YOLO:You Only Look Once: Unified, Real-Time Object Detection论文总结
2017-01-02 16:34
531 查看
一、摘要
之前的目标检测分方法都是通过各种方式将回归问题转化成分类问题解决,作者通过空间划分的包围盒以及相关类概率将目标检测直接设计成回归问题。作者使用了一个单独的神经网络来直接一次性从整张图像上预测出所有的包围盒以及类概率。另外,它的训练优化也能够实现端到端的形式。YOLO的优点包括:每秒45帧的速度,另一种小的结构的模型能达到每秒155帧;虽然产生更多的定位误差但是显然背景中的误检数少很多;能够学习到包括自然图像以及艺术图像在内的目标的一般性表示。
二、YOLO的主要内容
Introduction部分呢就是先介绍了一下目标检测的发展,之前的方法都是基于转化回归问题变成分类问题来做,而作者直接利用深度学习将目标检测设计成由图像像素映射到包围盒坐标以及类概率的回归问题,整个检测系统就是如下样子:
YOLO有这样几个好处:速度快,能基于全局信息进行预测(而之前的方法由于在窗口中预测,所以只能基于局部信息)以及能学习到更概括性的表示。接下来从检测方式,网络设计以及训练设计对YOLO进行总结。
1、Unified Detection
如图,首先该检测系统实现了同时预测全部类别的全部包围盒,这样使得端到端训练、实时检测以及高检测精度都得到了可能。为了更直观理解论文内容,现将内容标注到图像上来理解模型,如图。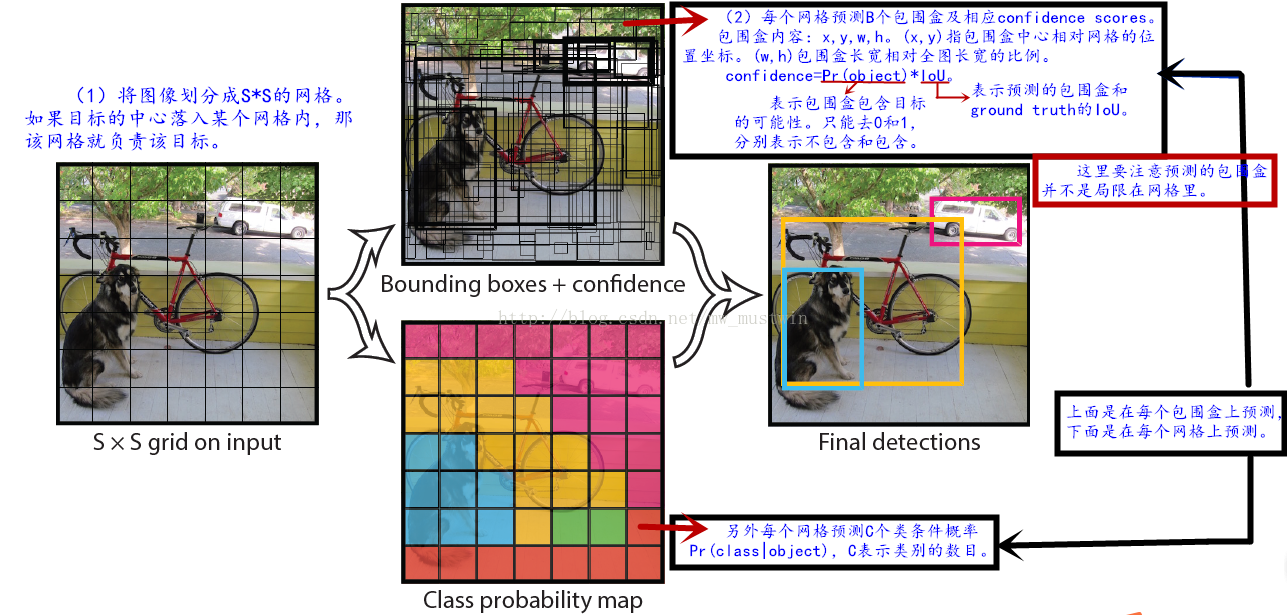
2、网络设计&训练
网络层结构参考的是GoogLeNet模型(20卷积+1平均池化+1全连接),稍微做了些修改,最终网络变成24卷积层+2全连接层。另外训练了一个YOLO的快速版本。只用了9个卷积层,并且每个卷积层的滤波器数量变少,其余参数没有差别。
用ILSVRC数据预训练24+2层的网络。将输入的分辨率有224*224提高到448*448来提供具有细密纹理的视觉信息。对最终的预测的包围盒的参数x, y, w, h做了设置,使得其范围都在0到1。修改了激活函数,和ReLu有一些区别。
另外就是loss函数的构建,体现了很多考虑在里面。我直接在loss函数上标记了。

另外设置了一些训练的参数以及防止过拟合的方式。
检测过程在检测最后采用非极大值抑制,因为会遇到大目标被多个网格检测到的情况。
YOLO网络构建产生的限制:每个网格只能预测2个目标,且这两个目标只能属于同一个类别,很显然这会导致很多成群出现的小的目标检测不到;对新的或者长宽比特别的目标检测困难;由于训练过程下采样的过程比较多,特征比较粗糙;虽然做了一些处理,但是小目标和大目标他们的损失函数一致对待会对小目标影响很大。
三、实验
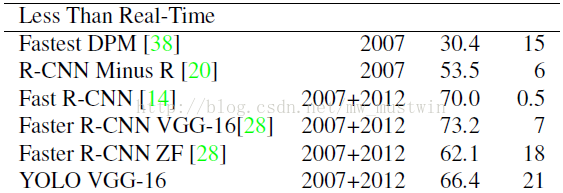
1、和实时的检测系统比较:精度提高特别多,速度也很快。
2、和一些还不算实时但是也蛮快的检测系统比较:速度优势很大,检测精度稍差。
3、用VOC2007进行了检测的错误分析:发现最大的问题在于定位的准确性稍差是YOLO主要的问题所在。也就是说如果想要从这篇文章出发,这边是一个入手点,比如在这个论文的检测最后加个boundingBox regression好像可以试试。
4、结合YOLO和fast R-CNN,利用YOLO来消除fast R-CNN带来的背景误检,提高检测精度。mAP在VOC2012达到了70.7%。
5、测试比较了艺术图片的检测效果。同样效果很好,说明YOLO有很好的适用性。而R-CNN在艺术图像上效果则比较差。

相关文章推荐
- 【目标检测】[论文阅读][yolo] You Only Look Once: Unified, Real-Time Object Detection
- Object Detection -- 论文YOLO(You Only Look Once: Unified, Real-Time Object Detection)解读
- 论文笔记(3)You Only Look Once:Unified, Real-Time Object Detection
- 对论文 You Only Look Once: Unified, Real-Time Object Detection 的理解 (一)
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 论文阅读:You Only Look Once: Unified, Real-Time Object Detection
- 【笔记】YOLO: You Only Look Once:Unified, Real-Time Object Detection
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 论文笔记|You Only Look Once: Unified, Real-Time Object Detection
- 【深度学习:目标检测】RCNN学习笔记(6):You Only Look Once(YOLO):Unified, Real-Time Object Detection
- You Only Look Once(YOLO):Unified, Real-Time Object Detection
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- 论文笔记 You Only Look Once: Unified, Real-Time Object Detection
- 论文提要“You Only Look Once: Unified, Real-Time Object Detection”
- 论文提要“You Only Look Once: Unified, Real-Time Object Detection”
- [深度学习论文笔记][Object Detection] You Only Look Once: Unified, Real-Time Object Detection
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
- RCNN学习笔记(6):You Only Look Once(YOLO):Unified, Real-Time Object Detection
- 论文阅读:You Only Look Once: Unified, Real-Time Object Detection
- 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection