BOW 原理及代码解析
2017-01-11 09:17
239 查看
文章源网址http://blog.csdn.net/tiandijun/article/details/51143765
引言
最初的Bag of words,也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词
是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
Bag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数(下文中,将用单词的直方图表示)。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序(这是本Bag-of-words模型的缺点之一,不过瑕不掩瑜甚至在此处无关紧要)。
一、原理
考虑将Bag-of-words模型应用于图像表示。为了表示一幅图像,我们可以将图像看作文档,即若干个“视觉词汇”的集合,同样的,视觉词汇相互之间没有顺序。
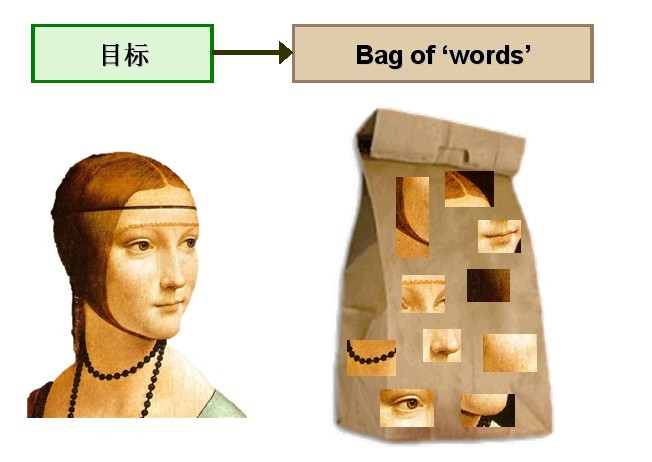
图1 将Bag-of-words模型应用于图像表示
由于图像中的词汇不像文本文档中的那样是现成的,我们需要首先从图像中提取出相互独立的视觉词汇,这通常需要经过三个步骤:
(1)特征检测
(2)特征表示
(3)单词本的生成,

图2 从图像中提取出相互独立的视觉词汇
通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛,嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
而SIFT算法是提取图像中局部不变特征的应用最广泛的算法,因此我们可以用SIFT算法从图像中提取不变特征点,作为视觉词汇,并构造单词表,用单词表中的单词表示一幅图像。
接下来,我们通过上述图像展示如何通过Bag-of-words模型,将图像表示成数值向量。现在有三个目标类,分别是人脸、自行车和吉他。
第一步:利用SIFT算法,从每类图像中提取视觉词汇,将所有的视觉词汇集合在一起,如下图3所示:

图3 从每类图像中提取视觉词汇
第二步:利用K-Means算法构造单词表。K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为单词表中的基础词汇,假定我们将K设为4,那么单词表的构造过程如下图4所示:

图4 利用K-Means算法构造单词表
第三步:利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。
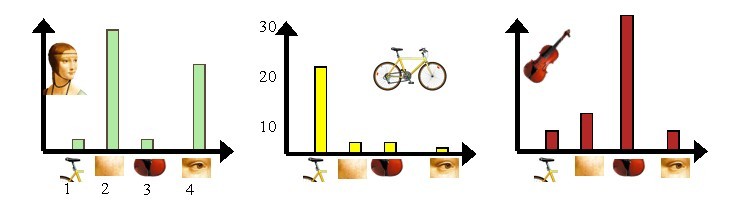
图5 每幅图像的直方图表示
上图5中,我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇表中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉单词,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示(我们假定存在误差,实际情况亦不外如此):
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个词典,词典中包含4个视觉单词,即Dictionary = {1:”自行车”, 2. “人脸”, 3. “吉他”, 4. “人脸类”},最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数画成了上面对应的直方图。
需要说明的是,以上过程只是针对三个目标类非常简单的一个示例,实际应用中,为了达到较好的效果,单词表中的词汇数量K往往非常庞大,并且目标类数目越多,对应的K值也越大,一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。
下面,我们再来总结一下如何利用Bag-of-words模型将一幅图像表示成为数值向量:
第一步:利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点;
第二步:将所有特征点向量集合到一块,利用K-Means算法合并词义相近的视觉词汇,构造一个包含K个词汇的单词表;
第三步:统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量。
具体的,假设有5类图像,每一类中有10幅图像,这样首先对每一幅图像划分成patch(可以是刚性分割也可以是像SIFT基于关键点检测的),这样,每一个图像就由很多个patch表示,每一个patch用一个特征向量来表示,咱就假设用Sift表示的,一幅图像可能会有成百上千个patch,每一个patch特征向量的维数128。
接下来就要进行构建Bag of words模型了,假设Dictionary词典的Size为100,即有100个词。那么咱们可以用K-means算法对所有的patch进行聚类,k=100,我们知道,等k-means收敛时,我们也得到了每一个cluster最后的质心,那么这100个质心(维数128)就是词典里德100个词了,词典构建完毕。
词典构建完了怎么用呢?是这样的,先初始化一个100个bin的初始值为0的直方图h。每一幅图像不是有很多patch么?我们就再次计算这些patch和和每一个质心的距离,看看每一个patch离哪一个质心最近,那么直方图h中相对应的bin就加1,然后计算完这幅图像所有的patches之后,就得到了一个bin=100的直方图,然后进行归一化,用这个100维德向量来表示这幅图像。对所有图像计算完成之后,就可以进行分类聚类训练预测之类的了。
图像的特征用到了Dense Sift,通过Bag of Words词袋模型进行描述,当然一般来说是用训练集的来构建词典,因为我们还没有测试集呢。虽然测试集是你拿来测试的,但是实际应用中谁知道测试的图片是啥,所以构建BoW词典我这里也只用训练集。
用BoW描述完图像之后,指的是将训练集以及测试集的图像都用BoW模型描述了,就可以用SVM训练分类模型进行分类了。
在这里除了用SVM的RBF核,还自己定义了一种核: histogram intersection kernel,直方图正交核。因为很多论文说这个核好,并且实验结果很显然。能从理论上证明一下么?通过自定义核也可以了解怎么使用自定义核来用SVM进行分类。
二、K-Means聚类的效率优化
影响效率的一个方面是构建词典时的K-means聚类,我在用的时候遇到了两个问题:
1、内存溢出。这是由于一般的K-means函数的输入是待聚类的完整的矩阵,在这里就是所有patches的特征向量f合成的一个大矩阵,由于这个矩阵太大,内存不顶了。我内存为4G。
2、效率低。因为需要计算每一个patch和每一个质心的欧拉距离,还有比较大小,那么要是循环下来这个效率是很低的。
为了解决这个问题,我采用一下策略,不使用整一个数据矩阵X作为输入的k-means,而是自己写循环,每次处理一幅图像的所有patches,对于效率的问题,因为matlab强大的矩阵处理能力,可以有效避免耗时费力的自己编写的循环迭代。
三、代码
代码下载链接:PG_BOW_DEMO.zip
Demo中的图像是我自己研究中用到的一些Action的图像,我都采集的简单的一共6类,每一类60幅,40训练20测试。请注意图像的版权问题,自己研究即可,不能商用。分类器用的是libsvm,最好自己mex重新编译一下。
如果libsvm版本不合适或者没有编译成适合你的平台的,会报错,例如:
Classification using BOW rbf_svm
??? Error using ==> svmtrain at 172
Group must be a vector.
下面是默认的demo结果:
Classification using BOW rbf_svm
Accuracy = 75.8333% (91/120) (classification)
Classification using histogram intersection kernel svm
Accuracy = 82.5% (99/120) (classification)
Classification using Pyramid BOW rbf_svm
Accuracy = 82.5% (99/120) (classification)
Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 90% (108/120) (classification)
当然结果这个样子是因为我已经把6类图像提前弄成一样大了,而且每一类都截取了最关键的子图,不太符合实际,但是为了demo方便,当然图像大小可以是任意的。
下图就是最好结果的混淆矩阵,最好结果就是Pyramid BoW+hik-SVM:

图6 分类混淆矩阵
这是在另一个数据集上的结果(7类分类问题):
Classification using BOW rbf_svm
Accuracy = 34.5714% (242/700) (classification)
Classification using histogram intersection kernel svm
Accuracy = 36% (252/700) (classification)
Classification using Pyramid BOW rbf_svm
Accuracy = 43.7143% (306/700) (classification)
Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 55.8571% (391/700) (classification)
引言
最初的Bag of words,也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词
是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
Bag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数(下文中,将用单词的直方图表示)。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序(这是本Bag-of-words模型的缺点之一,不过瑕不掩瑜甚至在此处无关紧要)。
一、原理
考虑将Bag-of-words模型应用于图像表示。为了表示一幅图像,我们可以将图像看作文档,即若干个“视觉词汇”的集合,同样的,视觉词汇相互之间没有顺序。
图1 将Bag-of-words模型应用于图像表示
由于图像中的词汇不像文本文档中的那样是现成的,我们需要首先从图像中提取出相互独立的视觉词汇,这通常需要经过三个步骤:
(1)特征检测
(2)特征表示
(3)单词本的生成,
图2 从图像中提取出相互独立的视觉词汇
通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛,嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
而SIFT算法是提取图像中局部不变特征的应用最广泛的算法,因此我们可以用SIFT算法从图像中提取不变特征点,作为视觉词汇,并构造单词表,用单词表中的单词表示一幅图像。
接下来,我们通过上述图像展示如何通过Bag-of-words模型,将图像表示成数值向量。现在有三个目标类,分别是人脸、自行车和吉他。
第一步:利用SIFT算法,从每类图像中提取视觉词汇,将所有的视觉词汇集合在一起,如下图3所示:
图3 从每类图像中提取视觉词汇
第二步:利用K-Means算法构造单词表。K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为单词表中的基础词汇,假定我们将K设为4,那么单词表的构造过程如下图4所示:
图4 利用K-Means算法构造单词表
第三步:利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。
图5 每幅图像的直方图表示
上图5中,我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇表中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉单词,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示(我们假定存在误差,实际情况亦不外如此):
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个词典,词典中包含4个视觉单词,即Dictionary = {1:”自行车”, 2. “人脸”, 3. “吉他”, 4. “人脸类”},最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数画成了上面对应的直方图。
需要说明的是,以上过程只是针对三个目标类非常简单的一个示例,实际应用中,为了达到较好的效果,单词表中的词汇数量K往往非常庞大,并且目标类数目越多,对应的K值也越大,一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。
下面,我们再来总结一下如何利用Bag-of-words模型将一幅图像表示成为数值向量:
第一步:利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点;
第二步:将所有特征点向量集合到一块,利用K-Means算法合并词义相近的视觉词汇,构造一个包含K个词汇的单词表;
第三步:统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量。
具体的,假设有5类图像,每一类中有10幅图像,这样首先对每一幅图像划分成patch(可以是刚性分割也可以是像SIFT基于关键点检测的),这样,每一个图像就由很多个patch表示,每一个patch用一个特征向量来表示,咱就假设用Sift表示的,一幅图像可能会有成百上千个patch,每一个patch特征向量的维数128。
接下来就要进行构建Bag of words模型了,假设Dictionary词典的Size为100,即有100个词。那么咱们可以用K-means算法对所有的patch进行聚类,k=100,我们知道,等k-means收敛时,我们也得到了每一个cluster最后的质心,那么这100个质心(维数128)就是词典里德100个词了,词典构建完毕。
词典构建完了怎么用呢?是这样的,先初始化一个100个bin的初始值为0的直方图h。每一幅图像不是有很多patch么?我们就再次计算这些patch和和每一个质心的距离,看看每一个patch离哪一个质心最近,那么直方图h中相对应的bin就加1,然后计算完这幅图像所有的patches之后,就得到了一个bin=100的直方图,然后进行归一化,用这个100维德向量来表示这幅图像。对所有图像计算完成之后,就可以进行分类聚类训练预测之类的了。
图像的特征用到了Dense Sift,通过Bag of Words词袋模型进行描述,当然一般来说是用训练集的来构建词典,因为我们还没有测试集呢。虽然测试集是你拿来测试的,但是实际应用中谁知道测试的图片是啥,所以构建BoW词典我这里也只用训练集。
用BoW描述完图像之后,指的是将训练集以及测试集的图像都用BoW模型描述了,就可以用SVM训练分类模型进行分类了。
在这里除了用SVM的RBF核,还自己定义了一种核: histogram intersection kernel,直方图正交核。因为很多论文说这个核好,并且实验结果很显然。能从理论上证明一下么?通过自定义核也可以了解怎么使用自定义核来用SVM进行分类。
二、K-Means聚类的效率优化
影响效率的一个方面是构建词典时的K-means聚类,我在用的时候遇到了两个问题:
1、内存溢出。这是由于一般的K-means函数的输入是待聚类的完整的矩阵,在这里就是所有patches的特征向量f合成的一个大矩阵,由于这个矩阵太大,内存不顶了。我内存为4G。
2、效率低。因为需要计算每一个patch和每一个质心的欧拉距离,还有比较大小,那么要是循环下来这个效率是很低的。
为了解决这个问题,我采用一下策略,不使用整一个数据矩阵X作为输入的k-means,而是自己写循环,每次处理一幅图像的所有patches,对于效率的问题,因为matlab强大的矩阵处理能力,可以有效避免耗时费力的自己编写的循环迭代。
三、代码
代码下载链接:PG_BOW_DEMO.zip
Demo中的图像是我自己研究中用到的一些Action的图像,我都采集的简单的一共6类,每一类60幅,40训练20测试。请注意图像的版权问题,自己研究即可,不能商用。分类器用的是libsvm,最好自己mex重新编译一下。
如果libsvm版本不合适或者没有编译成适合你的平台的,会报错,例如:
Classification using BOW rbf_svm
??? Error using ==> svmtrain at 172
Group must be a vector.
下面是默认的demo结果:
Classification using BOW rbf_svm
Accuracy = 75.8333% (91/120) (classification)
Classification using histogram intersection kernel svm
Accuracy = 82.5% (99/120) (classification)
Classification using Pyramid BOW rbf_svm
Accuracy = 82.5% (99/120) (classification)
Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 90% (108/120) (classification)
当然结果这个样子是因为我已经把6类图像提前弄成一样大了,而且每一类都截取了最关键的子图,不太符合实际,但是为了demo方便,当然图像大小可以是任意的。
下图就是最好结果的混淆矩阵,最好结果就是Pyramid BoW+hik-SVM:
图6 分类混淆矩阵
这是在另一个数据集上的结果(7类分类问题):
Classification using BOW rbf_svm
Accuracy = 34.5714% (242/700) (classification)
Classification using histogram intersection kernel svm
Accuracy = 36% (252/700) (classification)
Classification using Pyramid BOW rbf_svm
Accuracy = 43.7143% (306/700) (classification)
Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 55.8571% (391/700) (classification)

相关文章推荐
- 【整合】快速搭建github ssh 环境
- ASP.net与SQLite数据库通过js和ashx交互(连接和操作)
- java - 四种强弱软虚引用使用到的场景
- mongo笔记
- python数据类型
- c#小技巧总结
- visual studio 2010 无法连接到ASP.NET Development Server
- C++ vector用法的详解
- C# DataTable用法
- java中int和Integer什么区别
- Some Tips About C++
- C++ 11笔记
- Java 文件过滤工具(通用)
- java 数组及内存
- Python和C++程序发布和订阅ROS话题
- 解决 Qt 使用 PNG 图片时报错:libpng warning: iCCP: known incorrect sRGB profile
- C#中(int)a和Convert.ToInt32(a)的区别
- 基于51单片机的CAN通讯协议C语言程序
- [李景山php]每天TP5-20170204|thinkphp5-Response.php
- 模板——类模板