ORACLE---对象的管理
2016-12-09 00:00
274 查看
对象管理
一、表
1.堆表:
表数据和索引数据都放到索引段中
用到表的数据量很大,将表数据和索引数据放到同一个索引段中,只需要扫描一个段就可以取出数据,减少块的读取
索引组织表先插入的放到前面,后插入的放到后面,根据大小排序
建表语法:
create table <>(column datatype.....,) organization index //必须要指定主键列
删除,修改与表一致
| ename | tel |
|name | sex | tel1 | tel2 |
>>>insert into teel valuse('aa',tel_type('123456','123564'),'cd ');
>>>select e.tel.tel1 from teel e; //必须要给一个别名才可以查到
>>>update teel t set t.tel.tel1='13012345' where name='aa';
>>>alter type tel_type frop attribute(tel1) cascade; //删除某一列下的子列,因为该语句为PLSQL语句,所以用户掉不到数据,只有退出后重新登录,或者执行一些DDL操作后,才能从表中查到数据
多表查询的时候,两个表当中有相同的列(列名相同,数据类型相同,内容相同)
create cluster <> (column datatype);
create index <> on cluster();
create table <> ();
2)数据可以按分区进行备份
3)用户可以查询某一个记录时,可以只扫描某一个分区,减少扫描时间
4)每个分区可以指定到不同的磁盘,保证数据的安全
1)range范围分区:要分区的列,值在某个范围内
create table <> (column datatype ,...) partition by range(column)
partition <> values less than () ,
partition <>values less than(),
....
partition <> valuse less than (maxvalue);
>>>select * from remp p1;
>>>select segment_name from user_segments; //每一个分区一个段
11g中引进的范围分区的一种:间隔分区(年,月,天,小时,分钟,秒)
分隔函数
numtoyminterval(2,'year') //每隔两年分区
numtoyminterval(1,'month') //每隔一月分区
numtodsinterval(7,'day')
,每隔一年就会建一个分区
2)hash哈希分区:对表中的列进行分区,但这个列没有规律可循
create table <> (column datatupe,...) partition by hash (column)
(
partition <>,
partition <>.
....
);
3)list列表分区:要分区的列,列的值是固定的
要分区的列重复值很多,可以使用in列举出来
11g的新功能
4)组合分区:表已经分区,但需要在进行分区
10g---
(by list+by range
by range+by hash
by list+by hash
)
11g---9种分区 by range+by range
create table <> (column datatype ....) partition by list(column)
subpartition by range(colunm)
(
partition <> values(..)
(
subpartition <> values less than(..),
subpartition <> values less than(..),
subpartition <> values less than(..)
)
partition <> values(...)
(
subpartition <> values less than(..),
subpartition <> values less than(..),
subpartition <> values less than(..)
)
);
d.分区表与普通表的转换
1)插入数据法
会产生大量的redo,不适合数据量大的表,也不适合7*24小时的数据库
insert
2)交换分区法
10-20-30 适合数据量较大的表,速度较快,也会产生redo也会产生undo,业务量较大,业务高峰期,也不建议使用
建分区表
alter table t12 exchange partition p1 with table e1; //将我们的普通表中的数据交换到分区表中去,普通表会被清空,分区表会更新我们的普通表数据
alter table t12 exchange partition p2 with table e2;
alter table t12 exchange partition p3 with table e3;
3)在线重定义(工作中可用,可以保证两个表中的数据一致)
必须要有主键列
SQL> desc DBMS_REDEFINITION
1>创建分区表
2>使用在线重定义表转换
dbms_redefinition.start_redef_table('SCOOT','EMP','LEMP') //括号里的内容依次为(uname , orig_table, int_table)
dbms_redefinition.sync_interim__table('SCOOT','EMP','LEMP')
dbms_redefinition.finish_redef__table('SCOOT','EMP','LEMP') //如果不执行完成同步操作,emp中只要有数据插入都会同步到lemp表中,但是会锁住lemp表,所以也不适合高峰时期
alter table <> add partition <> values() ;//增加list分区
alter table <> add partition <> valuse less than () ;//增加range分区
alter table <> add partition <> ; //增加hash分区
alter table <> add subpartition <> values(); //组合分区list
alter table <> add subpartition <> values() less than ();
alter table <> add subpartition <> ; //组合分区hash
2.删除分区
alter table <> drop partition <> values();
alter table <> drop partition <> ;
3.合并分区
alter table <> merge partitions p1,p2 into partition p2;
alter table <> merge subpartitions <> ,<> into subpartition <> ;//合并子分区
4、分区索引创建
1)全局索引:一个分区表上只创建一个索引
create index <> on <> (colmn) global;
alter index <> rebuild online ; //在线重建,必须要事务完成后才能成功,很少有用户做DML操作时才能取创建
2)本地索引:一个分区表上每个分区都创建一个索引 ,适用于DDL 操作较多的分区
create index <> on <> (clomn) local ;
alter index <> rebuild partition <>;
>>>desc user_indexes //查看创建的索引
>>>desc user_ind_partitions //查看分区表的索引
1.将其他数据库的数据先导成文本格式,然后再用sqllosder 方式导进去
sqlloader : 将外部文件导入到表中,数据就存放到数据文件中了,可以做DML操作,DQL操作
1>$sqlloader
2>infile =/tmp/a.txt 对应的表,对应的列
$sqlldr scott/tiger control=/tmp/sqlload.ctl
vim /tmp/sqlload.ctl
cd /opt/u01/oracle/11g/sqldeveloper/
2.下面这两种方式,是引用的方式,数据还是放在外部空间里,只能做查询操作,不可以做DML操作 (工作中基本不会用到这种方式)
oracle loader : 加载文本外部文件
oracle datapump :只能加载二进制文件,基本不会使用
1.居于事务的临时表
事物一旦被提交,表就会被清空
create global temporary table <> (colmn datatype ,...) on commit delete rows;
2.居于会话的临时表,当前会话创建,一旦结束会话,表就会被清空
create global temporary table <> (column datatype,...,...) on commit preserve rows ;
3.普通临时表
create global temporary table <> (column datatype,...,); //用户执行用户切换,rollback ,退出会话,commit 表都会被清空
>>>create global temporary table t1 (name varchar2(20) ,deptno number ) on commit delete rows ;
1.专有连接
用户连接有专门的进程进行相应
user ----server process
2.共享连接 []
用户连接数据库时,没有服务进程相应,而将用户的信息放到调度里,而调度放到队列[队列]中
uesr ----dispater --[SAG] ----server ------data buffer ------|
3.监听程序工作原理
用户进程跟服务器能不能连接主要是去问我们的监听
客户端程序------tnsnames.ora/本地命名解析文件
1.sqlplus sys/oracle@updb as sysdba //远程连接
b.去客户端验证用户名密码
c.通过服务器连接实例
2.sqlplus sys/oracle@ip:1521/service_names as sysdba
服务器端程序listener.ora
1.静态注册
将实例名/服务名写到了监听文件中
SID_DESC (实例名/服务名 oracle家目录 ....)
2.动态注册
由pmon 进程去动态注册
alter system register; //手动注册,pmon也是去执行这条命令
lsnrctl status //查看监听状态
lsnrctl stop //停掉我们的监听
ready : 动态注册
unknow: 静态注册
项目中一般使用静态监听,可以保证用户时时可以连接
一个数据库中只使用一个listener.ora
一个监听可以监听一个数据库,也可监听多个数据库
一个监听程序可以被多个实例监听 ----集群
监听的默认端口为:1521
4.如何配置监听
在grid 目录下面执行 netca 创建出来的为动态的监听 图形界面创建 ,监听文件会放到/opt/u01/grid/11g/nerwork/admin/listener.ora ,在哪个文件下面执行就会创建到相应的文件目录下
add-->listener-->ipc--->1521--->no-->
netmgr 创建出来的为 静态的监听
静态注册,监听两个库
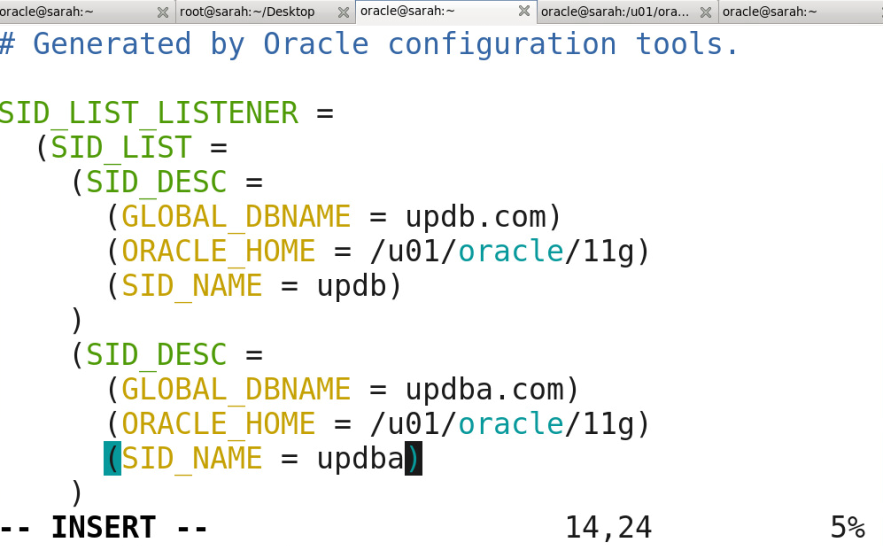
有参数的修改,必须重启监听
lsnrctl stop
lsnrctl start
tnsname.ora
5.监听程序的管理
11g以前 : lsnrtcl start
lsnrctl status
lsnrctl stop
lsnrctl reload
11g 以后---
srvctl start listener //只能启动监听名字为listener的监听
srvctl start listener -l listener1 //启动名字为listener1的监听
srvctl add listener -l listener1 //监听没有在grid文件里,加入到grid文件里进行管理
srvctl remove listener
lsnrctl start
show parameter service_name //查看服务名,如果为updba.com 一般走的专有连接
select service_name ,username,server for v$session //service 为dedicated 表示是专有连接
shared 是sys用户的共享连接,none是普通用户的共享连接
vim /opt/u01/oracle/11g/network/admin/tnsnames.ora
增加server

查看网络是否通畅,用
tsping updb
tnsping updb
一、表
1.堆表:
2.索引组织表:
表数据和索引数据都放到索引段中用到表的数据量很大,将表数据和索引数据放到同一个索引段中,只需要扫描一个段就可以取出数据,减少块的读取
索引组织表先插入的放到前面,后插入的放到后面,根据大小排序
建表语法:
create table <>(column datatype.....,) organization index //必须要指定主键列
删除,修改与表一致
3.对象表:
列下面还有列| ename | tel |
|name | sex | tel1 | tel2 |
>>>insert into teel valuse('aa',tel_type('123456','123564'),'cd ');
>>>select e.tel.tel1 from teel e; //必须要给一个别名才可以查到
>>>update teel t set t.tel.tel1='13012345' where name='aa';
>>>alter type tel_type frop attribute(tel1) cascade; //删除某一列下的子列,因为该语句为PLSQL语句,所以用户掉不到数据,只有退出后重新登录,或者执行一些DDL操作后,才能从表中查到数据
4.簇表:
(项目中不常用)多表查询的时候,两个表当中有相同的列(列名相同,数据类型相同,内容相同)
create cluster <> (column datatype);
create index <> on cluster();
create table <> ();
5.分区表:
(使用频率和堆表一致)a.什么时候要创建分区表
当一个表中的数据量达到1G,而我们的堆表无法满足时,我们需要将普通表创建为分区表b.分区表的特点
1)每个分区的数据可以分开存放,放到不同磁盘中,减少磁盘IO2)数据可以按分区进行备份
3)用户可以查询某一个记录时,可以只扫描某一个分区,减少扫描时间
4)每个分区可以指定到不同的磁盘,保证数据的安全
c.分区表的分类
一个表中最多只能分1023个分区,要是分区不够,我们只能在分区下再创建分区
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~1)range范围分区:要分区的列,值在某个范围内
create table <> (column datatype ,...) partition by range(column)
partition <> values less than () ,
partition <>values less than(),
....
partition <> valuse less than (maxvalue);
SQL> l 1 create table remp (deptno number,ename varchar2(20),sal number) 2 partition by range(sal) 3 (partition p1 values less than(1000), 4 partition p2 values less than(2000), 5 partition p3 values less than(3000), 6* partition p4 values less than(maxvalue)) SQL> / Table created.
>>>select * from remp p1;
>>>select segment_name from user_segments; //每一个分区一个段
create table hemp (deptno number,ename varchar2(20),hirdate date)
partition by range(hirdate)
(partition p1 values less than(to_date('1981-01-01','yyyy-mm-dd')),
partition p1 values less than(to_date('1982-01-01','yyyy-mm-dd')),
partition p1 values less than(to_date('1983-01-01','yyyy-mm-dd')),
partition p1 values less than(to_date('1988-01-01','yyyy-mm-dd'))
);11g中引进的范围分区的一种:间隔分区(年,月,天,小时,分钟,秒)
分隔函数
numtoyminterval(2,'year') //每隔两年分区
numtoyminterval(1,'month') //每隔一月分区
numtodsinterval(7,'day')
,每隔一年就会建一个分区
create table r1 (name varchar2(10) ,hdate date)
partition by range(hdate)
interval (numtoyminterval(1,'year'))
(
partition p1 values less than(to_date('1981-01-01','yyyy-mm-dd'))
);2)hash哈希分区:对表中的列进行分区,但这个列没有规律可循
create table <> (column datatupe,...) partition by hash (column)
(
partition <>,
partition <>.
....
);
SQL> create table hemp (ename varchar2(20),empno number) partition by hash (ename) 2 (partition p1, 3 partition p2, 4 partition p3); Table created. SQL> SQL> select * from hemp p2;
3)list列表分区:要分区的列,列的值是固定的
要分区的列重复值很多,可以使用in列举出来
SQL> create table lemp(deptno number,ename varchar2(20))partition by list(deptno) 2 (partition p1 values(10), 3 partition p2 values(20), 4 partition p3 values(30) 5 partition p4 values(default)); Table created. SQL>
11g的新功能
create table lemp (hiredate date,ename varchar2(20),hdate (as to_char(hiredate,'yyyy'))) partition by list(hdate)
( partition p1 values('1980'),
partition p2 values('1981'),
partition p3 values('1982'),
partition p4 values(default));4)组合分区:表已经分区,但需要在进行分区
10g---
(by list+by range
by range+by hash
by list+by hash
)
11g---9种分区 by range+by range
create table <> (column datatype ....) partition by list(column)
subpartition by range(colunm)
(
partition <> values(..)
(
subpartition <> values less than(..),
subpartition <> values less than(..),
subpartition <> values less than(..)
)
partition <> values(...)
(
subpartition <> values less than(..),
subpartition <> values less than(..),
subpartition <> values less than(..)
)
);
create table lremp(ename varchar2(20),deptno number,sal number) partition by list(deptno) subpartition by range(sal) ( paratition p1 values (10) ( subpartition p11 values less than(1000), subpartition p12 values less than(2000), subpartition p13 values less than(3000), subpartition p14 values less than(maxvalue) ), partition p2 values(20,30) ( subpartition p11 values less than(1000), subpartition p12 values less than(2000), subpartition p13 values less than(3000), subpartition p14 values less than(maxvalue)) ); >>select * from lremp subpatition p22;
d.分区表与普通表的转换
1)插入数据法
会产生大量的redo,不适合数据量大的表,也不适合7*24小时的数据库
insert
2)交换分区法
10-20-30 适合数据量较大的表,速度较快,也会产生redo也会产生undo,业务量较大,业务高峰期,也不建议使用
建分区表
create table t12 (ename varchar2(10),deptno number(2) ,sal number(7,2)) partition by list(deptno) ( partition p1 values (10), partition p2 values (10), partition p3 values (10), partition p4 values (default) ); // 建和分区表对应的普通表,并在表中写入数据 create table e1 as select ename,deptno,sal from emp where deptno=10; create table e1 as select ename,deptno,sal from emp where deptno=20; create table e1 as select ename,deptno,sal from emp where deptno=30; create table e1 as select ename,deptno,sal from emp where deptno not in (10,20,30);
alter table t12 exchange partition p1 with table e1; //将我们的普通表中的数据交换到分区表中去,普通表会被清空,分区表会更新我们的普通表数据
alter table t12 exchange partition p2 with table e2;
alter table t12 exchange partition p3 with table e3;
3)在线重定义(工作中可用,可以保证两个表中的数据一致)
必须要有主键列
SQL> desc DBMS_REDEFINITION
1>创建分区表
2>使用在线重定义表转换
dbms_redefinition.start_redef_table('SCOOT','EMP','LEMP') //括号里的内容依次为(uname , orig_table, int_table)
dbms_redefinition.sync_interim__table('SCOOT','EMP','LEMP')
dbms_redefinition.finish_redef__table('SCOOT','EMP','LEMP') //如果不执行完成同步操作,emp中只要有数据插入都会同步到lemp表中,但是会锁住lemp表,所以也不适合高峰时期
e.分区表的管理
1.增加分区alter table <> add partition <> values() ;//增加list分区
alter table <> add partition <> valuse less than () ;//增加range分区
alter table <> add partition <> ; //增加hash分区
alter table <> add subpartition <> values(); //组合分区list
alter table <> add subpartition <> values() less than ();
alter table <> add subpartition <> ; //组合分区hash
2.删除分区
alter table <> drop partition <> values();
alter table <> drop partition <> ;
3.合并分区
alter table <> merge partitions p1,p2 into partition p2;
alter table <> merge subpartitions <> ,<> into subpartition <> ;//合并子分区
4、分区索引创建
1)全局索引:一个分区表上只创建一个索引
create index <> on <> (colmn) global;
alter index <> rebuild online ; //在线重建,必须要事务完成后才能成功,很少有用户做DML操作时才能取创建
2)本地索引:一个分区表上每个分区都创建一个索引 ,适用于DDL 操作较多的分区
create index <> on <> (clomn) local ;
alter index <> rebuild partition <>;
>>>desc user_indexes //查看创建的索引
>>>desc user_ind_partitions //查看分区表的索引
6.外部表:
数据不是存放在数据库中,而是在外部文件中1.将其他数据库的数据先导成文本格式,然后再用sqllosder 方式导进去
sqlloader : 将外部文件导入到表中,数据就存放到数据文件中了,可以做DML操作,DQL操作
1>$sqlloader
2>infile =/tmp/a.txt 对应的表,对应的列
$sqlldr scott/tiger control=/tmp/sqlload.ctl
vim /tmp/sqlload.ctl
load data infile ‘/tmp/a.txt ’ //从哪个地方加载 append //以怎样的方式加载 into table dept //加载到哪里去 fields terminated by ‘,’ //列以什么方式间隔 trailling nullcols //过滤最后的空行 (deptno,dname,loc) //加载的每个数据对应的列
cd /opt/u01/oracle/11g/sqldeveloper/
2.下面这两种方式,是引用的方式,数据还是放在外部空间里,只能做查询操作,不可以做DML操作 (工作中基本不会用到这种方式)
oracle loader : 加载文本外部文件
create table <> () organization external ( type oracle load create directory ext1 as '/tmp'; grant read,write on directory ext1 scott ; create table extab(deptno number ,name varchar2(20) ,loc varchar2(10)) organization external ( type oracle_loader default directory ext1 access parameters ( records delimited by newline fields terminated by ‘,’ ) location (a.txt);
oracle datapump :只能加载二进制文件,基本不会使用
7.临时表:
一般用作测试1.居于事务的临时表
事物一旦被提交,表就会被清空
create global temporary table <> (colmn datatype ,...) on commit delete rows;
2.居于会话的临时表,当前会话创建,一旦结束会话,表就会被清空
create global temporary table <> (column datatype,...,...) on commit preserve rows ;
3.普通临时表
create global temporary table <> (column datatype,...,); //用户执行用户切换,rollback ,退出会话,commit 表都会被清空
>>>create global temporary table t1 (name varchar2(20) ,deptno number ) on commit delete rows ;
8.网络管理:
1.专有连接用户连接有专门的进程进行相应
user ----server process
2.共享连接 []
用户连接数据库时,没有服务进程相应,而将用户的信息放到调度里,而调度放到队列[队列]中
uesr ----dispater --[SAG] ----server ------data buffer ------|
3.监听程序工作原理
用户进程跟服务器能不能连接主要是去问我们的监听
客户端程序------tnsnames.ora/本地命名解析文件
1.sqlplus sys/oracle@updb as sysdba //远程连接
b.去客户端验证用户名密码
c.通过服务器连接实例
2.sqlplus sys/oracle@ip:1521/service_names as sysdba
服务器端程序listener.ora
1.静态注册
将实例名/服务名写到了监听文件中
SID_DESC (实例名/服务名 oracle家目录 ....)
2.动态注册
由pmon 进程去动态注册
alter system register; //手动注册,pmon也是去执行这条命令
lsnrctl status //查看监听状态
lsnrctl stop //停掉我们的监听
ready : 动态注册
unknow: 静态注册
项目中一般使用静态监听,可以保证用户时时可以连接
一个数据库中只使用一个listener.ora
一个监听可以监听一个数据库,也可监听多个数据库
一个监听程序可以被多个实例监听 ----集群
监听的默认端口为:1521
4.如何配置监听
在grid 目录下面执行 netca 创建出来的为动态的监听 图形界面创建 ,监听文件会放到/opt/u01/grid/11g/nerwork/admin/listener.ora ,在哪个文件下面执行就会创建到相应的文件目录下
add-->listener-->ipc--->1521--->no-->
netmgr 创建出来的为 静态的监听
静态注册,监听两个库
有参数的修改,必须重启监听
lsnrctl stop
lsnrctl start
tnsname.ora
5.监听程序的管理
11g以前 : lsnrtcl start
lsnrctl status
lsnrctl stop
lsnrctl reload
11g 以后---
srvctl start listener //只能启动监听名字为listener的监听
srvctl start listener -l listener1 //启动名字为listener1的监听
srvctl add listener -l listener1 //监听没有在grid文件里,加入到grid文件里进行管理
srvctl remove listener
lsnrctl start
show parameter service_name //查看服务名,如果为updba.com 一般走的专有连接
select service_name ,username,server for v$session //service 为dedicated 表示是专有连接
shared 是sys用户的共享连接,none是普通用户的共享连接
vim /opt/u01/oracle/11g/network/admin/tnsnames.ora
增加server
查看网络是否通畅,用
tsping updb
tnsping updb

相关文章推荐
- dotConnect for Oracle 更新至v9.2,新增程序集添加复选框,EF支持升级|附下载
- Oracle 物化视图
- Oracle 11g ASM之--ACFS创建案例
- Oracle误删除数据的恢复方法
- A、B两张表 获取过滤条件后A表中除了B表中剩余的数据
- oracle官网下载java8文档
- Oracle 生成一张测试表并插入随机数据
- 转载】Oracle的日常监控脚本 Oracle管理及常用基础脚本
- Oracle:数据库设计三大范式
- Oracle的实例占用内存调整
- 修改oracle内存
- 更改Oracle数据文件名及数据文件存放路径
- Oracle中把一个DateTime的字符串转化成date类型。to_date('2016/12/8 18:55:43','yyyy/MM/dd hh24:mi:ss'),
- [置顶] Oracle Database之集合操作函数(UNION, INTERSECT, MINUS)
- 【Oracle】审计
- Oracle数据库即时客户端PLSQL的配置:配置ORACLE 11g绿色版客户端和PLSQL环境
- 认识Oracle同义词(synonyms)和链接(database links)
- Oracle-decode函数
- oracle varchar 转换clob
- 【转】关于oracle with as用法