初等数据结构之链表
2017-01-26 15:04
141 查看
今天介绍一个非常简单的数据结构--链表,对于很多人这时一种非常易理解的数据结构。
顾名思义,这种数据结构的特点就是每个元素之间被一条条的链子关联着,就像铁链一样。
在这条链条上的每个铁环我们成为“结点”,而每个铁环之间的挂钩我们使用“指针来实现”。链表这种数据结构有好几种形式,像单向不循环链表,单向循环链表,双向循环链表等等,这里我们就介绍其中最复杂的双向循环链表,其包含了其它几种形式链表的所有知识点。
链表中的每个结点,我们使用C++中的结构体来实现,并将节点元素值和”铁环"之间关联的指正都整合在结构体中。结点的图示如下:
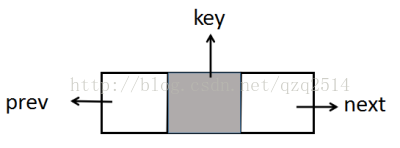
其中key表示该节点存放的值,prev指向前一个节点,next指向后一个结点。其代码如下:
struct Node{
int key;
Node *next,*prev;
};
接下来我们的目的就是将每个节点给连起来,而对于一开始初始化我们使用一个特殊的结点nil,称为"头结点",头结点中不存放数据,即没有key值,只是为了便于对链表进行增删操作而增加的一个特殊结点,在链表建立初期,我们的链表中只有一个头结点,其prev和next都指向自己,初始化代码如下:
Node *nil;
void init()
{
nil=(Node *)malloc(sizeof(Node)); //malloc是C语言中的标准库中的函数,用于动态申请置顶大小的内存空间
nil->next=nil;
nil->prev=nil;
}对于一个数据结构,其最基本的就是能对存放的数据进行增删和查找操作,接下来将一一介绍。
1.遍历查找。
在已有的链表中我们就通过简单的循环遍历进行查找,并通过结点之间的指针由当前结点转移到下一个结点,我们用一个临时的结点指针cur,初始化指向头结点的下一个结点,因为头结点并不存放真正的数据。以下是查找的代码:Node* listSearch(int key)
{
Node *cur=nil->next;
while(cur!=nil && cur->key!=key)
cur=cur->next;
return cur;
}2.增加元素
链表的增加元素有头插法和尾差法,其内部的实现原理是一样的,我们就通过头插法来实现插入元素,其实插入结点就是要将其前后结点和其自己的连接关系搞清楚就行,以下是我从《挑战》书上截取的插入步骤的图例:
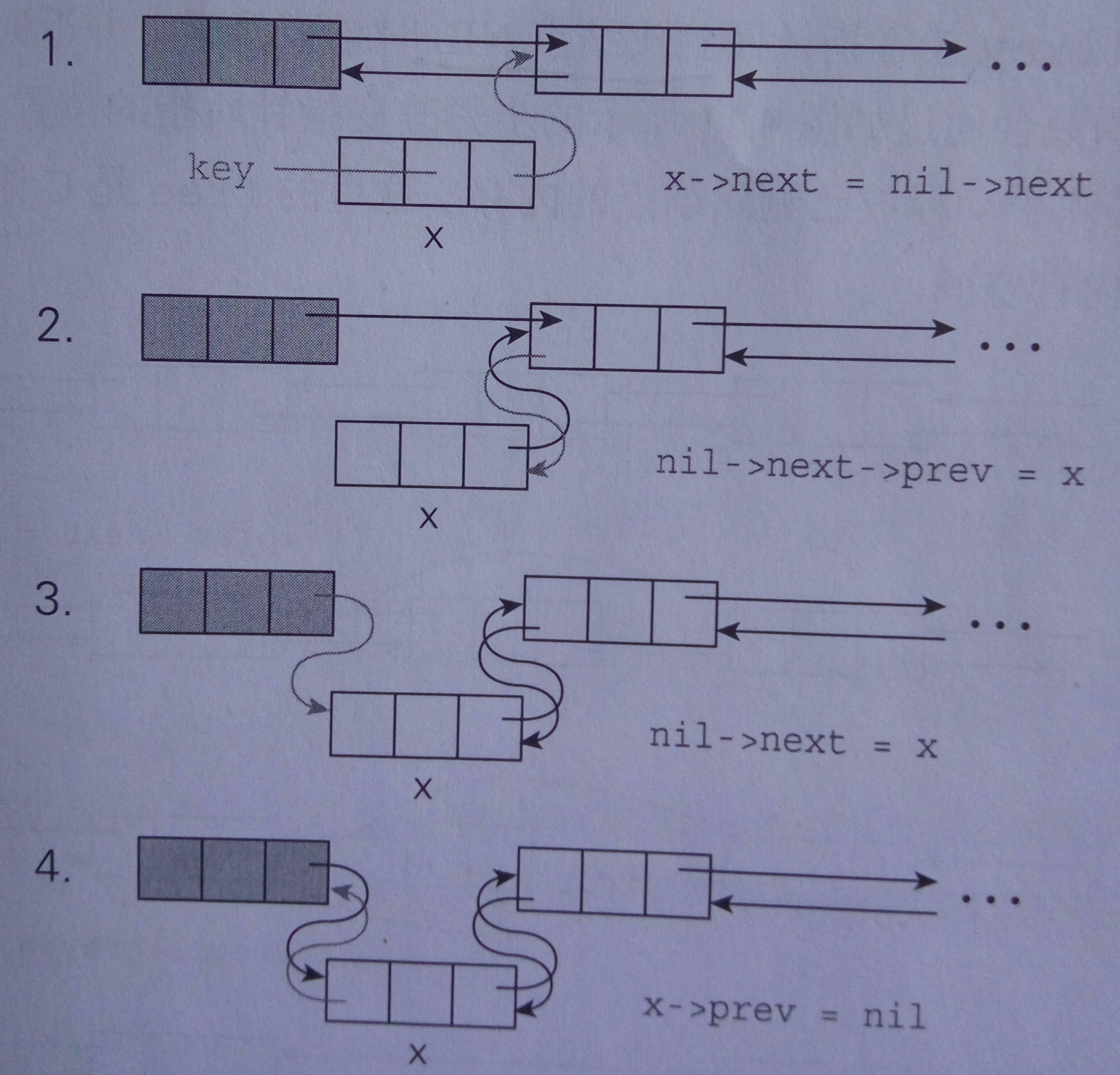
以下是插入的代码:void insert(int key)
{
Node *x=(Node *)malloc(sizeof(Node));
x->key=key;
x->next=nil->next;
nil->next->prev=x;
nil->next=x;
x->prev=nil;
}3.删除元素。
和插入元素,删除结点其实就是删除待删除结点与其前后结点的连接,以下同样是从《t挑战》书上截取而来:
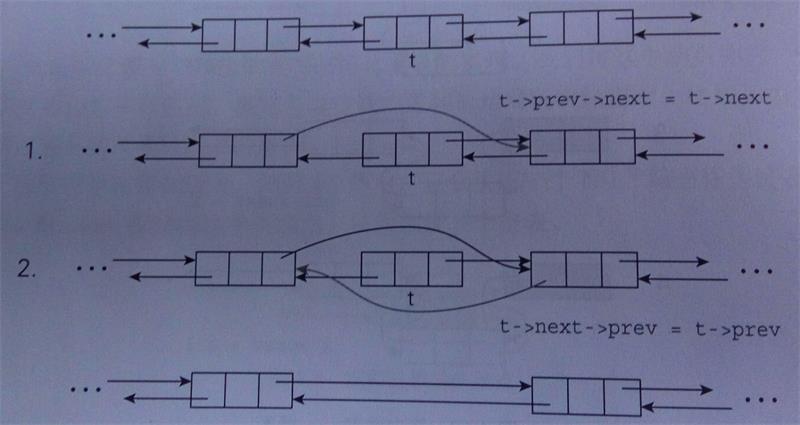
以下代码包括删除第一个包含有效值的结点,即头结点后的第一个结点,还有通过比对值来删除指定的结点,最后还有删除最后一个结点:
void deleteNode(Node *t)
{
if(t==nil) return ;
t->next->prev=t->prev;
t->prev->next=t->next;
free(t); //free是C语言中的标准库中的函数,用于动释放不需要的内存空间
}
void deleteFirst()
{
deleteNode(nil->next);
}
void deleteLast()
{
deleteNode(nil->prev);
}
void deleteByKey(int key)
{
//先按值找到待删除的节点,然后删除
deleteNode(listSearch(key));
}其实这里删除最后一个结点就已经体现了双向循环链表的好处了,直接通过头结点的前一个结点就找到了最后一个结点,即nil->prev就是最后呢一个结点,而对于其他形式的链表,,都必须从头结点一个一个结点的遍历,知道遍历到最后一个结点,才能进行删除~
以下则是C++实现双向循环链表的全部源代码:#include<cstdio>
#include<cstdlib>
#include<cstring>
struct Node{
int key;
Node *next,*prev;
};
Node *nil;
Node* listSearch(int key)
{
Node *cur=nil->next;
while(cur!=nil && cur->key!=key)
cur=cur->next;
return cur;
}
void init()
{
nil=(Node *)malloc(sizeof(Node)); //malloc是C语言中的标准库中的函数,用于动态申请置顶大小的内存空间
nil->next=nil;
nil->prev=nil;
}
void printList()
{
Node *cur=nil->next;
int isf=0;
while(cur!=nil)
{
if(isf++>0) printf(" ");
printf("%d",cur->key);
cur=cur->next;
}
printf("\n");
}
void deleteNode(Node *t)
{
if(t==nil) return ;
t->next->prev=t->prev;
t->prev->next=t->next;
free(t); //free是C语言中的标准库中的函数,用于动释放不需要的内存空间
}
void deleteFirst()
{
deleteNode(nil->next);
}
void deleteLast()
{
deleteNode(nil->prev);
}
void deleteByKey(int key)
{
//先按值找到待删除的节点,然后删除
deleteNode(listSearch(key));
}
void insert(int key)
{
Node *x=(Node *)malloc(sizeof(Node));
x->key=key;
x->next=nil->next;
nil->next->prev=x;
nil->next=x;
x->prev=nil;
}
int main()
{
int key,n,i;
int size=0;
char com[20];
int np=0,nd=0;
scanf("%d" ,&n);
init();
for(i=0;i<n;i++)
{
scanf("%s%d",com,&key);
if(com[0]=='i')
{
insert(key);np++;size++;
}
else if(com[0]=='d')
{
if(strlen(com)>6)
{
if(com[6]=='F') deleteFirst();
else if(com[6]=='L') deleteLast();
}
deleteByKey(key);nd++;
size--;
}
}
printList();
return 0;
}测试时输入的格式是第一行先输入n,表明下面要对链表进行n个操作,之后n行中每一行的格式都是两个值,第一个值表示要进行的操作,第二个值表示要操作的值,操作包括
deleteFirst,deleteLast,deleteByKey,insert.
PS:前天中午从老家回来,到昨天中午一直在外面浪,昨天下午和晚上一直在看狼人杀的视频,所以今天才真正摸起了书本~继续更博
顾名思义,这种数据结构的特点就是每个元素之间被一条条的链子关联着,就像铁链一样。
在这条链条上的每个铁环我们成为“结点”,而每个铁环之间的挂钩我们使用“指针来实现”。链表这种数据结构有好几种形式,像单向不循环链表,单向循环链表,双向循环链表等等,这里我们就介绍其中最复杂的双向循环链表,其包含了其它几种形式链表的所有知识点。
链表中的每个结点,我们使用C++中的结构体来实现,并将节点元素值和”铁环"之间关联的指正都整合在结构体中。结点的图示如下:
其中key表示该节点存放的值,prev指向前一个节点,next指向后一个结点。其代码如下:
struct Node{
int key;
Node *next,*prev;
};
接下来我们的目的就是将每个节点给连起来,而对于一开始初始化我们使用一个特殊的结点nil,称为"头结点",头结点中不存放数据,即没有key值,只是为了便于对链表进行增删操作而增加的一个特殊结点,在链表建立初期,我们的链表中只有一个头结点,其prev和next都指向自己,初始化代码如下:
Node *nil;
void init()
{
nil=(Node *)malloc(sizeof(Node)); //malloc是C语言中的标准库中的函数,用于动态申请置顶大小的内存空间
nil->next=nil;
nil->prev=nil;
}对于一个数据结构,其最基本的就是能对存放的数据进行增删和查找操作,接下来将一一介绍。
1.遍历查找。
在已有的链表中我们就通过简单的循环遍历进行查找,并通过结点之间的指针由当前结点转移到下一个结点,我们用一个临时的结点指针cur,初始化指向头结点的下一个结点,因为头结点并不存放真正的数据。以下是查找的代码:Node* listSearch(int key)
{
Node *cur=nil->next;
while(cur!=nil && cur->key!=key)
cur=cur->next;
return cur;
}2.增加元素
链表的增加元素有头插法和尾差法,其内部的实现原理是一样的,我们就通过头插法来实现插入元素,其实插入结点就是要将其前后结点和其自己的连接关系搞清楚就行,以下是我从《挑战》书上截取的插入步骤的图例:
以下是插入的代码:void insert(int key)
{
Node *x=(Node *)malloc(sizeof(Node));
x->key=key;
x->next=nil->next;
nil->next->prev=x;
nil->next=x;
x->prev=nil;
}3.删除元素。
和插入元素,删除结点其实就是删除待删除结点与其前后结点的连接,以下同样是从《t挑战》书上截取而来:
以下代码包括删除第一个包含有效值的结点,即头结点后的第一个结点,还有通过比对值来删除指定的结点,最后还有删除最后一个结点:
void deleteNode(Node *t)
{
if(t==nil) return ;
t->next->prev=t->prev;
t->prev->next=t->next;
free(t); //free是C语言中的标准库中的函数,用于动释放不需要的内存空间
}
void deleteFirst()
{
deleteNode(nil->next);
}
void deleteLast()
{
deleteNode(nil->prev);
}
void deleteByKey(int key)
{
//先按值找到待删除的节点,然后删除
deleteNode(listSearch(key));
}其实这里删除最后一个结点就已经体现了双向循环链表的好处了,直接通过头结点的前一个结点就找到了最后一个结点,即nil->prev就是最后呢一个结点,而对于其他形式的链表,,都必须从头结点一个一个结点的遍历,知道遍历到最后一个结点,才能进行删除~
以下则是C++实现双向循环链表的全部源代码:#include<cstdio>
#include<cstdlib>
#include<cstring>
struct Node{
int key;
Node *next,*prev;
};
Node *nil;
Node* listSearch(int key)
{
Node *cur=nil->next;
while(cur!=nil && cur->key!=key)
cur=cur->next;
return cur;
}
void init()
{
nil=(Node *)malloc(sizeof(Node)); //malloc是C语言中的标准库中的函数,用于动态申请置顶大小的内存空间
nil->next=nil;
nil->prev=nil;
}
void printList()
{
Node *cur=nil->next;
int isf=0;
while(cur!=nil)
{
if(isf++>0) printf(" ");
printf("%d",cur->key);
cur=cur->next;
}
printf("\n");
}
void deleteNode(Node *t)
{
if(t==nil) return ;
t->next->prev=t->prev;
t->prev->next=t->next;
free(t); //free是C语言中的标准库中的函数,用于动释放不需要的内存空间
}
void deleteFirst()
{
deleteNode(nil->next);
}
void deleteLast()
{
deleteNode(nil->prev);
}
void deleteByKey(int key)
{
//先按值找到待删除的节点,然后删除
deleteNode(listSearch(key));
}
void insert(int key)
{
Node *x=(Node *)malloc(sizeof(Node));
x->key=key;
x->next=nil->next;
nil->next->prev=x;
nil->next=x;
x->prev=nil;
}
int main()
{
int key,n,i;
int size=0;
char com[20];
int np=0,nd=0;
scanf("%d" ,&n);
init();
for(i=0;i<n;i++)
{
scanf("%s%d",com,&key);
if(com[0]=='i')
{
insert(key);np++;size++;
}
else if(com[0]=='d')
{
if(strlen(com)>6)
{
if(com[6]=='F') deleteFirst();
else if(com[6]=='L') deleteLast();
}
deleteByKey(key);nd++;
size--;
}
}
printList();
return 0;
}测试时输入的格式是第一行先输入n,表明下面要对链表进行n个操作,之后n行中每一行的格式都是两个值,第一个值表示要进行的操作,第二个值表示要操作的值,操作包括
deleteFirst,deleteLast,deleteByKey,insert.
PS:前天中午从老家回来,到昨天中午一直在外面浪,昨天下午和晚上一直在看狼人杀的视频,所以今天才真正摸起了书本~继续更博

相关文章推荐
- 数据结构学习之双向链表
- 链表的排序
- 链表和数组的区别
- 【剑指Offer面试编程题】题目1524:复杂链表的复制--九度OJ
- 第4周实践项目3 - 单链表应用(1)
- 剑指offer22--链表的复制
- 1220链表与数组的区别
- 奇数值结点链表
- 在O(1)时间删除链表结点——13
- 链表问题
- 稀疏矩阵的十字链表存储表示和实现
- 【数据结构】单向链表
- 面试题13:在O(1)时间删除链表节点
- 第四周项目三单链表应用
- 单向链表在O(1)时间内删除一个节点
- 程序员面试金典: 9.2链表 2.5对两个用链表表示的整数求和
- 链表排序(冒泡、插入、归并和快排)
- 翻转链表 给定一个链表个一个整数k 将从右边k个翻转到前边
- 单向链表实现学生管理程序
- 单链表的C语言实现