Torch7模型训练
2016-12-14 10:46
253 查看
Torch7搭建卷积神经网络详细教程已经详细的介绍啦Module模块,这里再次基础上再给出一些上Container、
Transfer Functions Layers和 Simple Layers模块的理解。并在后面给出一些简单的模型训练方法。下述程序在itorch qtconsole下运行。
上一篇博文讲到Module主要有四个函数(详细见Torch7搭建卷积神经网络详细教程),但是注意以下几点:forward函数的input必须和backward的函数的input一致,否则梯度更新会有问题;forward会调用updateOutput(input),
而backward会调用[gradInput] ;updateGradInput (input, gradOutput)和accGradParameters(input, gradOutput) ;高级训练方式只要重载updateOutput和updateGradInput这两个函数,内部参数会自动改变。
@
add(module)
@ get(index)
@ size()
@ remove(index)
@ insert (module, [index] )
其用法在上一节搭建卷积神经网络的实例中已经给出,即生成是用一个Sequential,然后不断add(module),module有simple layers和卷积层。

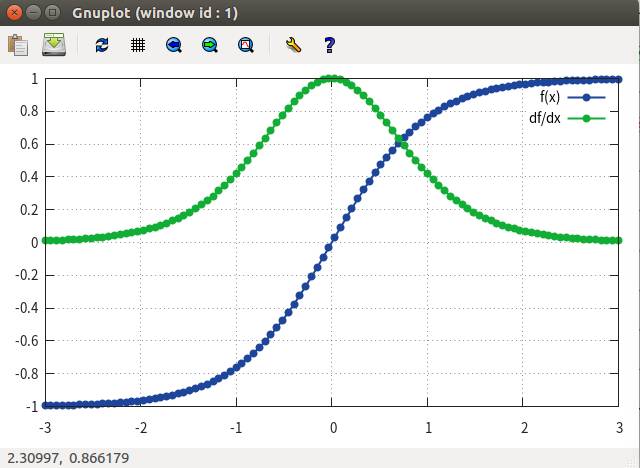
Simple Layers有很多,一些是提供仿射变换的,一些是进行Tensor method的。具有参数的modules有: Linear ,Add
,Mul ,CMul 等;进行数学运算的有:Max, Min, Exp, Mean, Log, Abs, MM(矩阵乘),Normalize(正则化);进行基本Tensor运算的 View ,Transpose 。
上述函数的具体使用方法可以看Torch7的官方API以及帮助文档。接下来仅介绍一些模型训练所需要的关键函数。
将image包导入当前运行环境,随机生成一张1通道32x32的彩色图像,如下
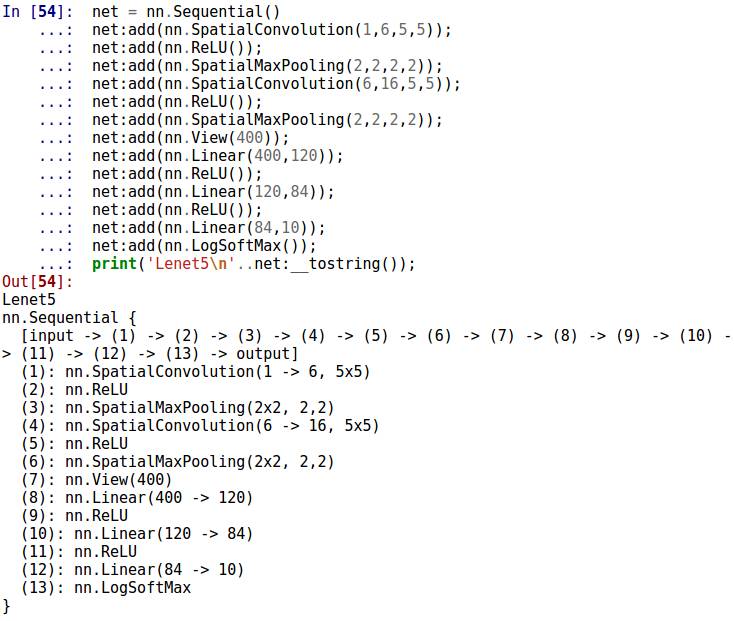
上一节我们构建的卷积神经网络如下(参数稍微有调整)。
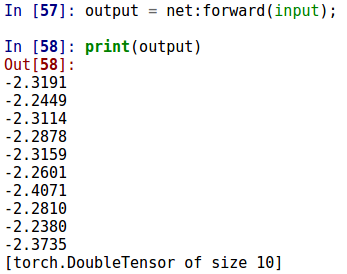
用上一节建立好的神经网络net调用forward()方法输入随即生成的图片得到输出的结果,如打印出来的形式,net最后是10个输出节点,这里输出了10个值(BP算法之前需要做的运算)。如下所示。
然后在此基础进行BP算法更新权值,如下所示。其中,zeroGradparameters是将网络中的梯度缓存设置为零;backword函数是进行后向传播训练的算法,第一个蚕食为输入的图像,与forward中的输入一致,不然后报错,第二个参数为导师信号,即图像的真实分类标签。
前向传播和反向传播的基本过程就是上面,当然到这还不能我们的网络,还没有定义损失函数,下面介绍损失函数的基本操作。

损失函数的实现也有正向和方向两个操作,不同的神经网络用BP算法求解的思想是一样的,但是定义的网络不同,其具体的损失度量不同。就这个例子来说我们定义是适合对分类的损失函数,调用他的前向传播方法并输入的参数分别为预测的类和训练样本所属的类。
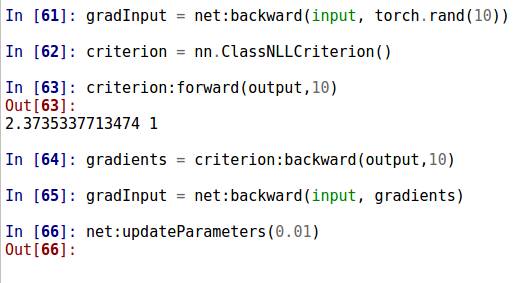
执行完损失函数的前向操作后,再进行反向操作,backward()方法里面的参数同forward()函数里的参数,返回值是损失函数的梯度;调用神经网络net的backward()方法输入训练集和其对应的损失函数梯度。然后,使用神经网络net的updateParameters()更新权重,该方法的输入值为学习率,即完成了训练。
Transfer Functions Layers和 Simple Layers模块的理解。并在后面给出一些简单的模型训练方法。下述程序在itorch qtconsole下运行。
上一篇博文讲到Module主要有四个函数(详细见Torch7搭建卷积神经网络详细教程),但是注意以下几点:forward函数的input必须和backward的函数的input一致,否则梯度更新会有问题;forward会调用updateOutput(input),
而backward会调用[gradInput] ;updateGradInput (input, gradOutput)和accGradParameters(input, gradOutput) ;高级训练方式只要重载updateOutput和updateGradInput这两个函数,内部参数会自动改变。
Container主要是为了复杂的神经网络,包含 Sequential,
Parallel, Concat 三个方法,并且重新实现了Module类的方法,主要函数有以下:
@add(module)
@ get(index)
@ size()
@ remove(index)
@ insert (module, [index] )
其用法在上一节搭建卷积神经网络的实例中已经给出,即生成是用一个Sequential,然后不断add(module),module有simple layers和卷积层。
Transfer Functions Layers就是激活函数,可以加入层模块或激活函数的层模块,最后加上criterion层模块。主要的激活函数有SoftMax,
SoftMin, SoftPlus, LogSigmoid, LogSoftMax, Sigmoid, Tanh, ReLU, PReLU, ELU, LeakyReLU..........。简单的拿Sigmoid举个例子吧,如下所示。
Simple Layers有很多,一些是提供仿射变换的,一些是进行Tensor method的。具有参数的modules有: Linear ,Add
,Mul ,CMul 等;进行数学运算的有:Max, Min, Exp, Mean, Log, Abs, MM(矩阵乘),Normalize(正则化);进行基本Tensor运算的 View ,Transpose 。
上述函数的具体使用方法可以看Torch7的官方API以及帮助文档。接下来仅介绍一些模型训练所需要的关键函数。
将image包导入当前运行环境,随机生成一张1通道32x32的彩色图像,如下
上一节我们构建的卷积神经网络如下(参数稍微有调整)。
用上一节建立好的神经网络net调用forward()方法输入随即生成的图片得到输出的结果,如打印出来的形式,net最后是10个输出节点,这里输出了10个值(BP算法之前需要做的运算)。如下所示。
然后在此基础进行BP算法更新权值,如下所示。其中,zeroGradparameters是将网络中的梯度缓存设置为零;backword函数是进行后向传播训练的算法,第一个蚕食为输入的图像,与forward中的输入一致,不然后报错,第二个参数为导师信号,即图像的真实分类标签。
前向传播和反向传播的基本过程就是上面,当然到这还不能我们的网络,还没有定义损失函数,下面介绍损失函数的基本操作。
损失函数的实现也有正向和方向两个操作,不同的神经网络用BP算法求解的思想是一样的,但是定义的网络不同,其具体的损失度量不同。就这个例子来说我们定义是适合对分类的损失函数,调用他的前向传播方法并输入的参数分别为预测的类和训练样本所属的类。
执行完损失函数的前向操作后,再进行反向操作,backward()方法里面的参数同forward()函数里的参数,返回值是损失函数的梯度;调用神经网络net的backward()方法输入训练集和其对应的损失函数梯度。然后,使用神经网络net的updateParameters()更新权重,该方法的输入值为学习率,即完成了训练。

相关文章推荐
- 利用crf++来训练一个中文分词模型
- xgboost参数说明,模型训练,模型预测java接口相关说明
- 交通标识牌模型训练c++代码实例及运行结果
- 利用caffe训练好的模型测试自己的手写字体图片
- 如何重新训练Tensorflow图像分类模型
- tf32: 一个简单的cnn模型:人脸特征点训练
- 爬取百度图片各种狗狗的图片,使用caffe训练模型分类
- 【sphinx】中文声学模型训练
- tensorflow将训练好的模型freeze,即将权重固化到图里面,并使用该模型进行预测
- 语音识别工具包pocketsphinx-0.8声学模型训练
- Caffe_03_用训练好的模型测试
- Mxnet图片分类(4)利用训练好的模型进行测试
- keras 保存训练的最佳模型
- 修改版Alexnet模型训练CIFAR10数据集程序的总结
- 手把手:我的深度学习模型训练好了,然后要做啥?
- R语言基于支持向量机训练模型实现类预测
- Caffe 之 使用非图片的鸢尾花(IRIS)数据集(hdf5格式) 训练网络模型
- hadoop集群使用sklearn进行模型训练
- tensorflow将训练好的模型freeze,即将权重固化到图里面,并使用该模型进行预测
- tensorflow: 保存和加载模型, 参数;以及使用预训练参数方法