K_Means算法Java粗略实现讲解
2016-12-19 00:00
323 查看
package k_means;
import java.util.ArrayList;
import java.util.List;
//使用canopy算法可以优化K_Means算法,优化后的和完整的想要就联系我,哈哈,但是核心思想这段 //代码都有,就是写的有点冗余
//注:只有部分核心代码,操作数据部分,加载json数据部分暂不公开
//该算法只是用了简单方法,大致实现,看看下面的思想最重要,哈哈
//优化聚类中心点
//下面显示的自己随机模拟的数据,没有聚类和聚类之后的情况
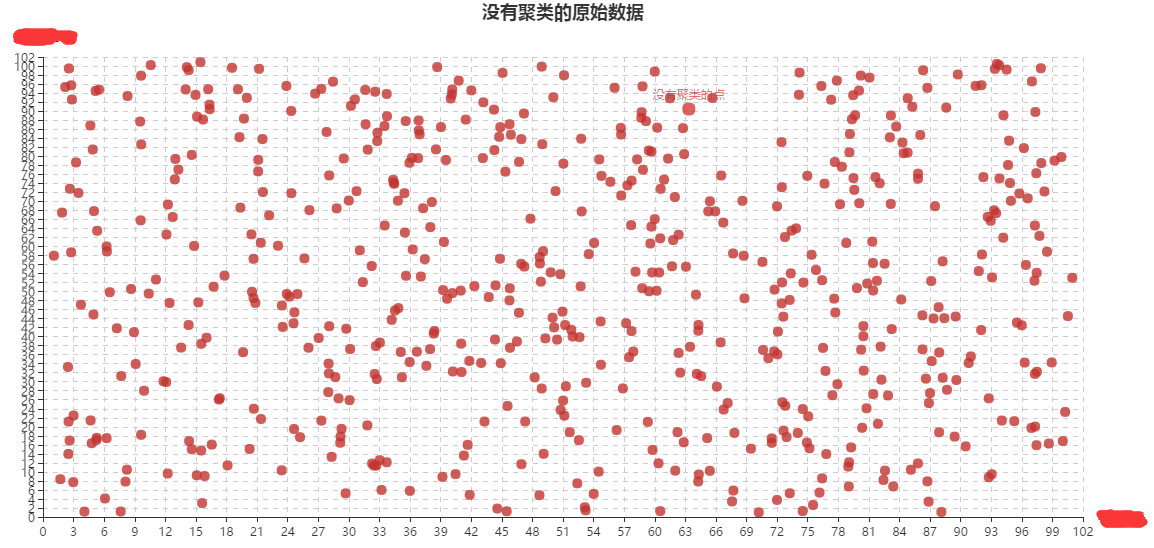
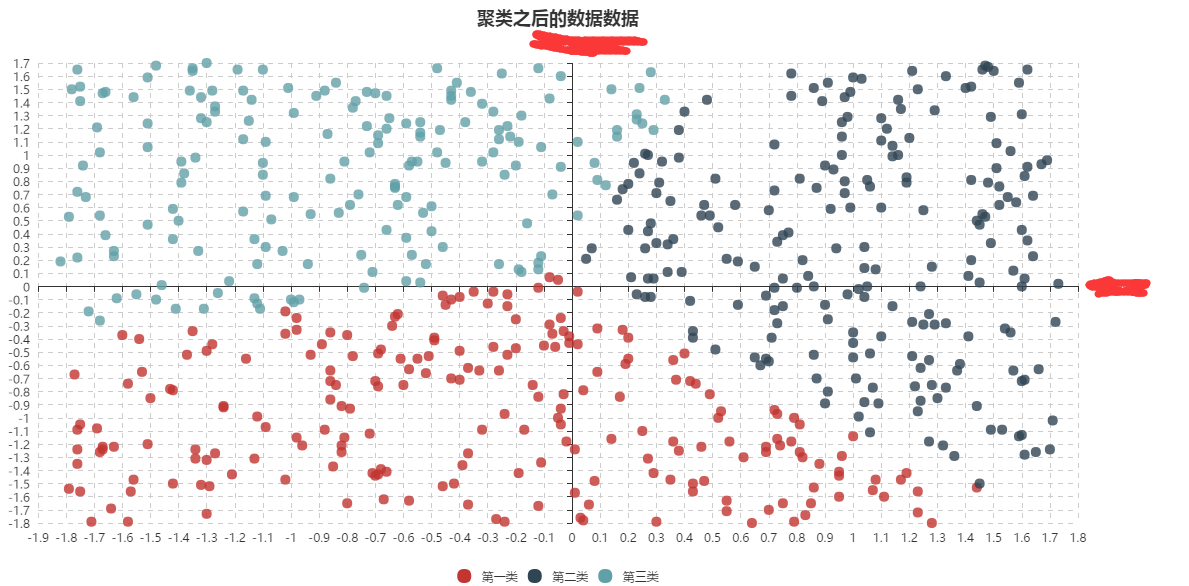
选取的方法
//1:先随机选取一个聚类中心A
//2:选取离第一个随机选取的聚类中心A最远的点作为第二个聚类中心
//3:分别计算所有样本与前面所有样本中心的距离,
//得到一个与前面聚类中心最近点的集合,选取集合中距离最大的点作为新的聚类中心点
//4:当聚类中心点的个数小于指定个数时,重复过程3
public class Optimize {
private static List<K_meansBean> list=ModelDb.SelectStandard();
//自己定义三个样本中心
private static K_meansBean kCenterOne;
private static K_meansBean kCenterTwo;
private static K_meansBean kCenterThree;
//迭代次数
private static int kTime=1;
//定义三个集合,用来存放三个簇的样本数据
private static List<K_meansBean> listKOne=new ArrayList<>();
private static List<K_meansBean> listKTwo=new ArrayList<>();
private static List<K_meansBean> listKThree=new ArrayList<>();
public static void main(String args){
//得到存放了所有样本数据
//List<K_meansBean> list=ModelDb.Select();
//System.out.println(list.size());//对应样本数量
//将标准化后的数据插入到数据库
//List<K_meansBean> listStandard=KmeansStandard(list);
//ModelDb.InsertKmeansdard(listStandard);
//线输出所有数据
System.out.println("没有聚类之前的的标准化之后数据:");
for(int i=0;i<list.size();i++){
if(i%8==0&&i!=0){
System.out.println();
}
System.out.print(list.get(i).getStudyTime()+","+list.get(i).getPalyGameTime()+" ");
}
while(true){
startKmeans(list);
//新的聚类中心
List<K_meansBean> newCenter=getNewCenter(listKOne, listKTwo, listKThree);
if(newCenter.get(0).getPalyGameTime()==kCenterOne.getPalyGameTime()
&&newCenter.get(0).getStudyTime()==kCenterOne.getStudyTime()
&&newCenter.get(1).getPalyGameTime()==kCenterTwo.getPalyGameTime()
&&newCenter.get(1).getStudyTime()==kCenterTwo.getStudyTime()
&&newCenter.get(2).getPalyGameTime()==kCenterThree.getPalyGameTime()
&&newCenter.get(2).getStudyTime()==kCenterThree.getStudyTime()){
//结束之前打印聚类结果
System.out.println();
System.out.println("聚类结束后的情况:");
System.out.println("第一类:");
String strOne="[{\"optimizeOne\":[";//写成json格式的文件
for(int i=0;i<listKOne.size();i++){
if(i%5==0&&i!=0){
System.out.println();
}
if(i!=listKOne.size()-1)
{
strOne=strOne+"["+listKOne.get(i).getStudyTime()+","+listKOne.get(i).getPalyGameTime()+"],";
}
else{
strOne=strOne+"["+listKOne.get(i).getStudyTime()+","+listKOne.get(i).getPalyGameTime()+"]";
}
System.out.print(listKOne.get(i).getStudyTime()+","+listKOne.get(i).getPalyGameTime()+" ");
}
strOne=strOne+"]},";
//WriteJson.saveJsonData("optimizeOne",strOne);
System.out.println();
System.out.println("第二类:");
strOne=strOne+"{\"optimizeTwo\":[";//写成json格式的文件
for(int i=0;i<listKTwo.size();i++){
if(i%5==0&&i!=0){
System.out.println();
}
if(i!=listKTwo.size()-1)
{
strOne=strOne+"["+listKTwo.get(i).getStudyTime()+","+listKTwo.get(i).getPalyGameTime()+"],";
}
else{
strOne=strOne+"["+listKTwo.get(i).getStudyTime()+","+listKTwo.get(i).getPalyGameTime()+"]";
}
System.out.print(listKTwo.get(i).getStudyTime()+","+listKTwo.get(i).getPalyGameTime()+" ");
}
strOne=strOne+"]},";
//WriteJson.saveJsonData("optimizeTwo",strTwo);
System.out.println();
System.out.println("第三类:");
strOne=strOne+"{\"optimizeThree\":[";//写成json格式的文件
for(int i=0;i<listKThree.size();i++){
if(i%5==0&&i!=0){
System.out.println();
}
if(i!=listKThree.size()-1)
{
strOne=strOne+"["+listKThree.get(i).getStudyTime()+","+listKThree.get(i).getPalyGameTime()+"],";
}
else{
strOne=strOne+"["+listKThree.get(i).getStudyTime()+","+listKThree.get(i).getPalyGameTime()+"]";
}
System.out.print(listKThree.get(i).getStudyTime()+","+listKThree.get(i).getPalyGameTime()+" ");
}
strOne=strOne+"]}]";
WriteJson.saveJsonData("optimize",strOne);
return;
}
else{
kTime=kTime+1;
}
}
}
//开始聚类
public static void startKmeans(List<K_meansBean> list){
if(kTime==1){//第一次先自己随便定义三个聚类中心
kCenterOne=getOptimizeCenter(list).get(0);
kCenterTwo=getOptimizeCenter(list).get(1);
kCenterThree=getOptimizeCenter(list).get(2);
System.out.println("第"+kTime+"次聚类:"+kTime);//=================================================
}
else{
List<K_meansBean> newKcenter=getNewCenter(listKOne, listKTwo, listKThree);
listKOne.clear();
listKTwo.clear();
listKThree.clear();
kCenterOne=newKcenter.get(0);
kCenterTwo=newKcenter.get(1);
kCenterThree=newKcenter.get(2);
System.out.println("第"+kTime+"次聚类:"+kTime);//=================================================
}
//定义三个变量存放临时距离
double distanceOne=0;
double distanceTwo=0;
double distanceThree=0;
//定义一个变量用于判断某个样本应该放放入那个集合,用1,2,3分别方式因该放入那个对应集合
int judge=1;
//便利标准化后的样本,开始聚类
for(int i=0;i<list.size();i++){
distanceOne=getDistance(kCenterOne, list.get(i));
distanceTwo=getDistance(kCenterTwo, list.get(i));
distanceThree=getDistance(kCenterThree, list.get(i));
judge=getMinDistance(distanceOne,distanceTwo,distanceThree);
switch(judge){//判断judge值,往相应集合里面添加样本
case 1:
listKOne.add(list.get(i));//这里得到三个聚类后的集合
break;
case 2:
listKTwo.add(list.get(i));
break;
case 3:
listKThree.add(list.get(i));
break;
default:break;
}
}
}
//得到样本均值
public static double getStudyMean(List<K_meansBean> list){
double ave=new double[2];
ave[0]=0;//学习时长均值
ave[1]=0;//打游戏时长均值
for(int i=0;i<list.size();i++){
ave[0]+=list.get(i).getStudyTime();
ave[1]+=list.get(i).getPalyGameTime();
}
ave[0]=ave[0]/list.size();
ave[1]=ave[1]/list.size();
//System.out.println(df.format(arr[0])+"---"+arr[1]);
//arr[0]=df.format(arr[0]);//这里报错,很懵逼********************************
return ave;
}
//得到样本方差
public static double getVariance(List<K_meansBean> list){
double ave=getStudyMean(list);
double variance=new double[2];
variance[0]=0;//学习时长方差
variance[1]=0;//打游戏时长方差
for(int i=0;i<list.size();i++){
variance[0]+=Math.pow(Math.abs(list.get(i).getStudyTime()-ave[0]),2);
variance[1]+=Math.pow(Math.abs(list.get(i).getPalyGameTime()-ave[1]),2);
}
variance[0]=variance[0]/(list.size());
variance[1]=variance[1]/(list.size());
return variance;
}
//对数据进行标准化
public static List<K_meansBean> KmeansStandard(List<K_meansBean> list){
List<K_meansBean> listStandard=new ArrayList<>();
double ave=getStudyMean(list);
double variance=getVariance(list);
for(int i=0;i<list.size();i++){
K_meansBean k_meansBean=new K_meansBean();
k_meansBean.setStudyTime((list.get(i).getStudyTime()-ave[0])/Math.sqrt(variance[0]));
k_meansBean.setPalyGameTime((list.get(i).getPalyGameTime()-ave[1])/Math.sqrt(variance[1]));
listStandard.add(k_meansBean);
}
return listStandard;
}
//计算两个样本之间的距离
public static double getDistance(K_meansBean kCenter,K_meansBean sample){
double distance=0;
distance=Math.sqrt(Math.pow((kCenter.getStudyTime() - sample.getStudyTime()), 2.0) + Math.pow((kCenter.getPalyGameTime() - sample.getPalyGameTime()), 2.0));
//小数点后保留两位
distance=(double)(Math.round(distance*100)/100.0);
return distance;
}
//得到临时 比较最小距离
public static int getMinDistance(double distanceOne,double distanceTwo,double distanceThree){
double min=distanceOne;
int i=1;
if(distanceTwo<min){
min=distanceTwo;
i=2;
}
if(distanceThree<min){
min=distanceThree;
i=3;
}
return i;
}
//优化方法得到聚类中心
public static List<K_meansBean> getOptimizeCenter(List<K_meansBean> allSample){
int k=3;//假设输入的k=3,有三个样本中心
List<K_meansBean> list=new ArrayList<>();
list.add(allSample.get(0));//先随机选取一个作为样本中心
list.add(getMax(allSample.get(0),allSample));//选取离第一个随机选取的聚类中心最远的点作为第二个聚类中心
//选取接下来更多的聚类中心
//分别计算所有样本与前面所有样本中心的距离,
//得到一个与前面聚类中心最近点的集合,选取集合中距离最大的点作为新的聚类中心点
for(int i=0;i<k-2;i++){
list.add(getMin(list,allSample));//*****************想下这里有把list本身传入进去是否会有问题
}
return list;
}
//得到样本间最小距离点
public static K_meansBean getMin(List<K_meansBean> list,List<K_meansBean> allSample){
double min=0;
double distance=new double[2];
int pointNum=new int[2];
double maxDistance=0;
int maxPoint=0;
for(int i=0;i<list.size();i++){
for(int j=0;j<allSample.size();j++){
distance=getDistance(list.get(i),allSample.get(j));
if (min>distance[i]) {
min=distance[i];
pointNum[i]=j;
}
}
distance[i]=min;
}
for(int i=0;i<list.size();i++){
if(maxDistance<distance[i]){
maxDistance=distance[i];
maxPoint=i;
}
}
return allSample.get(maxPoint);
}
//得到样本间最大距离点
public static K_meansBean getMax(K_meansBean kCenterOne,List<K_meansBean> list){
double max=0;
double distance=0;
int maxPoint=0;
for(int i=0;i<list.size();i++){
distance=getDistance(kCenterOne,list.get(i));
if (max<distance) {
max=distance;
maxPoint=i;
}
}
return list.get(maxPoint);
}
//重新计算聚类中心,返回三个簇的重新计算后的聚类中心
public static List<K_meansBean> getNewCenter(List<K_meansBean> listOne,List<K_meansBean> listTwo,List<K_meansBean> listThree){
List<K_meansBean> newKcenter=new ArrayList<>();
double listOneCenterX=0;
double listOneCenterY=0;
double listTwoCenterX=0;
double listTwoCenterY=0;
double listThreeCenterX=0;
double listThreeCenterY=0;
K_meansBean k_meansBeanOne=new K_meansBean();
K_meansBean k_meansBeanTwo=new K_meansBean();
K_meansBean k_meansBeanThree=new K_meansBean();
for(int i=0;i<listOne.size();i++){
listOneCenterX+=listOne.get(i).getStudyTime();
listOneCenterY+=listOne.get(i).getPalyGameTime();
}
for(int j=0;j<listTwo.size();j++){
listTwoCenterX+=listTwo.get(j).getStudyTime();
listTwoCenterY+=listTwo.get(j).getPalyGameTime();
}
for(int k=0;k<listThree.size();k++){
listThreeCenterX+=listThree.get(k).getStudyTime();
listThreeCenterY+=listThree.get(k).getPalyGameTime();
}
listOneCenterX=(double)(Math.round((listOneCenterX/listOne.size())*100)/100.0);
listOneCenterY=(double)(Math.round((listOneCenterY/listOne.size())*100)/100.0);
listTwoCenterX=(double)(Math.round((listTwoCenterX/listTwo.size())*100)/100.0);
listTwoCenterY=(double)(Math.round((listTwoCenterY/listTwo.size())*100)/100.0);
listThreeCenterX=(double)(Math.round((listThreeCenterX/listThree.size())*100)/100.0);
listThreeCenterY=(double)(Math.round((listThreeCenterY/listThree.size())*100)/100.0);
k_meansBeanOne.setStudyTime(listOneCenterX);
k_meansBeanOne.setPalyGameTime(listOneCenterY);
k_meansBeanTwo.setStudyTime(listTwoCenterX);
k_meansBeanTwo.setPalyGameTime(listTwoCenterY);
k_meansBeanThree.setStudyTime(listThreeCenterX);
k_meansBeanThree.setPalyGameTime(listThreeCenterY);
newKcenter.add(k_meansBeanOne);
newKcenter.add(k_meansBeanTwo);
newKcenter.add(k_meansBeanThree);
return newKcenter;
}
import java.util.ArrayList;
import java.util.List;
//使用canopy算法可以优化K_Means算法,优化后的和完整的想要就联系我,哈哈,但是核心思想这段 //代码都有,就是写的有点冗余
//注:只有部分核心代码,操作数据部分,加载json数据部分暂不公开
//该算法只是用了简单方法,大致实现,看看下面的思想最重要,哈哈
//优化聚类中心点
//下面显示的自己随机模拟的数据,没有聚类和聚类之后的情况


选取的方法
//1:先随机选取一个聚类中心A
//2:选取离第一个随机选取的聚类中心A最远的点作为第二个聚类中心
//3:分别计算所有样本与前面所有样本中心的距离,
//得到一个与前面聚类中心最近点的集合,选取集合中距离最大的点作为新的聚类中心点
//4:当聚类中心点的个数小于指定个数时,重复过程3
public class Optimize {
private static List<K_meansBean> list=ModelDb.SelectStandard();
//自己定义三个样本中心
private static K_meansBean kCenterOne;
private static K_meansBean kCenterTwo;
private static K_meansBean kCenterThree;
//迭代次数
private static int kTime=1;
//定义三个集合,用来存放三个簇的样本数据
private static List<K_meansBean> listKOne=new ArrayList<>();
private static List<K_meansBean> listKTwo=new ArrayList<>();
private static List<K_meansBean> listKThree=new ArrayList<>();
public static void main(String args){
//得到存放了所有样本数据
//List<K_meansBean> list=ModelDb.Select();
//System.out.println(list.size());//对应样本数量
//将标准化后的数据插入到数据库
//List<K_meansBean> listStandard=KmeansStandard(list);
//ModelDb.InsertKmeansdard(listStandard);
//线输出所有数据
System.out.println("没有聚类之前的的标准化之后数据:");
for(int i=0;i<list.size();i++){
if(i%8==0&&i!=0){
System.out.println();
}
System.out.print(list.get(i).getStudyTime()+","+list.get(i).getPalyGameTime()+" ");
}
while(true){
startKmeans(list);
//新的聚类中心
List<K_meansBean> newCenter=getNewCenter(listKOne, listKTwo, listKThree);
if(newCenter.get(0).getPalyGameTime()==kCenterOne.getPalyGameTime()
&&newCenter.get(0).getStudyTime()==kCenterOne.getStudyTime()
&&newCenter.get(1).getPalyGameTime()==kCenterTwo.getPalyGameTime()
&&newCenter.get(1).getStudyTime()==kCenterTwo.getStudyTime()
&&newCenter.get(2).getPalyGameTime()==kCenterThree.getPalyGameTime()
&&newCenter.get(2).getStudyTime()==kCenterThree.getStudyTime()){
//结束之前打印聚类结果
System.out.println();
System.out.println("聚类结束后的情况:");
System.out.println("第一类:");
String strOne="[{\"optimizeOne\":[";//写成json格式的文件
for(int i=0;i<listKOne.size();i++){
if(i%5==0&&i!=0){
System.out.println();
}
if(i!=listKOne.size()-1)
{
strOne=strOne+"["+listKOne.get(i).getStudyTime()+","+listKOne.get(i).getPalyGameTime()+"],";
}
else{
strOne=strOne+"["+listKOne.get(i).getStudyTime()+","+listKOne.get(i).getPalyGameTime()+"]";
}
System.out.print(listKOne.get(i).getStudyTime()+","+listKOne.get(i).getPalyGameTime()+" ");
}
strOne=strOne+"]},";
//WriteJson.saveJsonData("optimizeOne",strOne);
System.out.println();
System.out.println("第二类:");
strOne=strOne+"{\"optimizeTwo\":[";//写成json格式的文件
for(int i=0;i<listKTwo.size();i++){
if(i%5==0&&i!=0){
System.out.println();
}
if(i!=listKTwo.size()-1)
{
strOne=strOne+"["+listKTwo.get(i).getStudyTime()+","+listKTwo.get(i).getPalyGameTime()+"],";
}
else{
strOne=strOne+"["+listKTwo.get(i).getStudyTime()+","+listKTwo.get(i).getPalyGameTime()+"]";
}
System.out.print(listKTwo.get(i).getStudyTime()+","+listKTwo.get(i).getPalyGameTime()+" ");
}
strOne=strOne+"]},";
//WriteJson.saveJsonData("optimizeTwo",strTwo);
System.out.println();
System.out.println("第三类:");
strOne=strOne+"{\"optimizeThree\":[";//写成json格式的文件
for(int i=0;i<listKThree.size();i++){
if(i%5==0&&i!=0){
System.out.println();
}
if(i!=listKThree.size()-1)
{
strOne=strOne+"["+listKThree.get(i).getStudyTime()+","+listKThree.get(i).getPalyGameTime()+"],";
}
else{
strOne=strOne+"["+listKThree.get(i).getStudyTime()+","+listKThree.get(i).getPalyGameTime()+"]";
}
System.out.print(listKThree.get(i).getStudyTime()+","+listKThree.get(i).getPalyGameTime()+" ");
}
strOne=strOne+"]}]";
WriteJson.saveJsonData("optimize",strOne);
return;
}
else{
kTime=kTime+1;
}
}
}
//开始聚类
public static void startKmeans(List<K_meansBean> list){
if(kTime==1){//第一次先自己随便定义三个聚类中心
kCenterOne=getOptimizeCenter(list).get(0);
kCenterTwo=getOptimizeCenter(list).get(1);
kCenterThree=getOptimizeCenter(list).get(2);
System.out.println("第"+kTime+"次聚类:"+kTime);//=================================================
}
else{
List<K_meansBean> newKcenter=getNewCenter(listKOne, listKTwo, listKThree);
listKOne.clear();
listKTwo.clear();
listKThree.clear();
kCenterOne=newKcenter.get(0);
kCenterTwo=newKcenter.get(1);
kCenterThree=newKcenter.get(2);
System.out.println("第"+kTime+"次聚类:"+kTime);//=================================================
}
//定义三个变量存放临时距离
double distanceOne=0;
double distanceTwo=0;
double distanceThree=0;
//定义一个变量用于判断某个样本应该放放入那个集合,用1,2,3分别方式因该放入那个对应集合
int judge=1;
//便利标准化后的样本,开始聚类
for(int i=0;i<list.size();i++){
distanceOne=getDistance(kCenterOne, list.get(i));
distanceTwo=getDistance(kCenterTwo, list.get(i));
distanceThree=getDistance(kCenterThree, list.get(i));
judge=getMinDistance(distanceOne,distanceTwo,distanceThree);
switch(judge){//判断judge值,往相应集合里面添加样本
case 1:
listKOne.add(list.get(i));//这里得到三个聚类后的集合
break;
case 2:
listKTwo.add(list.get(i));
break;
case 3:
listKThree.add(list.get(i));
break;
default:break;
}
}
}
//得到样本均值
public static double getStudyMean(List<K_meansBean> list){
double ave=new double[2];
ave[0]=0;//学习时长均值
ave[1]=0;//打游戏时长均值
for(int i=0;i<list.size();i++){
ave[0]+=list.get(i).getStudyTime();
ave[1]+=list.get(i).getPalyGameTime();
}
ave[0]=ave[0]/list.size();
ave[1]=ave[1]/list.size();
//System.out.println(df.format(arr[0])+"---"+arr[1]);
//arr[0]=df.format(arr[0]);//这里报错,很懵逼********************************
return ave;
}
//得到样本方差
public static double getVariance(List<K_meansBean> list){
double ave=getStudyMean(list);
double variance=new double[2];
variance[0]=0;//学习时长方差
variance[1]=0;//打游戏时长方差
for(int i=0;i<list.size();i++){
variance[0]+=Math.pow(Math.abs(list.get(i).getStudyTime()-ave[0]),2);
variance[1]+=Math.pow(Math.abs(list.get(i).getPalyGameTime()-ave[1]),2);
}
variance[0]=variance[0]/(list.size());
variance[1]=variance[1]/(list.size());
return variance;
}
//对数据进行标准化
public static List<K_meansBean> KmeansStandard(List<K_meansBean> list){
List<K_meansBean> listStandard=new ArrayList<>();
double ave=getStudyMean(list);
double variance=getVariance(list);
for(int i=0;i<list.size();i++){
K_meansBean k_meansBean=new K_meansBean();
k_meansBean.setStudyTime((list.get(i).getStudyTime()-ave[0])/Math.sqrt(variance[0]));
k_meansBean.setPalyGameTime((list.get(i).getPalyGameTime()-ave[1])/Math.sqrt(variance[1]));
listStandard.add(k_meansBean);
}
return listStandard;
}
//计算两个样本之间的距离
public static double getDistance(K_meansBean kCenter,K_meansBean sample){
double distance=0;
distance=Math.sqrt(Math.pow((kCenter.getStudyTime() - sample.getStudyTime()), 2.0) + Math.pow((kCenter.getPalyGameTime() - sample.getPalyGameTime()), 2.0));
//小数点后保留两位
distance=(double)(Math.round(distance*100)/100.0);
return distance;
}
//得到临时 比较最小距离
public static int getMinDistance(double distanceOne,double distanceTwo,double distanceThree){
double min=distanceOne;
int i=1;
if(distanceTwo<min){
min=distanceTwo;
i=2;
}
if(distanceThree<min){
min=distanceThree;
i=3;
}
return i;
}
//优化方法得到聚类中心
public static List<K_meansBean> getOptimizeCenter(List<K_meansBean> allSample){
int k=3;//假设输入的k=3,有三个样本中心
List<K_meansBean> list=new ArrayList<>();
list.add(allSample.get(0));//先随机选取一个作为样本中心
list.add(getMax(allSample.get(0),allSample));//选取离第一个随机选取的聚类中心最远的点作为第二个聚类中心
//选取接下来更多的聚类中心
//分别计算所有样本与前面所有样本中心的距离,
//得到一个与前面聚类中心最近点的集合,选取集合中距离最大的点作为新的聚类中心点
for(int i=0;i<k-2;i++){
list.add(getMin(list,allSample));//*****************想下这里有把list本身传入进去是否会有问题
}
return list;
}
//得到样本间最小距离点
public static K_meansBean getMin(List<K_meansBean> list,List<K_meansBean> allSample){
double min=0;
double distance=new double[2];
int pointNum=new int[2];
double maxDistance=0;
int maxPoint=0;
for(int i=0;i<list.size();i++){
for(int j=0;j<allSample.size();j++){
distance=getDistance(list.get(i),allSample.get(j));
if (min>distance[i]) {
min=distance[i];
pointNum[i]=j;
}
}
distance[i]=min;
}
for(int i=0;i<list.size();i++){
if(maxDistance<distance[i]){
maxDistance=distance[i];
maxPoint=i;
}
}
return allSample.get(maxPoint);
}
//得到样本间最大距离点
public static K_meansBean getMax(K_meansBean kCenterOne,List<K_meansBean> list){
double max=0;
double distance=0;
int maxPoint=0;
for(int i=0;i<list.size();i++){
distance=getDistance(kCenterOne,list.get(i));
if (max<distance) {
max=distance;
maxPoint=i;
}
}
return list.get(maxPoint);
}
//重新计算聚类中心,返回三个簇的重新计算后的聚类中心
public static List<K_meansBean> getNewCenter(List<K_meansBean> listOne,List<K_meansBean> listTwo,List<K_meansBean> listThree){
List<K_meansBean> newKcenter=new ArrayList<>();
double listOneCenterX=0;
double listOneCenterY=0;
double listTwoCenterX=0;
double listTwoCenterY=0;
double listThreeCenterX=0;
double listThreeCenterY=0;
K_meansBean k_meansBeanOne=new K_meansBean();
K_meansBean k_meansBeanTwo=new K_meansBean();
K_meansBean k_meansBeanThree=new K_meansBean();
for(int i=0;i<listOne.size();i++){
listOneCenterX+=listOne.get(i).getStudyTime();
listOneCenterY+=listOne.get(i).getPalyGameTime();
}
for(int j=0;j<listTwo.size();j++){
listTwoCenterX+=listTwo.get(j).getStudyTime();
listTwoCenterY+=listTwo.get(j).getPalyGameTime();
}
for(int k=0;k<listThree.size();k++){
listThreeCenterX+=listThree.get(k).getStudyTime();
listThreeCenterY+=listThree.get(k).getPalyGameTime();
}
listOneCenterX=(double)(Math.round((listOneCenterX/listOne.size())*100)/100.0);
listOneCenterY=(double)(Math.round((listOneCenterY/listOne.size())*100)/100.0);
listTwoCenterX=(double)(Math.round((listTwoCenterX/listTwo.size())*100)/100.0);
listTwoCenterY=(double)(Math.round((listTwoCenterY/listTwo.size())*100)/100.0);
listThreeCenterX=(double)(Math.round((listThreeCenterX/listThree.size())*100)/100.0);
listThreeCenterY=(double)(Math.round((listThreeCenterY/listThree.size())*100)/100.0);
k_meansBeanOne.setStudyTime(listOneCenterX);
k_meansBeanOne.setPalyGameTime(listOneCenterY);
k_meansBeanTwo.setStudyTime(listTwoCenterX);
k_meansBeanTwo.setPalyGameTime(listTwoCenterY);
k_meansBeanThree.setStudyTime(listThreeCenterX);
k_meansBeanThree.setPalyGameTime(listThreeCenterY);
newKcenter.add(k_meansBeanOne);
newKcenter.add(k_meansBeanTwo);
newKcenter.add(k_meansBeanThree);
return newKcenter;
}

相关文章推荐
- K_Means优化算法之Canopy算法----java简单实现
- 基于内容的图像检索-聚类分析
- matlab实现聚类分析
- Java实现150条数据的K-means算法聚类分析(含界面)
- 第1次实验——NPC问题(回溯算法、聚类分析)
- 数据挖掘-聚类分析
- 基于聚类的离群点检测
- 科学论文1-软件缺陷预测中基于聚类分析的特征选择方法
- 聚类分析之模糊C均值算法核心思想
- 聚类分析之k-prototype算法解析
- 基于密度的optics聚类分析算法
- 熵在计算机方向的应用(浅谈信息熵)
- K-Means 算法
- 计科1111-1114班第一次实验作业(NPC问题——回溯算法、聚类分析)
- 聚类算法初探(七)聚类分析的效果评测
- 聚类分析:基本概念梳理
- 聚类算法(一):k-均值 (k-means)算法
- 聚类算法(二):DBSCAN算法
- 聚类分析
- 数据分类K—means 算法的python代码实现