Scrapy爬虫(六):多个爬虫组合实例
2016-12-27 14:07
513 查看
Scrapy爬虫(六):多个爬虫组合实例
Scrapy爬虫六多个爬虫组合实例需求分析
创建项目
运行爬虫
本章将实现多个爬虫共同工作的实例。
需求分析
我们现在有这么个需求,既要爬取音乐详情又要爬取乐评,既要爬取电影详情又要爬取影评,这个要怎么搞,难道是每一个需求就要创建一个项目么,如果按这种方式,我们就要创建四个项目,分别来爬取音乐、乐评、电影、影评,显然这么做的话,代码不仅有很多重合的部分,而且还不容易维护爬虫。其实是可以将多个爬虫组合在一个项目中的,不信你看项目的spiders目录,这个目录本身就是个复数,相信你也可以看出一些端倪。
抓取爬虫从豆瓣音乐、豆瓣电影的tag页,作为起始页开始爬取。
spider规则分析确定
豆瓣音乐、乐评
name = 'music' allowed_domains = ['music.douban.com'] start_urls = ['https://music.douban.com/tag/', 'https://music.douban.com/tag/?view=cloud' ] rules = (Rule(LinkExtractor(allow=r"/tag/((\d+)|([\u4e00-\u9fa5]+)|(\w+))$")), Rule(LinkExtractor(allow=r"/tag/((\d+)|([\u4e00-\u9fa5]+)|(\w+))\?start=\d+\&type=T$")), Rule(LinkExtractor(allow=r"/subject/\d+/reviews\?sort=time$")), Rule(LinkExtractor(allow=r"/subject/\d+/reviews\?sort=time\&start=\d+$")), Rule(LinkExtractor(allow=r"/subject/\d+/$"), callback="parse_music", follow=True), Rule(LinkExtractor(allow=r"/review/\d+/$"), callback="parse_review", follow=True), )
豆瓣电影、影评
name = 'video' allowed_domains = ['movie.douban.com'] start_urls = ['https://movie.douban.com/tag/', 'https://movie.douban.com/tag/?view=cloud' ] rules = (Rule(LinkExtractor(allow=r"/tag/((\d+)|([\u4e00-\u9fa5]+)|(\w+))$")), Rule(LinkExtractor(allow=r"/tag/((\d+)|([\u4e00-\u9fa5]+)|(\w+))\?start=\d+\&type=T$")), Rule(LinkExtractor(allow=r"/subject/\d+/reviews$")), Rule(LinkExtractor(allow=r"/subject/\d+/reviews\?start=\d+$")), Rule(LinkExtractor(allow=r"/subject/\d+/$"), callback="parse_video", follow=True), Rule(LinkExtractor(allow=r"/review/\d+/$"), callback="parse_review", follow=True), )
创建项目
使用命令scrapy startproject multi
MACBOOK:~ yancey$ scrapy startproject multi New Scrapy project 'multi', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in: /Users/yancey/multi You can start your first spider with: cd multi scrapy genspider example example.com
使用pycharm打开multi项目,目录结构如下:
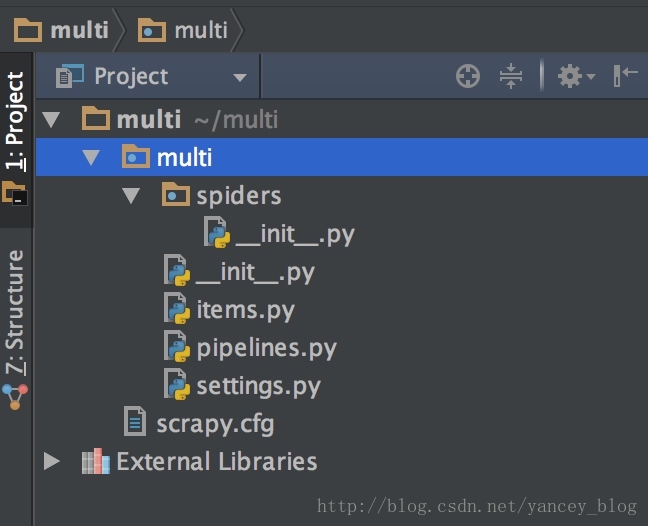
重写items.py,可以打开豆瓣的音乐、乐评、电影、影评,有这些元素。
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.org/en/latest/topics/items.html from scrapy import Item, Field # 音乐 class MusicItem(Item): music_name = Field() music_alias = Field() music_singer = Field() music_time = Field() music_rating = Field() music_votes = Field() music_tags = Field() music_url = Field() # 乐评 class MusicReviewItem(Item): review_title = Field() review_content = Field() review_author = Field() review_music = Field() review_time = Field() review_url = Field() # 电影 class VideoItem(Item): video_name = Field() video_alias = Field() video_actor = Field() video_year = Field() video_time = Field() video_rating = Field() video_votes = Field() video_tags = Field() video_url = Field() video_director = Field() video_type = Field() video_bigtype = Field() video_area = Field() video_language = Field() video_length = Field() video_writer = Field() video_desc = Field() video_episodes = Field() # 影评 class VideoReviewItem(Item): review_title = Field() review_content = Field() review_author = Field() review_video = Field() review_time = Field() review_url = Field()
新建两个spider分别为musicspider.py、videospider.py
# coding:utf-8
from scrapy.spider import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from multi.items import VideoItem, VideoReviewItem
from scrapy import log
import re
AREA = re.compile(r"制片国家/地区:</span> (.+?)<br>")
ALIAS = re.compile(r"又名:</span> (.+?)<br>")
LANGUAGE = re.compile(r"语言:</span> (.+?)<br>")
EPISODES = re.compile(r"集数:</span> (.+?)<br>")
LENGTH = re.compile(r"单集片长:</span> (.+?)<br>")
class VideoSpider(CrawlSpider):
name = 'video'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/tag/',
'https://movie.douban.com/tag/?view=cloud'
]
rules = (Rule(LinkExtractor(allow=r"/tag/((\d+)|([\u4e00-\u9fa5]+)|(\w+))$")),
Rule(LinkExtractor(allow=r"/tag/((\d+)|([\u4e00-\u9fa5]+)|(\w+))\?start=\d+\&type=T$")),
Rule(LinkExtractor(allow=r"/subject/\d+/reviews$")),
Rule(LinkExtractor(allow=r"/subject/\d+/reviews\?start=\d+$")),
Rule(LinkExtractor(allow=r"/subject/\d+/$"), callback="parse_video", follow=True),
Rule(LinkExtractor(allow=r"/review/\d+/$"), callback="parse_review", follow=True),
)
def parse_video(self, response):
item = VideoItem()
try:
item["video_url"] = response.url
item["video_name"] = ''.join(
response.xpath('//*[@id="content"]/h1/span[@property="v:itemreviewed"]/text()').extract())
try:
item["video_year"] = ''.join(
response.xpath('//*[@id="content"]/h1/span[@class="year"]/text()').extract()).replace(
"(", "").replace(")", "")
except Exception as e:
print('Exception:', e)
item['video_year'] = ''
introduction = response.xpath('//*[@id="link-report"]/span[@property="v:summary"]/text()').extract()
if introduction:
item["video_desc"] = ''.join(introduction).strip().replace("\r\n", " ")
else:
item["video_desc"] = ''.join(
response.xpath('//*[@id="link-report"]/span/text()').extract()).strip().replace("\r\n", " ")
item["video_director"] = "|".join(
response.xpath('//*[@id="info"]/span/span/a[@rel="v:directedBy"]/text()').extract())
item["video_writer"] = "|".join(
response.xpath('//*[@id="info"]/span[2]/span[2]/a/text()').extract())
item["video_actor"] = "|".join(response.xpath("//a[@rel='v:starring']/text()").extract())
item["video_type"] = "|".join(response.xpath('//*[@id="info"]/span[@property="v:genre"]/text()').extract())
S = "".join(response.xpath("//div[@id='info']").extract())
M = AREA.search(S)
if M is not None:
item["video_area"] = "|".join([area.strip() for area in M.group(1).split("/")])
else:
item['video_area'] = ''
A = "".join(response.xpath("//div[@id='info']").extract())
AL = ALIAS.search(A)
if AL is not None:
item["video_alias"] = "|".join([alias.strip() for alias in AL.group(1).split("/")])
else:
item["video_alias"] = ""
video_info = "".join(response.xpath("//div[@id='info']").extract())
language = LANGUAGE.search(video_info)
episodes = EPISODES.search(video_info)
length = LENGTH.search(video_info)
if language is not None:
item["video_language"] = "|".join([language.strip() for language in language.group(1).split("/")])
else:
item['video_language'] = ''
if length is not None:
item["video_length"] = "|".join([runtime.strip() for runtime in length.group(1).split("/")])
else:
item["video_length"] = "".join(
response.xpath('//*[@id="info"]/span[@property="v:runtime"]/text()').extract())
item['video_time'] = "/".join(
response.xpath('//*[@id="info"]/span[@property="v:initialReleaseDate"]/text()').extract())
if episodes is not None:
item['video_bigtype'] = "电视剧"
item["video_episodes"] = "|".join([episodes.strip() for episodes in episodes.group(1).split("/")])
else:
item['video_bigtype'] = "电影"
item['video_episodes'] = ''
item['video_tags'] = "|".join(
response.xpath('//*[@class="tags"]/div[@class="tags-body"]/a/text()').extract())
try:
item['video_rating'] = "".join(response.xpath(
'//*[@class="rating_self clearfix"]/strong/text()').extract())
item['video_votes'] = "".join(response.xpath(
'//*[@class="rating_self clearfix"]/div/div[@class="rating_sum"]/a/span/text()').extract())
except Exception as error:
item['video_rating'] = '0'
item['video_votes'] = '0'
log(error)
yield item
except Exception as error:
log(error)
def parse_review(self, response):
try:
item = VideoReviewItem()
item['review_title'] = "".join(response.xpath('//*[@property="v:summary"]/text()').extract())
content = "".join(
response.xpath('//*[@id="link-report"]/div[@property="v:description"]/text()').extract())
item['review_content'] = content.lstrip().rstrip().replace("\n", " ")
item['review_author'] = "".join(response.xpath('//*[@property = "v:reviewer"]/text()').extract())
item['review_video'] = "".join(response.xpath('//*[@class="main-hd"]/a[2]/text()').extract())
item['review_time'] = "".join(response.xpath('//*[@class="main-hd"]/p/text()').extract())
item['review_url'] = response.url
yield item
except Exception as error:
log(error)# coding:utf-8
from scrapy.spider import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from multi.items import MusicItem, MusicReviewItem
from scrapy import log
import re
class MusicSpider(CrawlSpider):
name = 'music'
allowed_domains = ['music.douban.com']
start_urls = ['https://music.douban.com/tag/',
'https://music.douban.com/tag/?view=cloud'
]
rules = (Rule(LinkExtractor(allow=r"/tag/((\d+)|([\u4e00-\u9fa5]+)|(\w+))$")),
Rule(LinkExtractor(allow=r"/tag/((\d+)|([\u4e00-\u9fa5]+)|(\w+))\?start=\d+\&type=T$")),
Rule(LinkExtractor(allow=r"/subject/\d+/reviews\?sort=time$")),
Rule(LinkExtractor(allow=r"/subject/\d+/reviews\?sort=time\&start=\d+$")),
Rule(LinkExtractor(allow=r"/subject/\d+/$"), callback="parse_music", follow=True),
Rule(LinkExtractor(allow=r"/review/\d+/$"), callback="parse_review", follow=True),
)
def parse_music(self, response):
item = MusicItem()
try:
item['music_name'] = response.xpath('//*[@id="wrapper"]/h1/span/text()').extract()[0]
content = "".join(response.xpath('//*[@id="info"]').extract())
info = response.xpath('//*[@id="info"]/span').extract()
item['music_alias'] = ""
item['music_singer'] = ""
item['music_time'] = ""
for i in range(0, len(info)):
if "又名" in info[i]:
if i == 0:
item['music_alias'] = response.xpath('//*[@id="info"]/text()').extract()[1] \
.replace("\xa0", "").replace("\n", "").rstrip()
elif i == 1:
item['music_alias'] = response.xpath('//*[@id="info"]/text()').extract()[2] \
.replace("\xa0", "").replace("\n", "").rstrip()
elif i == 2:
item['music_alias'] = response.xpath('//*[@id="info"]/text()').extract()[3] \
.replace("\xa0", "").replace("\n", "").rstrip()
else:
item['music_alias'] = ""
# break
if "表演者" in info[i]:
if i == 0:
item['music_singer'] = "|".join(
response.xpath('//*[@id="info"]/span[1]/span/a/text()').extract())
elif i == 1:
item['music_singer'] = "|".join(
response.xpath('//*[@id="info"]/span[2]/span/a/text()').extract())
elif i == 2:
item['music_singer'] = "|".join(
response.xpath('//*[@id="info"]/span[3]/span/a/text()').extract())
else:
item['music_singer'] = ""
# break
if "发行时间" in info[i]:
nbsp = re.findall(r"<span class=\"pl\">发行时间:</span>(.*?)<br>", content, re.S)
item['music_time'] = "".join(nbsp).replace("\xa0", "").replace("\n", "").replace(" ", "")
# break
try:
item['music_rating'] = "".join(response.xpath(
'//*[@class="rating_self clearfix"]/strong/text()').extract())
item['music_votes'] = "".join(response.xpath(
'//*[@class="rating_self clearfix"]/div/div[@class="rating_sum"]/a/span/text()').extract())
except Exception as error:
item['music_rating'] = '0'
item['music_votes'] = '0'
log(error)
item['music_tags'] = "|".join(response.xpath('//*[@id="db-tags-section"]/div/a/text()').extract())
item['music_url'] = response.url
yield item
except Exception as error:
log(error)
def parse_review(self, response):
try:
item = MusicReviewItem()
item['review_title'] = "".join(response.xpath('//*[@property="v:summary"]/text()').extract())
content = "".join(
response.xpath('//*[@id="link-report"]/div[@property="v:description"]/text()').extract())
item['review_content'] = content.lstrip().rstrip().replace("\n", " ")
item['review_author'] = "".join(response.xpath('//*[@property = "v:reviewer"]/text()').extract())
item['review_music'] = "".join(response.xpath('//*[@class="main-hd"]/a[2]/text()').extract())
item['review_time'] = "".join(response.xpath('//*[@class="main-hd"]/p/text()').extract())
item['review_url'] = response.url
yield item
except Exception as error:
log(error)spider中的xpath解析,我后面会讲到
settings.py配置
# -*- coding: utf-8 -*- BOT_NAME = 'multi' SPIDER_MODULES = ['multi.spiders'] NEWSPIDER_MODULE = 'multi.spiders' USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36' DOWNLOAD_DELAY = 2 # Obey robots.txt rules ROBOTSTXT_OBEY = True #遵守robots协议
创建run.py
# coding:utf-8
from scrapy import cmdline
cmdline.execute("scrapy crawl music".split())
cmdline.execute("scrapy crawl video".split())运行爬虫
pycharm运行run.py,结果如下:/Library/Frameworks/Python.framework/Versions/3.5/bin/python3.5 /Users/yancey/multi/multi/spiders/run.py
/Users/yancey/multi/multi/spiders/musicspider.py:3: ScrapyDeprecationWarning: Module `scrapy.spider` is deprecated, use `scrapy.spiders` instead
from scrapy.spider import CrawlSpider, Rule
/Users/yancey/multi/multi/spiders/musicspider.py:6: ScrapyDeprecationWarning: Module `scrapy.log` has been deprecated, Scrapy now relies on the builtin Python library for logging. Read the updated logging entry in the documentation to learn more.
from scrapy import log
2016-12-27 13:53:37 [scrapy] INFO: Scrapy 1.2.0 started (bot: multi)
2016-12-27 13:53:37 [scrapy] INFO: Overridden settings: {'DOWNLOAD_DELAY': 2, 'BOT_NAME': 'multi', 'USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36', 'SPIDER_MODULES': ['multi.spiders'], 'NEWSPIDER_MODULE': 'multi.spiders'}
2016-12-27 13:53:37 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.logstats.LogStats']
2016-12-27 13:53:37 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2016-12-27 13:53:37 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2016-12-27 13:53:37 [scrapy] INFO: Enabled item pipelines:
[]
2016-12-27 13:53:37 [scrapy] INFO: Spider opened
2016-12-27 13:53:37 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-12-27 13:53:39 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/> (referer: None)
2016-12-27 13:53:41 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/?view=cloud> (referer: None)
2016-12-27 13:53:41 [scrapy] DEBUG: Filtered duplicate request: <GET https://music.douban.com/tag/%E6%97%A5%E6%9C%AC> - no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicates)
2016-12-27 13:53:42 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/OST> (referer: https://music.douban.com/tag/) 2016-12-27 13:53:43 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/classical> (referer: https://music.douban.com/tag/) 2016-12-27 13:53:46 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/Alternative> (referer: https://music.douban.com/tag/) 2016-12-27 13:53:48 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/Metal> (referer: https://music.douban.com/tag/) 2016-12-27 13:53:51 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/%E5%8F%A4%E5%85%B8> (referer: https://music.douban.com/tag/) 2016-12-27 13:53:52 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/punk> (referer: https://music.douban.com/tag/) 2016-12-27 13:53:55 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/britpop> (referer: https://music.douban.com/tag/) 2016-12-27 13:53:56 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/%E7%BA%AF%E9%9F%B3%E4%B9%90> (referer: https://music.douban.com/tag/) 2016-12-27 13:53:59 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/%E4%B8%AD%E5%9B%BD%E6%91%87%E6%BB%9A> (referer: https://music.douban.com/tag/) 2016-12-27 13:54:02 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/%E7%8B%AC%E7%AB%8B%E9%9F%B3%E4%B9%90> (referer: https://music.douban.com/tag/) 2016-12-27 13:54:03 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/jazz> (referer: https://music.douban.com/tag/) 2016-12-27 13:54:05 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/%E7%94%B5%E5%BD%B1%E5%8E%9F%E5%A3%B0> (referer: https://music.douban.com/tag/) 2016-12-27 13:54:08 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/JPOP> (referer: https://music.douban.com/tag/) 2016-12-27 13:54:10 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/%E6%91%87%E6%BB%9A> (referer: https://music.douban.com/tag/) 2016-12-27 13:54:11 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/rock> (referer: https://music.douban.com/tag/) 2016-12-27 13:54:14 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/%E6%9E%97%E6%B5%B7> (referer: https://music.douban.com/tag/) 2016-12-27 13:54:16 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/tag/%E6%9D%B1%E6%96%B9> (referer: https://music.douban.com/tag/?view=cloud) 2016-12-27 13:54:19 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/subject/26931992/> (referer: https://music.douban.com/tag/OST) 2016-12-27 13:54:19 [scrapy] DEBUG: Scraped from <200 https://music.douban.com/subject/26931992/> {'music_alias': '电影《摆渡人》岁月版主题曲',
'music_name': '十年',
'music_rating': '6.4',
'music_singer': '梁朝伟|李宇春',
'music_tags': '梁朝伟|李宇春|十年|OST|单曲|2016|电影歌曲|华语',
'music_time': '2016-12-15',
'music_url': 'https://music.douban.com/subject/26931992/',
'music_votes': '231'}
2016-12-27 13:54:19 [scrapy] DEBUG: Filtered offsite request to 'movie.douban.com': <GET https://movie.douban.com/subject/25911694/> 2016-12-27 13:54:21 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/subject/3698231/> (referer: https://music.douban.com/tag/classical) 2016-12-27 13:54:21 [scrapy] DEBUG: Scraped from <200 https://music.douban.com/subject/3698231/> {'music_alias': 'Bach: Cantatas/Handel: Arias',
'music_name': 'The Art of Alfred Deller (Alfred Deller Edition, No. 7)',
'music_rating': '8.7',
'music_singer': 'Alfred Deller',
'music_tags': 'Bach|Cantatas|countertenor|classical|Deller|Handel|baroque|古典',
'music_time': '1997-6-24',
'music_url': 'https://music.douban.com/subject/3698231/',
'music_votes': '27'}
2016-12-27 13:54:23 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/subject/26842972/> (referer: https://music.douban.com/tag/Alternative) 2016-12-27 13:54:23 [scrapy] DEBUG: Scraped from <200 https://music.douban.com/subject/26842972/> {'music_alias': '',
'music_name': 'Skiptracing',
'music_rating': '7.9',
'music_singer': 'Mild High Club',
'music_tags': 'Alternative|2016|MildHighClub|Electronic|US|美国|Adult-Contemporary|AOR',
'music_time': '2016-09-02',
'music_url': 'https://music.douban.com/subject/26842972/',
'music_votes': '29'}
2016-12-27 13:54:25 [scrapy] DEBUG: Crawled (200) <GET https://music.douban.com/subject/5404211/> (referer: https://music.douban.com/tag/Metal) 2016-12-27 13:54:25 [scrapy] DEBUG: Scraped from <200 https://music.douban.com/subject/5404211/> {'music_alias': '',
'music_name': 'Surtur Rising',
'music_rating': '8.5',
'music_singer': 'Amon Amarth',
'music_tags': 'Melodic-Death-Metal|Viking-Metal|瑞典|2011|Metal|VikingMetal|Sweden|Amon_Amarth',
'music_time': '2011-03-23',
'music_url': 'https://music.douban.com/subject/5404211/',
'music_votes': '173'}
... ...github地址
专题概要
爬虫简介
scrapy架构及原理
imdb.cn爬虫实例
有限爬取深度实例
多个爬虫组合实例
爬虫数据存储实例
中间件的使用实例
scrapy的调试技巧
爬虫总结以及扩展

相关文章推荐
- Scrapy爬虫(八):中间件的使用实例
- Scrapy爬虫从入门到实例精讲(中)
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
- Scrapy爬虫实例——校花网
- python爬虫框架scrapy一次执行多个爬虫文件
- python爬虫框架scrapy实例详解
- Scrapy 爬虫实例 抓取豆瓣小组信息并保存到mongodb中 推荐
- scrapy中同时启动多个爬虫
- 给定一个字符串,里面用空格分开为多个(>=6)部分组合,如:01 02 03 04 05 06 07 …… 写一个函数返回任意6个组合的字符串: 输出格式实例: 01 02 03 04 05 06 0
- python爬虫框架scrapy实例详解
- scrapy爬虫框架实例一,爬取自己博客
- scrapy爬虫实例
- scrapy google爬虫实例
- scrapy爬虫完整实例
- scrapy爬虫框架实例二
- Scrapy爬虫入门实例
- Scrapy爬虫从入门到实例精讲(下)
- scrapy爬虫框架入门实例
- python爬虫框架scrapy实例详解
- Scrapy爬虫笔记【5-实例一:爬豆瓣】