深入剖析Redis主从复制
2017-01-04 10:26
555 查看
一、主从概述
Redis 支持 Master-Slave(主从)模式,Redis Server 可以设置为另一个 Redis Server 的主机(从机),从机定期从主机拿数据。特殊的,一个从机同样可以设置为一个 Redis Server 的主机,这样一来 Master-Slave 的分布看起来就是一个有向无环图 DAG,如此形成 Redis Server 集群,无论是主机还是从机都是 Redis
Server,都可以提供服务。

在配置后,主机可负责读写服务,从机只负责读。Redis 提高这种配置方式,为的是让其支持数据的弱一致性,即最终一致性。在业务中,选择强一致性还是弱一致性,应该取决于具体的业务需求,像微博,完全可以使用弱一致性模型;像淘宝,可以选用强一致性模型。
Redis 主从复制的实现主要在 replication.c 中。
这篇文章涉及较多的代码,但我已经尽量删繁就简,达到能说明问题本质。为了保留代码的原生性并让读者能够阅读原生代码的注释,剖析 Redis 的几篇文章都没有删除代码中的英文注释,并已加注释。
二、积压空间
在《深入剖析 Redis AOF 持久化策略》中,介绍了更新缓存的概念,举一个例子:客户端发来命令:set name Jhon,这一数据更新被记录为:*3\r\n$3\r\nSET\r\n$4\r\nname\r\n$3\r\nJhon\r\n,并存储在更新缓存中。
同样,在主从连接中,也有更新缓存的概念。只是两者的用途不一样,前者被写入本地,后者被写入从机,这里我们把它称为积压空间。
更新缓存存储在 server.repl_backlog,Redis 将其作为一个环形空间来处理,这样做节省了空间,避免内存再分配的情况。
积压空间中的数据变更记录是什么时候被写入的?在执行一个 Redis 命令的时候,如果存在数据的修改(写),那么就会把变更记录传播。Redis
源码中是这么实现的:call()->propagate()->replicationFeedSlaves()
注释:命令真正执行的地方在 call() 中,call() 如果发现数据被修改(dirty),则传播 propagrate(),replicationFeedSlaves() 将修改记录写入积压空间和所有已连接的从机。
这里可能会有疑问:为什么把数据添加入积压空间,又把数据分发给所有的从机?为什么不仅仅将数据分发给所有从机呢?
因为有一些从机会因特殊情况(???)与主机断开连接,注意从机断开前有暂存主机的状态信息,因此这些断开的从机就没有及时收到更新的数据。Redis 为了让断开的从机在下次连接后能够获取更新数据,将更新数据加入了积压空间。从 replicationFeedSlaves() 实现来看,在线的 Slave 能马上收到数据更新记录;因某些原因暂时断开连接的 Slave,需要从积压空间中找回断开期间的数据更新记录。如果断开的时间足够长,Master
会拒绝 Slave 的部分同步请求,从而 Slave 只能进行全同步。
下面是源码注释:
三、主从数据同步机制概述
Redis 主从同步有两种方式(或者所两个阶段):全同步和部分同步。
主从刚刚连接的时候,进行全同步;全同步结束后,进行部分同步。当然,如果有需要,Slave 在任何时候都可以发起全同步。Redis 策略是,无论如何,首先会尝试进行部分同步,如不成功,要求从机进行全同步,并启动 BGSAVE……BGSAVE 结束后,传输 RDB 文件;如果成功,允许从机进行部分同步,并传输积压空间中的数据。
下面这幅图,总结了主从同步的机制:

如需设置 Slave,Master 需要向 Slave 发送 SLAVEOF hostname port,从机接收到后会自动连接主机,注册相应读写事件(syncWithMaster())。
四、全同步
接着自动发起 PSYNC 请求 Master 进行全同步。无论如何,Redis 首先会尝试部分同步,如果失败才尝试全同步。而刚刚建立连接的 Master-Slave 需要全同步。
从机连接主机后,会主动发起 PSYNC 命令,从机会提供 master_runid 和 offset,主机验证 master_runid 和 offset 是否有效?master_runid 相当于主机身份验证码,用来验证从机上一次连接的主机,offset 是全局积压空间数据的偏移量。
验证未通过则,则进行全同步:主机返回 +FULLRESYNC master_runid offset(从机接收并记录 master_runid 和 offset,并准备接收 RDB 文件)接着启动 BGSAVE 生成 RDB 文件,BGSAVE 结束后,向从机传输,从而完成全同步。
全同步请求的数据是 RDB 数据文件和积压空间中的数据。关于 RDB 数据文件,请参看《深入剖析 Redis RDB 持久化策略》。如果没有后台持久化 BGSAVE 进程,那么 BGSVAE 会被触发,否则所有请求全同步的 Slave 都会被标记为等待 BGSAVE 结束。BGSAVE 结束后,Master 会马上向所有的从机发送 RDB 文件。
五、部分同步
如上所说,无论如何,Redis 首先会尝试部分同步。部分同步即把积压空间缓存的数据,即更新记录发送给从机。
从机连接主机后,会主动发起 PSYNC 命令,从机会提供 master_runid 和 offset,主机验证 master_runid 和 offset 是否有效?
验证通过则,进行部分同步:主机返回 +CONTINUE(从机接收后会注册积压数据接收事件),接着发送积压空间数据。
六、暂缓主机
从机因为某些原因,譬如网络延迟(PING 超时,ACK 超时等),可能会断开与主机的连接。这时候,从机会尝试保存与主机连接的信息,譬如全局积压空间数据偏移量等,以便下一次的部分同步,并且从机会再一次尝试连接主机。注意一点,如果断开的时间足够长,部分同步肯定会失败的。
七、总结
简单来说,主从同步就是 RDB 文件的上传下载;主机有小部分的数据修改,就把修改记录传播给每个从机。这篇文章详述了 Redis 主从复制的内部协议和机制。接下来的几篇关于 Redis 的文章,主要是其内部数据结构。
Redis的主从同步机制可以确保redis的master和slave之间的数据同步。按照同步内容的多少可以分为全同步和部分同步;按照同步的时机可以分为slave刚启动时的初始化同步和正常运行过程中的数据修改同步;本文将对这两种机制的流程进行分析。
全备份过程中,在slave启动时,会向其master发送一条SYNC消息,master收到slave的这条消息之后,将可能启动后台进程进行备份,备份完成之后就将备份的数据发送给slave,初始时的全同步机制是这样的:
(1)slave启动后向master发送同步指令SYNC,master接收到SYNC指令之后将调用该命令的处理函数syncCommand()进行同步处理;
(2)在函数syncCommand中,将调用函数rdbSaveBackground启动一个备份进程用于数据同步,如果已经有一个备份进程在运行了,就不会再重新启动了。
(3)备份进程将执行函数rdbSave()完成将redis的全部数据保存为rdb文件。
(4)在redis的时间事件函数serverCron(redis的时间处理函数是指它会定时被redis进行操作的函数)中,将对备份后的数据进行处理,在serverCron函数中将会检查备份进程是否已经执行完毕,如果备份进程已经完成备份,则调用函数backgroundSaveDoneHandler完成后续处理。
(5)在函数backgroundSaveDoneHandler中,首先更新master的各种状态,例如,备份成功还是失败,备份的时间等等。然后调用函数updateSlavesWaitingBgsave,将备份的rdb数据发送给等待的slave。
(6)在函数updateSlavesWaitingBgsave中,将遍历所有的等待此次备份的slave,将备份的rdb文件发送给每一个slave。另外,这里并不是立即就把数据发送过去,而是将为每个等待的slave注册写事件,并注册写事件的响应函数sendBulkToSlave,即当slave对应的socket能够发送数据时就调用函数sendBulkToSlave(),实际发送rdb文件的操作都在函数sendBulkToSlave中完成。
(7)sendBulkToSlave函数将把备份的rdb文件发送给slave。
上述函数调用过程如下图1所示:
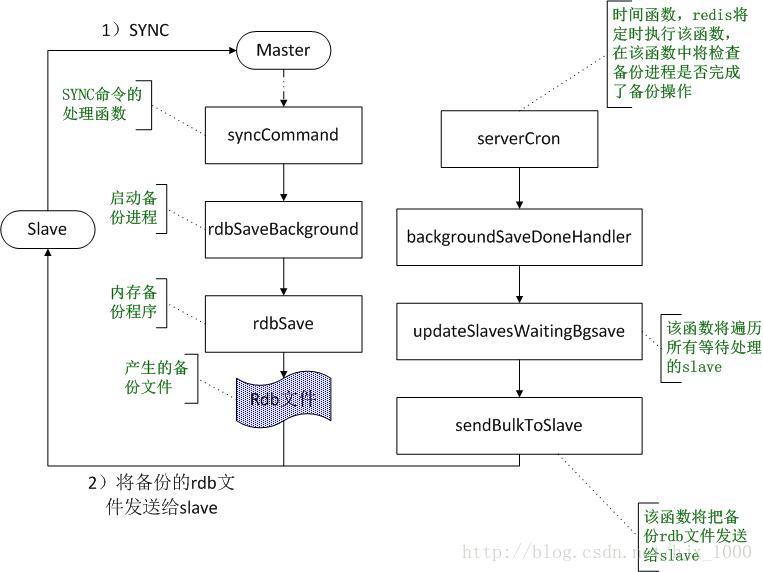
图1 redis全备份时master部分的的函数调用过程
二、数据修改操作的同步
Redis的正常部署中一般都是一个master用于写操作,若干个slave用于读操作,另外定期的数据备份操作也是单独选址一个slave完成,这样可以最大程度发挥出redis的性能。在部署完成,各master\slave程序启动之后,首先进行第一阶段初始化时的全同步操作,全同步操作完成之后,后续所有写操作都是在master上进行,所有读操作都是在slave上进行,因此用户的写操作需要及时扩散到所有的slave以便保持数据最大程度上的同步。Redis的master-slave进程在正常运行期间更新操作(包括写、删除、更改操作)的同步方式如下:
(1)master接收到一条用户的操作后,将调用函数call函数来执行具体的操作函数(此过程可参考另一文档《redis命令执行流程分析》),在该函数中首先通过proc执行操作函数,然后将判断操作是否需要扩散到各slave,如果需要则调用函数propagate()来完成此操作。
(2)propagate()函数完成将一个操作记录到aof文件中或者扩散到其他slave中;在该函数中通过调用feedAppendOnlyFile()将操作记录到aof中,通过调用replicationFeedSlaves()将操作扩散到各slave中。
(3)函数feedAppendOnlyFile()中主要保存操作到aof文件,在该函数中首先将操作转换成redis内部的协议格式,并以字符串的形式存储,然后将字符串存储的操作追加到aof文件后。
(4)函数replicationFeedSlaves()主要将操作扩散到每一个slave中;在该函数中将遍历自己下面挂的每一个slave,以此对每个slave进行如下两步的处理:将slave的数据库切换到本操作所对应的数据库(如果slave的数据库id与当前操作的数据id不一致时才进行此操作);将命令和参数按照redis的协议格式写入到slave的回复缓存中。写入切换数据库的命令时将调用addReply,写入命令和参数时将调用addReplyMultiBulkLen和addReplyBulk,函数addReplyMultiBulkLen和addReplyBulk最终也将调用函数addReply。
(5)在函数addReply中将调用prepareClientToWrite()设置slave的socket写入事件处理函数sendReplyToClient(通过函数aeCreateFileEvent进行设置),这样一旦slave对应的socket发送缓存中有空间写入数据,即调用sendReplyToClient进行处理。
(6)函数sendReplyToClient()的主要功能是将slave中要发送的数据通过socket发出去。
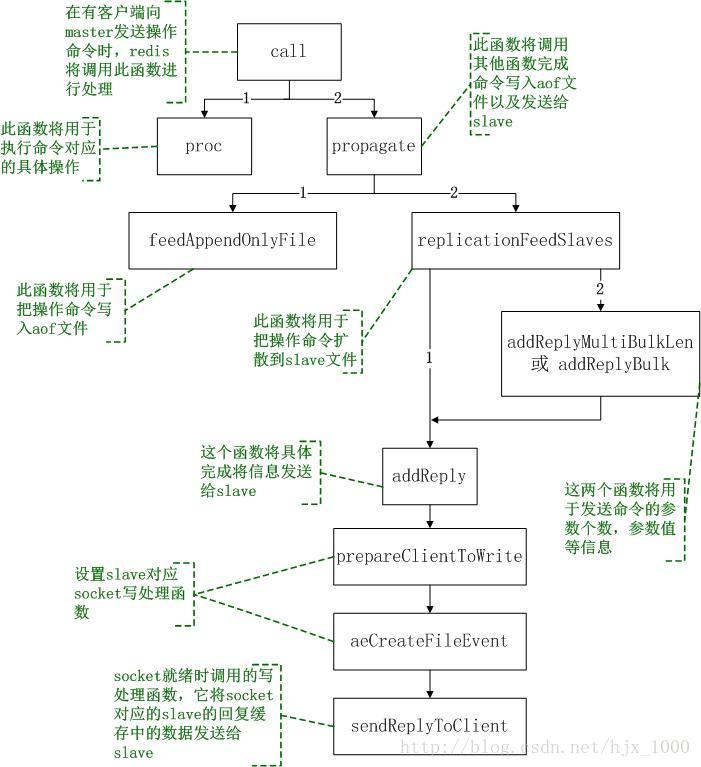
图2、redis操作过程中数据同步的函数调用关系
图中的序号表示调用的先后关系,同级之间的序号才有意义。
Redis 支持 Master-Slave(主从)模式,Redis Server 可以设置为另一个 Redis Server 的主机(从机),从机定期从主机拿数据。特殊的,一个从机同样可以设置为一个 Redis Server 的主机,这样一来 Master-Slave 的分布看起来就是一个有向无环图 DAG,如此形成 Redis Server 集群,无论是主机还是从机都是 Redis
Server,都可以提供服务。
在配置后,主机可负责读写服务,从机只负责读。Redis 提高这种配置方式,为的是让其支持数据的弱一致性,即最终一致性。在业务中,选择强一致性还是弱一致性,应该取决于具体的业务需求,像微博,完全可以使用弱一致性模型;像淘宝,可以选用强一致性模型。
Redis 主从复制的实现主要在 replication.c 中。
这篇文章涉及较多的代码,但我已经尽量删繁就简,达到能说明问题本质。为了保留代码的原生性并让读者能够阅读原生代码的注释,剖析 Redis 的几篇文章都没有删除代码中的英文注释,并已加注释。
二、积压空间
在《深入剖析 Redis AOF 持久化策略》中,介绍了更新缓存的概念,举一个例子:客户端发来命令:set name Jhon,这一数据更新被记录为:*3\r\n$3\r\nSET\r\n$4\r\nname\r\n$3\r\nJhon\r\n,并存储在更新缓存中。
同样,在主从连接中,也有更新缓存的概念。只是两者的用途不一样,前者被写入本地,后者被写入从机,这里我们把它称为积压空间。
更新缓存存储在 server.repl_backlog,Redis 将其作为一个环形空间来处理,这样做节省了空间,避免内存再分配的情况。
源码中是这么实现的:call()->propagate()->replicationFeedSlaves()
注释:命令真正执行的地方在 call() 中,call() 如果发现数据被修改(dirty),则传播 propagrate(),replicationFeedSlaves() 将修改记录写入积压空间和所有已连接的从机。
这里可能会有疑问:为什么把数据添加入积压空间,又把数据分发给所有的从机?为什么不仅仅将数据分发给所有从机呢?
因为有一些从机会因特殊情况(???)与主机断开连接,注意从机断开前有暂存主机的状态信息,因此这些断开的从机就没有及时收到更新的数据。Redis 为了让断开的从机在下次连接后能够获取更新数据,将更新数据加入了积压空间。从 replicationFeedSlaves() 实现来看,在线的 Slave 能马上收到数据更新记录;因某些原因暂时断开连接的 Slave,需要从积压空间中找回断开期间的数据更新记录。如果断开的时间足够长,Master
会拒绝 Slave 的部分同步请求,从而 Slave 只能进行全同步。
下面是源码注释:
| 159 |
Redis 主从同步有两种方式(或者所两个阶段):全同步和部分同步。
主从刚刚连接的时候,进行全同步;全同步结束后,进行部分同步。当然,如果有需要,Slave 在任何时候都可以发起全同步。Redis 策略是,无论如何,首先会尝试进行部分同步,如不成功,要求从机进行全同步,并启动 BGSAVE……BGSAVE 结束后,传输 RDB 文件;如果成功,允许从机进行部分同步,并传输积压空间中的数据。
下面这幅图,总结了主从同步的机制:
如需设置 Slave,Master 需要向 Slave 发送 SLAVEOF hostname port,从机接收到后会自动连接主机,注册相应读写事件(syncWithMaster())。
接着自动发起 PSYNC 请求 Master 进行全同步。无论如何,Redis 首先会尝试部分同步,如果失败才尝试全同步。而刚刚建立连接的 Master-Slave 需要全同步。
从机连接主机后,会主动发起 PSYNC 命令,从机会提供 master_runid 和 offset,主机验证 master_runid 和 offset 是否有效?master_runid 相当于主机身份验证码,用来验证从机上一次连接的主机,offset 是全局积压空间数据的偏移量。
验证未通过则,则进行全同步:主机返回 +FULLRESYNC master_runid offset(从机接收并记录 master_runid 和 offset,并准备接收 RDB 文件)接着启动 BGSAVE 生成 RDB 文件,BGSAVE 结束后,向从机传输,从而完成全同步。
如上所说,无论如何,Redis 首先会尝试部分同步。部分同步即把积压空间缓存的数据,即更新记录发送给从机。
从机连接主机后,会主动发起 PSYNC 命令,从机会提供 master_runid 和 offset,主机验证 master_runid 和 offset 是否有效?
验证通过则,进行部分同步:主机返回 +CONTINUE(从机接收后会注册积压数据接收事件),接着发送积压空间数据。
从机因为某些原因,譬如网络延迟(PING 超时,ACK 超时等),可能会断开与主机的连接。这时候,从机会尝试保存与主机连接的信息,譬如全局积压空间数据偏移量等,以便下一次的部分同步,并且从机会再一次尝试连接主机。注意一点,如果断开的时间足够长,部分同步肯定会失败的。
简单来说,主从同步就是 RDB 文件的上传下载;主机有小部分的数据修改,就把修改记录传播给每个从机。这篇文章详述了 Redis 主从复制的内部协议和机制。接下来的几篇关于 Redis 的文章,主要是其内部数据结构。
Redis的主从同步机制可以确保redis的master和slave之间的数据同步。按照同步内容的多少可以分为全同步和部分同步;按照同步的时机可以分为slave刚启动时的初始化同步和正常运行过程中的数据修改同步;本文将对这两种机制的流程进行分析。
全备份过程中,在slave启动时,会向其master发送一条SYNC消息,master收到slave的这条消息之后,将可能启动后台进程进行备份,备份完成之后就将备份的数据发送给slave,初始时的全同步机制是这样的:
(1)slave启动后向master发送同步指令SYNC,master接收到SYNC指令之后将调用该命令的处理函数syncCommand()进行同步处理;
(2)在函数syncCommand中,将调用函数rdbSaveBackground启动一个备份进程用于数据同步,如果已经有一个备份进程在运行了,就不会再重新启动了。
(3)备份进程将执行函数rdbSave()完成将redis的全部数据保存为rdb文件。
(4)在redis的时间事件函数serverCron(redis的时间处理函数是指它会定时被redis进行操作的函数)中,将对备份后的数据进行处理,在serverCron函数中将会检查备份进程是否已经执行完毕,如果备份进程已经完成备份,则调用函数backgroundSaveDoneHandler完成后续处理。
(5)在函数backgroundSaveDoneHandler中,首先更新master的各种状态,例如,备份成功还是失败,备份的时间等等。然后调用函数updateSlavesWaitingBgsave,将备份的rdb数据发送给等待的slave。
(6)在函数updateSlavesWaitingBgsave中,将遍历所有的等待此次备份的slave,将备份的rdb文件发送给每一个slave。另外,这里并不是立即就把数据发送过去,而是将为每个等待的slave注册写事件,并注册写事件的响应函数sendBulkToSlave,即当slave对应的socket能够发送数据时就调用函数sendBulkToSlave(),实际发送rdb文件的操作都在函数sendBulkToSlave中完成。
(7)sendBulkToSlave函数将把备份的rdb文件发送给slave。
上述函数调用过程如下图1所示:
图1 redis全备份时master部分的的函数调用过程
二、数据修改操作的同步
Redis的正常部署中一般都是一个master用于写操作,若干个slave用于读操作,另外定期的数据备份操作也是单独选址一个slave完成,这样可以最大程度发挥出redis的性能。在部署完成,各master\slave程序启动之后,首先进行第一阶段初始化时的全同步操作,全同步操作完成之后,后续所有写操作都是在master上进行,所有读操作都是在slave上进行,因此用户的写操作需要及时扩散到所有的slave以便保持数据最大程度上的同步。Redis的master-slave进程在正常运行期间更新操作(包括写、删除、更改操作)的同步方式如下:
(1)master接收到一条用户的操作后,将调用函数call函数来执行具体的操作函数(此过程可参考另一文档《redis命令执行流程分析》),在该函数中首先通过proc执行操作函数,然后将判断操作是否需要扩散到各slave,如果需要则调用函数propagate()来完成此操作。
(2)propagate()函数完成将一个操作记录到aof文件中或者扩散到其他slave中;在该函数中通过调用feedAppendOnlyFile()将操作记录到aof中,通过调用replicationFeedSlaves()将操作扩散到各slave中。
(3)函数feedAppendOnlyFile()中主要保存操作到aof文件,在该函数中首先将操作转换成redis内部的协议格式,并以字符串的形式存储,然后将字符串存储的操作追加到aof文件后。
(4)函数replicationFeedSlaves()主要将操作扩散到每一个slave中;在该函数中将遍历自己下面挂的每一个slave,以此对每个slave进行如下两步的处理:将slave的数据库切换到本操作所对应的数据库(如果slave的数据库id与当前操作的数据id不一致时才进行此操作);将命令和参数按照redis的协议格式写入到slave的回复缓存中。写入切换数据库的命令时将调用addReply,写入命令和参数时将调用addReplyMultiBulkLen和addReplyBulk,函数addReplyMultiBulkLen和addReplyBulk最终也将调用函数addReply。
(5)在函数addReply中将调用prepareClientToWrite()设置slave的socket写入事件处理函数sendReplyToClient(通过函数aeCreateFileEvent进行设置),这样一旦slave对应的socket发送缓存中有空间写入数据,即调用sendReplyToClient进行处理。
(6)函数sendReplyToClient()的主要功能是将slave中要发送的数据通过socket发出去。
图2、redis操作过程中数据同步的函数调用关系
图中的序号表示调用的先后关系,同级之间的序号才有意义。

相关文章推荐
- [转载] 深入剖析 redis 主从复制
- 深入剖析Redis主从复制
- 深入剖析 redis 主从复制
- 深入剖析Redis主从复制
- 面试宝典系列-读《深入学习Redis(3):主从复制》概要
- Redis源码剖析之主从复制
- redis深入—主从复制
- 深入学习Redis(3):主从复制
- 深入剖析Redis复制
- redis主从复制
- 记一次Redis设置主从复制时遇到的问题
- 构建高性能数据库缓存之redis主从复制 推荐
- Redis之高级命令、主从复制、哨兵
- liunx下搭建redis主从复制
- Redis 讲解系列之 Redis的主从复制(二)
- Redis的主从复制
- redis主从复制配置
- Redis主从复制和集群实验
- 【redis】主从复制
- redis的主从复制配置