然会对爬虫进行限制。反爬虫最常见策略是限制IP,这篇博客主要描述如何应对限制IP和其他反爬虫策略。
一.对请求IP等进行限制的。
以知乎为例,当我们的请求速度到达一定的阈值,会触发反爬虫机制!
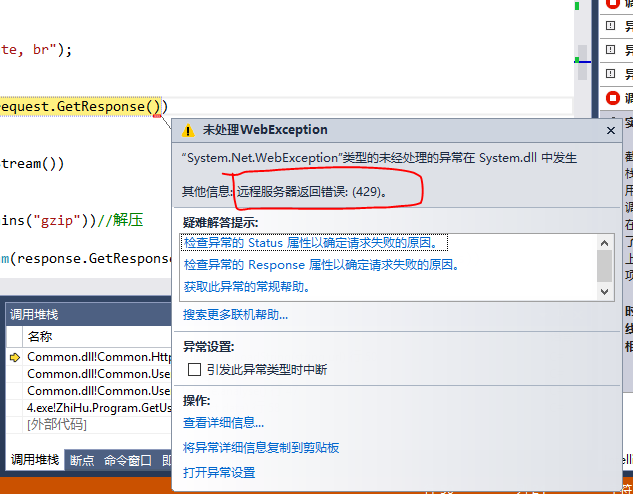
在我爬取知乎百万用户信息中,出现了429错误(
应对策略.
1.降低爬虫采集速率,使速率略低于阈值
进行测试,侦探出阈值。
开启6个线程抓取时,服务器返回429
开启5个线程时,运行良好,没有遭到阻碍
所以,如果任务量比较小可以采取这种策略进行
2.建立代理池
httpwebrequest挂代理很简单

详细请见我的博客http://www.cnblogs.com/zuin/p/6261677.html
每次请求都在代理池中随机获取一个代理,这样就不会达到阈值了。缺点是网上收集代理有效率很低,随时都可能无法使用。
3。使用云代理服务
服务商的代理稳定,高质量。以阿布云为例
将资源下载进行修改即可
其他:根据友军情报,服务器可能不是对IP进行限制,而是对账户进行限制,及时使用代理每次请求都是同一账户,如果对账户进行限制,可以申请大量账户,建立cookie池,每次请求都随机获取一个cookie,保证低于阈值。除了cookie池还有useragent池,根据情况建立。
二.对参数进行加密
现代web应用富AJAX,如果是想要数据包含在ajax中,直接分析ajax返回数据就可以了,但是人家可没有那么容易让你的手
看看网易云音乐
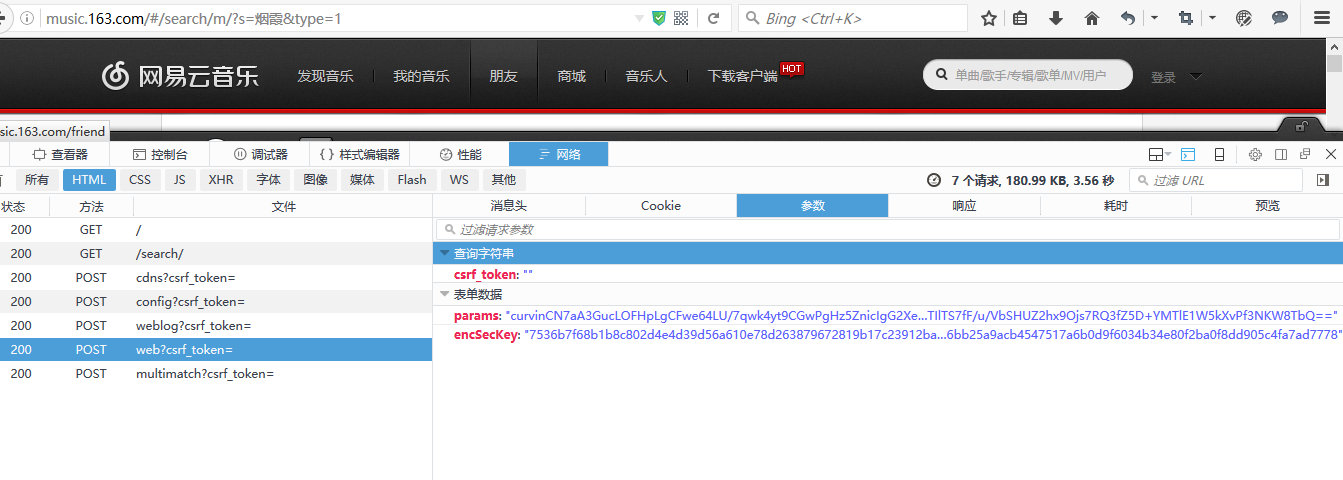
网易对参数进行了加密,想破解加密算法可行性太低,对于这种参数加密,采取在应用中内嵌浏览器。
采用的是 WebBrowser
引入命名空间
封装好下载页面方法
做个测试 按单曲搜索下“烟霞”
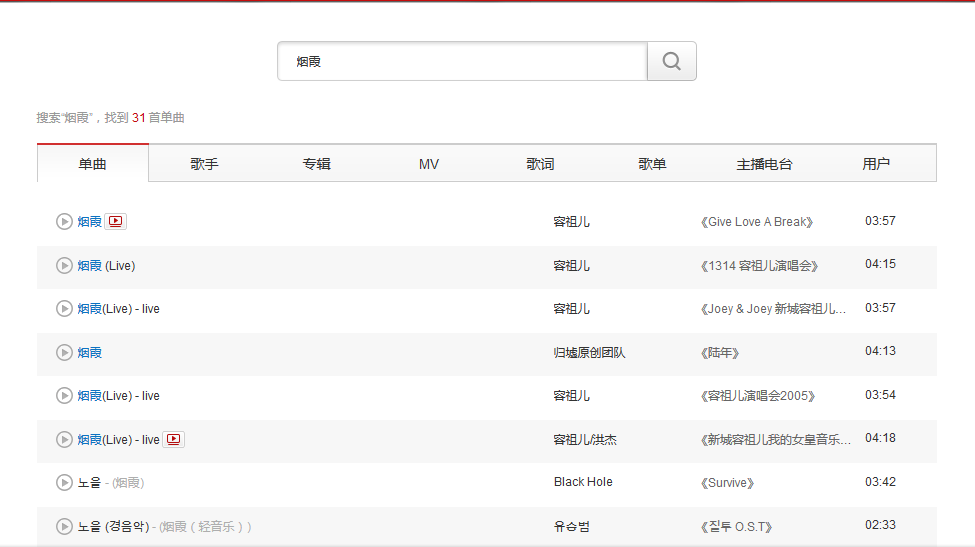
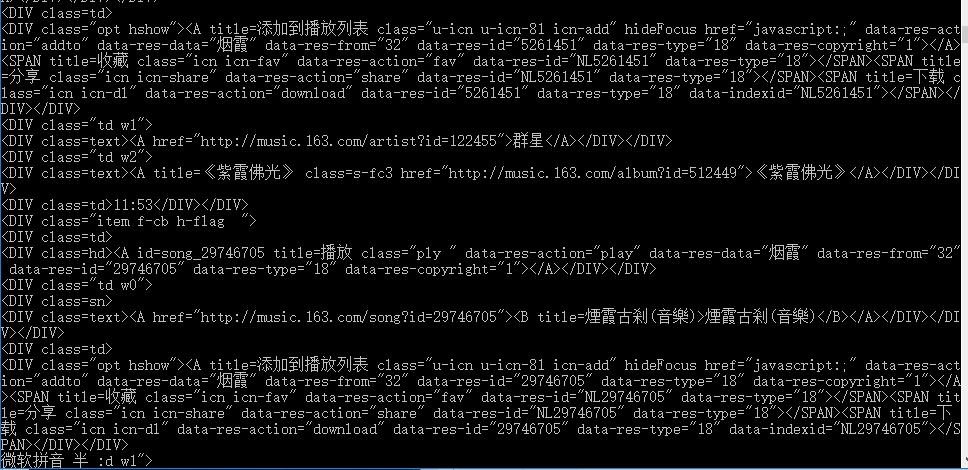
这样我们就拿到了搜索数据
更多博客:https://www.cnblogs.com/zuin
,
一.对请求IP等进行限制的。
以知乎为例,当我们的请求速度到达一定的阈值,会触发反爬虫机制!
在我爬取知乎百万用户信息中,出现了429错误(
Too Many Requests) 详情请见我的博客http://www.cnblogs.com/zuin/p/6227834.html
应对策略.
1.降低爬虫采集速率,使速率略低于阈值
进行测试,侦探出阈值。
开启6个线程抓取时,服务器返回429
for (int i = 0; i < 6; i++) { ThreadPool.QueueUserWorkItem(GetUser); }开启5个线程时,运行良好,没有遭到阻碍
for (int i = 0; i < 6; i++) { ThreadPool.QueueUserWorkItem(GetUser); }所以,如果任务量比较小可以采取这种策略进行
2.建立代理池
httpwebrequest挂代理很简单
详细请见我的博客http://www.cnblogs.com/zuin/p/6261677.html
每次请求都在代理池中随机获取一个代理,这样就不会达到阈值了。缺点是网上收集代理有效率很低,随时都可能无法使用。
3。使用云代理服务
服务商的代理稳定,高质量。以阿布云为例
将资源下载进行修改即可
public static string DownLoadString(string url)
{
string Source = string.Empty;
try
{
string proxyHost = "http://proxy.abuyun.com";
string proxyPort = "9020";
// 代理隧道验证信息
string proxyUser = "H71T6AMK7GRE";
string proxyPass = "D3F01F";
var proxy = new WebProxy();
proxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
proxy.Credentials = new NetworkCredential(proxyUser, proxyPass);
ServicePointManager.Expect100Continue = false;
Stopwatch watch = new Stopwatch();
watch.Start();
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0";
request.Accept = "*/*";
request.Method = "GET";
request.Referer = "https://www.zhihu.com/";
request.Headers.Add("Accept-Encoding", " gzip, deflate, br");
request.KeepAlive = true;//启用长连接
request.Proxy = proxy;
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream dataStream = response.GetResponseStream())
{
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
}
}
request.Abort();
watch.Stop();
Console.WriteLine("请求网页用了{0}毫秒", watch.ElapsedMilliseconds.ToString());
}
catch
{
Console.WriteLine("出错了,请求的URL为{0}", url);
}
return Source;
}其他:根据友军情报,服务器可能不是对IP进行限制,而是对账户进行限制,及时使用代理每次请求都是同一账户,如果对账户进行限制,可以申请大量账户,建立cookie池,每次请求都随机获取一个cookie,保证低于阈值。除了cookie池还有useragent池,根据情况建立。
二.对参数进行加密
现代web应用富AJAX,如果是想要数据包含在ajax中,直接分析ajax返回数据就可以了,但是人家可没有那么容易让你的手
看看网易云音乐
网易对参数进行了加密,想破解加密算法可行性太低,对于这种参数加密,采取在应用中内嵌浏览器。
采用的是 WebBrowser
引入命名空间
using System.Windows.Forms;
封装好下载页面方法
private static string htmlstr; private static void GetHtmlWithBrowser(object url) { htmlstr = string.Empty; using(WebBrowser wb = new WebBrowser()) { wb.AllowNavigation = true; wb.Url = new Uri(url.ToString()); while (wb.ReadyState != WebBrowserReadyState.Complete) { Application.DoEvents(); } if (wb.ReadyState == WebBrowserReadyState.Complete) { HtmlDocument doc = wb.Document; htmlstr = doc.Window.Frames[0].Document.Body.InnerHtml; Console.WriteLine(htmlstr); } } }做个测试 按单曲搜索下“烟霞”
这样我们就拿到了搜索数据
更多博客:https://www.cnblogs.com/zuin
,
