JDK之HashMap源码解析
2017-01-16 15:42
495 查看
刚入java不久的程序猿,对于简单的使用已毫不满足,最终为了一探究竟,翻开了JDK的源码,以下观点为自己的理解及看了多篇博客的总结,欢迎各位大神指出不对的地方,当然也欢迎和我一样刚学的同学,一起加油努力吧~~
HashMap是一个用来存储键值对的集合(Entry<Key,Value>),HashMap实现了Map接口,是一个基于数组和链表的实现,通过Key值计算出hash值,接着根据hash值和table的长度计算出index值(相当于数组中的位置),最后对链表进行相关的操作
图片引自http://blog.csdn.net/vking_wang/article/details/14166593
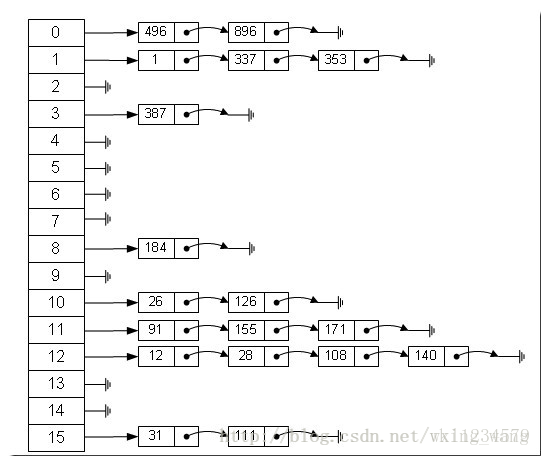
根据上图可看出根据算出的Index值找到数组中的位置,然后在链表中进行操作
这里可以看到HashMap继承了AbstractMap这个抽象类,并且实现了Map接口,下面我们先来看看这个抽象类
里面具体的实现大家可以自己看下,这里我们可以看到AbstractMap同样也实现了Map接口,这时可能会有疑问HashMap已经继承了AbstractMap,应该说不用再次去实现Map接口了,查阅了很多资料,最多的解释是为了看起来结构更清晰,除了这个我也确实想不出来为什么要实现,毕竟实现2次也没什么影响,下面来看一看map接口里有哪些方法需要实现
上面对Map接口的方法做了相应的注释,大致了解方法作用后,我们来看看HashMap中具体的实现,首先是HashMap里各种参数的定义
接下来是一个内部类,用来初始化值的
接下来,是一个比较重要的构造方法了,在我们new HashMap()时会用到,因为在new的时候会调用这个重载的方法,这里还有个参数hashSeed,后面计算哈希值时用到
接下来是三个构造方法,调用的都是上面的方法
这里我们看到有个inflateTable方法点进去看一下
inflateTable结束后,接下来来看putAllForCreate方法
继续进入putForCreate方法
构造方法说完,下面就是HashMap中我们用的最频繁的方法了get和put,接下来继续看代码,首先是get方法
接下来是put方法
至此,HashMap的常用方法都已介绍完,不懂的小伙伴可以评论,看到了会进行回复,有错误希望指出
| HashMap是什么 |
| HashMap原理图 |
根据上图可看出根据算出的Index值找到数组中的位置,然后在链表中进行操作
| HashMap源码分析 |
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable{
.....
}这里可以看到HashMap继承了AbstractMap这个抽象类,并且实现了Map接口,下面我们先来看看这个抽象类
public abstract class AbstractMap<K,V> implements Map<K,V> {
...
}里面具体的实现大家可以自己看下,这里我们可以看到AbstractMap同样也实现了Map接口,这时可能会有疑问HashMap已经继承了AbstractMap,应该说不用再次去实现Map接口了,查阅了很多资料,最多的解释是为了看起来结构更清晰,除了这个我也确实想不出来为什么要实现,毕竟实现2次也没什么影响,下面来看一看map接口里有哪些方法需要实现
public interface Map<K,V> {
/**
* 计算HashMap的长度
*/
int size();
/**
* 判断HashMap是否为空
*/
boolean isEmpty();
/**
* 判断HashMap里是否包含此key
*/
boolean containsKey(Object key);
/**
* 判断HashMap里是否包含此value
*/
boolean containsValue(Object value);
/**
* 根据key值获取value
*/
V get(Object key);
/**
* 往HashMap中存放元素
*/
V put(K key, V value);
/**
* 根据key值删除元素
*/
V remove(Object key);
/**
* 将另一个map中所有元素放入HashMap
*/
void putAll(Map<? extends K, ? extends V> m);
/**
* 清空HashMap
*/
void clear();
/**
* 遍历出HashMap中所有key值
*/
Set<K> keySet();
/**
* 遍历出HashMap中所有value
*/
Collection<V> values();
/**
* 将HashMap转换为Set集合,元素为Entry
*/
Set<Map.Entry<K, V>> entrySet();
/**
* Entry接口
*/
interface Entry<K,V> {
/**
* 获取key值
*/
K getKey();
/**
* 获取value
*/
V getValue();
/**
* 设置value
*/
V setValue(V value);
/**
* 判断值是否相等
*/
boolean equals(Object o);
/**
* 计算哈希值
*/
int hashCode();
}
/**
* 计算值是否相等
*/
boolean equals(Object o);
/**
* 计算哈希值
*/
int hashCode();
}上面对Map接口的方法做了相应的注释,大致了解方法作用后,我们来看看HashMap中具体的实现,首先是HashMap里各种参数的定义
/**
* 默认初始容量为16,1左移4位,二进制10000,换算成10进制为16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 最大容量1073741824,1左移30位后,换算成10进制为1073741824
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认加载因子,默认为0.75
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 空的Entry
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* 数组表,大小为2的幂次方
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* HashMap的大小
*/
transient int size;
/**
* 阈值(也就是我们平时所说的临界值,或者说边界值),当大小超过阈值时,开始扩容
*/
int threshold;
/**
* 加载因子
*/
final float loadFactor;
/**
* hash表结构修改次数
*/
transient int modCount;
/**
* 容量阈值,大小为Interger的最大容量
*/
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;接下来是一个内部类,用来初始化值的
/**
* 静态内部类Holder,调用该类时初始化值
*/
private static class Holder {
/**
* 容量阈值,初始化hashSeed时候使用
*/
static final int ALTERNATIVE_HASHING_THRESHOLD;
static {
/**
* 获取系统变量jdk.map.althashing.threshold
*/
String altThreshold = java.security.AccessController.doPrivileged(
new sun.security.action.GetPropertyAction(
"jdk.map.althashing.threshold"));
int threshold;
try {
/**
* 判断altThreshold是否为空,并为阈值赋值
*/
thres
ff64
hold = (null != altThreshold)
? Integer.parseInt(altThreshold)
: ALTERNATIVE_HASHING_THRESHOLD_DEFAULT;
// 如果该阈值为-1,则将Integer最大值赋予阈值
if (threshold == -1) {
threshold = Integer.MAX_VALUE;
}
//当阈值小于0时,抛出IllegalArgumentException异常
if (threshold < 0) {
throw new IllegalArgumentException("value must be positive integer.");
}
} catch(IllegalArgumentException failed) {
throw new Error("Illegal value for 'jdk.map.althashing.threshold'", failed);
}
ALTERNATIVE_HASHING_THRESHOLD = threshold;
}
}接下来,是一个比较重要的构造方法了,在我们new HashMap()时会用到,因为在new的时候会调用这个重载的方法,这里还有个参数hashSeed,后面计算哈希值时用到
/**
* 后面计算hash值时用到
*/
transient int hashSeed = 0;
/**
* @param initialCapacity 初始化容量大小(但并不是真正初始化大小)
* @param loadFactor 加载因子
* @throws IllegalArgumentException 抛出IllegalArgumentException异常
*/
public HashMap(int initialCapacity, float loadFactor) {
//当初始化容量大小小于0时,抛出IllegalArgumentException异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);
//当初始化容量大小大于最大容量大小时,将最大容量值赋予初始化容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//当加载因子小于0或者为无效数字时,抛出IllegalArgumentException异常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +loadFactor);
//加载因子
this.loadFactor = loadFactor;
//阈值
threshold = initialCapacity;
init();
}接下来是三个构造方法,调用的都是上面的方法
/**
* @param initialCapacity 初始化容量
* @throws IllegalArgumentException 抛出IllegalArgumentException异常
* 调用HashMap重载的构造方法,参数分别为初始化容量和默认的加载因子,也就是0.75f
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* 调用HashMap重载的构造方法,参数分别为默认初始化容量和默认的加载因子
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/**
* @param Map对象
* this调用相应构造方法,传入初始化容量Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1 和 DEFAULT_INITIAL_CAPACITY)
*/
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
inflateTable(threshold);
putAllForCreate(m);
}这里我们看到有个inflateTable方法点进去看一下
/**
* 对table进行扩容
*/
private void inflateTable(int toSize) {
// 找一个2的n次方的值并>=toSize
int capacity = roundUpToPowerOf2(toSize);
//计算出下次的阈值
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
//初始化hashSeed
initHashSeedAsNeeded(capacity);
}
/**
* 当number大于最大容量时,返回最大容量
* 当number小于最大容量时,返回大于等于number的最小2的n次方值
*/
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}inflateTable结束后,接下来来看putAllForCreate方法
/**
* 循环Map赋值
*/
private void putAllForCreate(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
putForCreate(e.getKey(), e.getValue());
}继续进入putForCreate方法
/**
* 将值放入table
*/
private void putForCreate(K key, V value) {
//计算哈希值,具体方法下面有
int hash = null == key ? 0 : hash(key);
//根据哈希值和表的长度计算出在数组中的位置
int i = indexFor(hash, table.length);
//如果entry不为空,循环entry
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//当hash和key满足条件时赋值
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
e.value = value;
return;
}
}
//entry为空时,创建
createEntry(hash, key, value, i);
}
/**
* 计算哈希值
*/
final int hash(Object k) {
int h = hashSeed;
//如果key为字符串则调用哈希算法计算哈希值
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
//调用key的hashCode方法,并与hashSeed进行异或操作
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* 通过hash值和数组的长度计算下标,h & (length-1)操作 等价于 hash % length操作, 但&操作性能更优
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
/**
* 创建entry,放入链表表头
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
//新建entry放入链表表头
table[bucketIndex] = new Entry<>(hash, key, value, e);
//hashMap长度加1
size++;
}构造方法说完,下面就是HashMap中我们用的最频繁的方法了get和put,接下来继续看代码,首先是get方法
/**
* 根据Key获取对应的值
*/
public V get(Object key) {
//当key为空时,调用getForNullKey方法
if (key == null)
return getForNullKey();
//调用getEntry方法获取链表
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
/**
* 当key为空时,调用此方法
*/
private V getForNullKey() {
//长度为0时,直接返回null
if (size == 0) {
return null;
}
//遍历entry,找到key为null的值,返回value
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
/**
* 根据key获得相应的entry
*/
final Entry<K,V> getEntry(Object key) {
//长度为0时,直接返回null
if (size == 0) {
return null;
}
//key为null时返回0,否则根据hash算法计算出哈希值
int hash = (key == null) ? 0 : hash(key);
//调用indexFor方法,找出数组中对应的下标,并遍历entry
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//当哈希值相同并且key相同时,返回entry
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}接下来是put方法
/**
* 向HashMap中存放元素
*/
public V put(K key, V value) {
//如果table为空,为数组分配空间
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为null,调用putForNullKey方法
if (key == null)
return putForNullKey(value);
//key不为null,计算哈希值
int hash = hash(key);
//计算数组下标
int i = indexFor(hash, table.length);
//根据下标找到对应entry存在时,遍历entry
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//当哈希值和key都满足条件时,重新赋值,并返回旧的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//当entry不存在时,调用addEntry方法
addEntry(hash, key, value, i);
return null;
}
/**
* 当key为null时,赋值
*/
private V putForNullKey(V value) {
//遍历数组中第一个entry,当e存在时进入循环,赋值并返回旧的value
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//当e不存在时候,调用addEntry方法
addEntry(0, null, value, 0);
return null;
}
/**
* 新增entry
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//当hashmap长度大于阈值并且该位置存在链表时,对其进行扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容,两倍的table长度
resize(2 * table.length);
//重新计算哈希值
hash = (null != key) ? hash(key) : 0;
//重新计算数组中位置
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
/**
* 对数组进行扩容
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//旧的容量如果等于最大容量,将Integer的最大值赋予阈值
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//创建一个长度为newCapacity的数组
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//数组替换成新数组
table = newTable;
//重新计算阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* 将旧的键值对拷贝到新的哈希表里
*/
void transfer(Entry[] newTable, boolean rehash) {
//新的数组的长度
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//根据哈希值和新的数组长度重新计算在数组里的位置
int i = indexFor(e.hash, newCapacity);
//插入到表头
e.next = newTable[i];
//将e放入数组对应位置
newTable[i] = e;
//将e设置为下一个链表节点
e = next;
}
}
}至此,HashMap的常用方法都已介绍完,不懂的小伙伴可以评论,看到了会进行回复,有错误希望指出

相关文章推荐
- HashMap源码解析(基于JDK1.7)
- 【源码解析】JDK源码之LinkedHashMap
- JDK1.8源码解析之 HashMap
- HashMap源码解析(jdk1.8)
- JDK源码之HashMap源码解析
- 【集合源码】HashMap源码解析(基于JDK 1.8)
- 【jdk源码解析二】java.uti.HashMap源码解析
- HashMap 源码解析(JDK1.8)
- JDK源码解析之HashMap类
- 【源码解析】JDK源码之HashMap
- HashMap源码解析 给jdk写注释系列之jdk1.6容器(4)
- JDK源码解析集合篇--HashMap无敌全解析
- JDK 1.7 HashMap原理及源码解析
- HashMap的put方法源码解析_JDK1.7
- HashMap源码解析(基于JDK1.7)
- JDK源码解析之HashMap
- 【JDk源码解析之三】HashMap源码解析
- Java集合框架--HashMap源码解析(JDK1.7)
- HashMap源码解析(JDK1.8)
- 给jdk写注释系列之jdk1.6容器(4)-HashMap源码解析