python使用requests包爬取Pixiv图片--关注画师的所有作品
2016-12-08 21:19
543 查看
最近学了点python,想着做点实际任务来练练手,各种竞赛网站的题又都太难了,目前只是学了点皮毛,实际码点代码巩固语法而已,python只是顺便学一学,感觉确实是一门很。。很。。厉害!的语言,相比matlab感觉更像在编程,相比C++又简单很多,不用考虑太多细节的东西,好用的库一大堆。
好了,废话不多说,详细讲一讲爬P站过程中的那些坑。
网上各种爬虫教程很多,例子也很多,大多数三次元的网站都被现充们爬完了,也有很多坑的总结帖,但是搜索P站的相关文章确实太少了,而且这种东西更新地太快了,一开始找了篇今年4月份的博客,很多都已经不适用了,还得靠自己啊~~
首先看登录过程,毕竟P站也是一个比较大型的二次元交友?网站,登录还是需要的,不过虽然登录界面没有验证码,但是它在POST信息中有一个post_key用来验证,一开始在这由于参考前人的代码,没有考虑到post_key,可能也就最近才加上这一层为了更加安全?确实浪费了我很多时间,整整一晚上,差点放弃了。。所以在下面模拟登录是不能只给账号密码,还有一个动态的post_key,思路就是用session来记录这一次会话的post_key,以及后面登录的cookies。代码如下。
baseurl就是这个页面,注意P站的登录界面特别慢,不过登陆进去就好了,监控登录的nework的时候真的是急死我了
此时F12查看network情况,勾选preserve log(不然登录界面跳转后原来的POST信息就没了),点击登陆后可以发现浏览器向服务器发送了POST的请求,打开这个POST看一下,
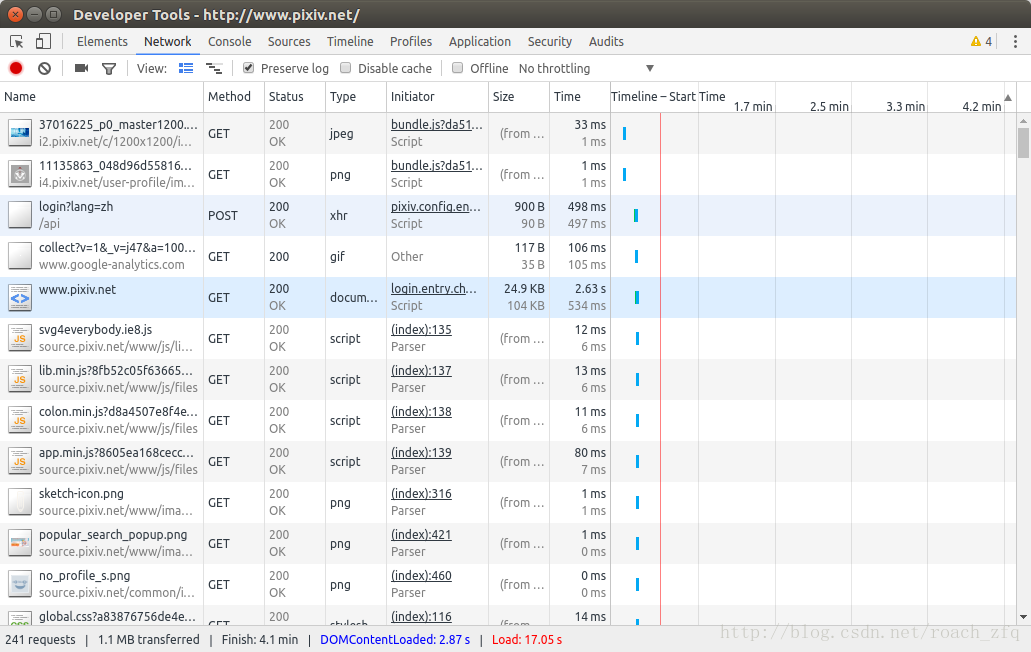
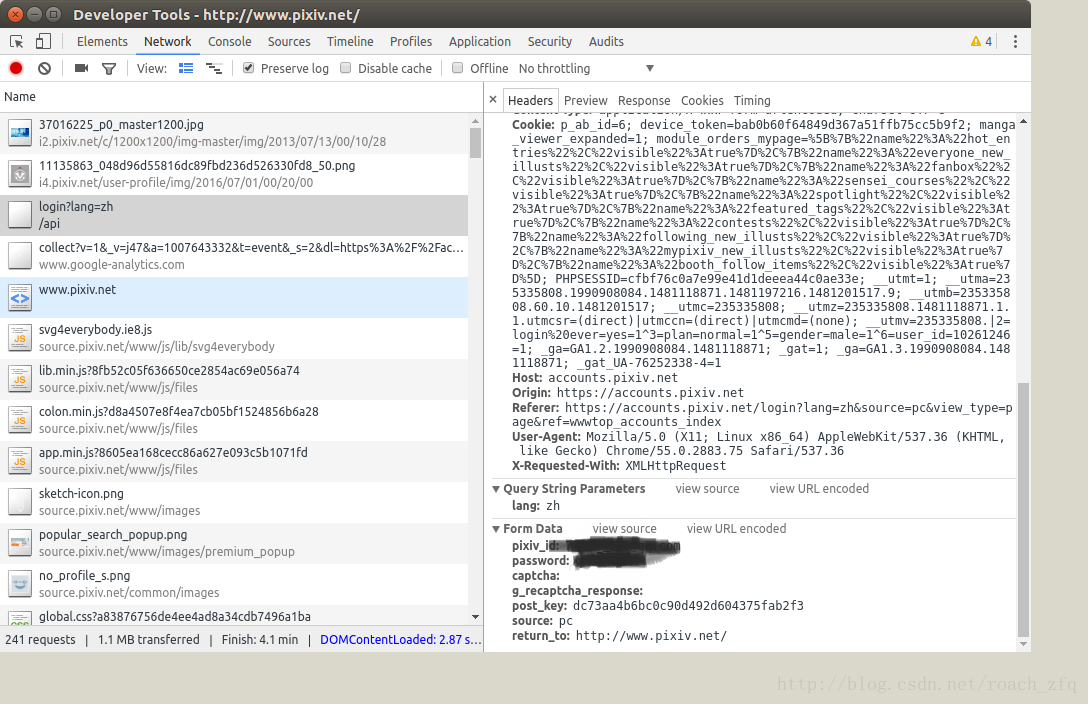
我们就模拟这个Form data来post自己的信息,模拟登陆,代码如下:
后面的话其实就和平常的爬虫代码差不多了,分析网页,获取图片源地址,下载到本地,因为这一次只是一个尝试的过程,所以选取的任务比较简单,就是爬取关注的千叶大大@千叶QY3的所有作品,其实一开始想爬Miku标签下所有高赞作品的,过两天尝试了一下也实现了python使用requests和BeautifulSoup包爬取Pixiv图片--指定tag下的所有作品
然后开始码代码吧,我这里用的是requests包,感觉比urllib2+cookielib的方式确实简单很多。
另外还要注意有的一个作品它有好几张,但有的你点开它不止一张,这种的html和单张图片的不怎么一样,需要重新分析并提取地址,相当于在那个图片详情页面的地址再多点一次才能提取到想要的最大分辨率图片的url,这里也花了很长时间,我的代码如下,可以参考python爬虫学习--pixiv爬虫(2)--国际排行榜的图片爬取,里面的对P站三种不同图片(单图,多图,动图)的处理方法,比我不知高到哪去了,后悔没有一开始看到他的解决方法。不过算了一下,感觉复杂度都是差不多的,毕竟就这么几行代码,不过那篇博客的代码确实更优秀,值得学习。
关于如何获取下一页作品的html,因为在第一页html中没有找打总共有多少页,所以只能用while循环来判断获取页面上下一页按钮得到的url是否为空来结束,不过后来在其他博客里看到第一页可以获取总共作品的数量,然后每一页20个,用总数量除以20向上取整就得到总页数了,这个方法也是可行的。这里先把获取每一页上的图片注释掉,测试一下我的方法能否正常工作,如下:
运行结果:
说明这种方法还是可行的。
下面整理一下,贴上完整的,并运行
运行,并没有刷刷刷的效果,连接P站的速度很慢,可能因为P站是外源吧。。部分结果如下,总共就太长了,得运行很久:
偶尔还会在某一张图片卡很久,然后下载不全,可能也是因为网络的原因吧,像这样:

它底下是空的,乱码的。。这样的还好几张呢
最后看一下到目前的成果
才30几张,还有85%呢,让它跑一夜吧,完了再来更新。
第二早发现运行到第3页遇到第一个动图获取不了,于是添上了上面处理动图的方法。
不过偶尔会get不到某个指定url的页面,可能是P站的某种反爬虫技术吧,限制IP访问频率?限制User-Agent?不过又很不确定,有时候可以get上百张突然报错get不了,有时候才十几张就不让继续get,也还是没太多时间的原因,没有太多精力去研究了,暂且就这样吧,给它加了检查是否已经下载过该图片报错下载过的话自动跳过的语句,这样发生错误的话从错误的那一页重新开始就好了(将firstPageUrl设为该页的url)
这样运行一会的话,有这样的结果:
重新从某一页开始获取时:

遇到gif是的情况:
不过当所有都get完了从第一页再重新开始的时候,速度很快,刷刷刷的,大概用了3分钟检查完了所有11页的内容,中间没有任何阻碍,看来P站真的限制同一次会话get原图的次数?,你不去get原图只是依次check每一个原图的url就完全没问题。然后检查结果就是全都已经存在不用再保存,也顺便把那几张黑掉的图 如下图,删掉重新get到了完整的,今早的网还不错呢!>_<~~~
最后快结束时,get最后几张图片时的控制台输出:
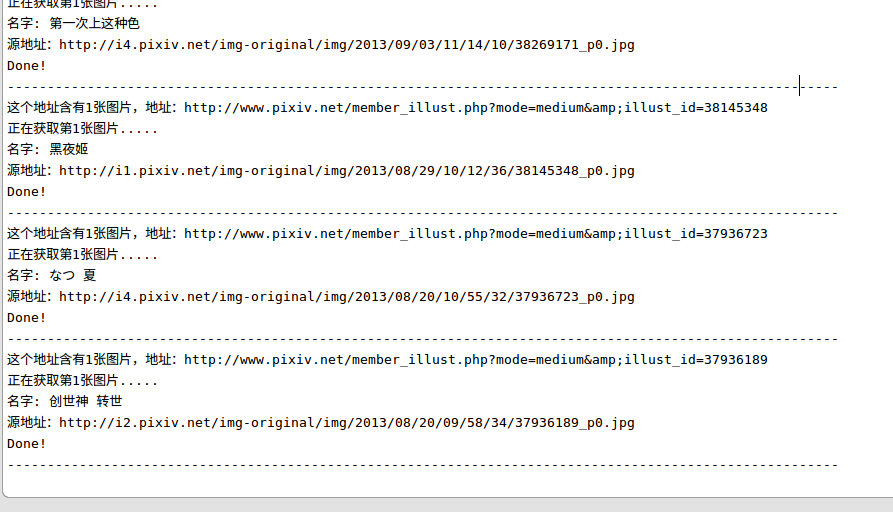
这就是最后一张啦!运行结束啦~
最后晒一下成果,总共219张图片:
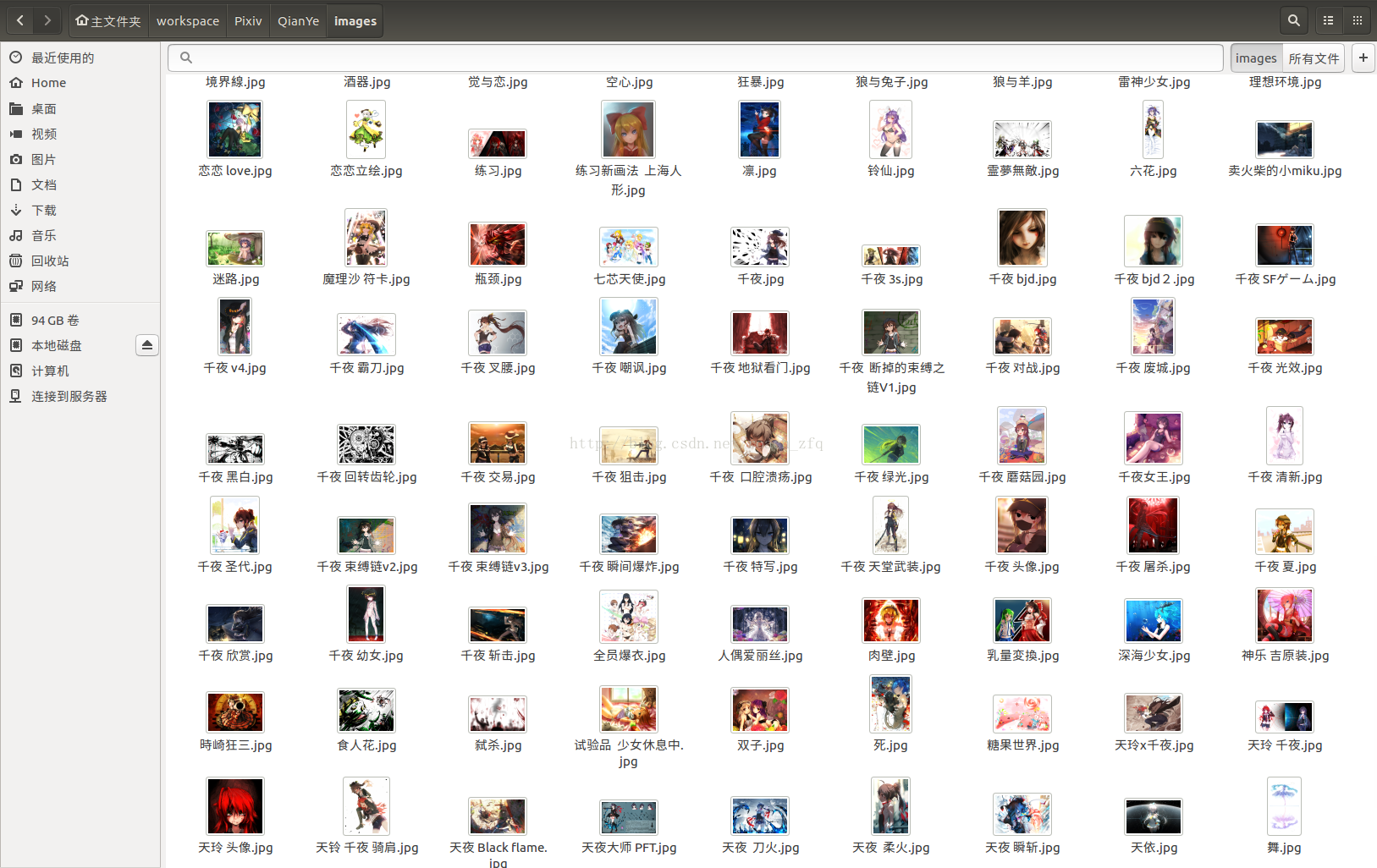
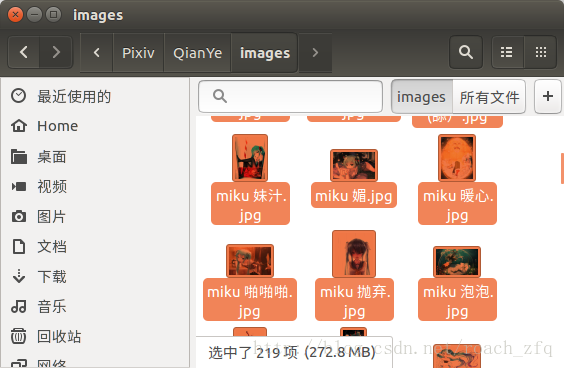
注意全都是高清大图哦,每个1-2MB左右的,可以做桌面的那种,跟网页上看到的那种小图可不一样。。
遗留问题:代码不稳定,每次运行不确定的迭代次数后直到self.getPageWithUrl(Url)报错:requests.exceptions.ConnectionError: ('Connection aborted.', BadStatusLine("''",)),有时候可以直接运行到最后,get到所有的图片,有时候get到50张,有时候30,有时候甚至才几张就报错,不过增加了判断图片是否存在机制后直接运行就好 会跳过已经下载好的,目前不太清楚具体原因,这个可能要很深入的学习才能理解吧。
最后来张V家众人图,完结\(≧▽≦)/~

python爬虫学习--pixiv爬虫(3)--关注用户作品爬取
Python利用Requests库写爬虫(一)
Python快速教程
好了,废话不多说,详细讲一讲爬P站过程中的那些坑。
网上各种爬虫教程很多,例子也很多,大多数三次元的网站都被现充们爬完了,也有很多坑的总结帖,但是搜索P站的相关文章确实太少了,而且这种东西更新地太快了,一开始找了篇今年4月份的博客,很多都已经不适用了,还得靠自己啊~~
首先看登录过程,毕竟P站也是一个比较大型的二次元交友?网站,登录还是需要的,不过虽然登录界面没有验证码,但是它在POST信息中有一个post_key用来验证,一开始在这由于参考前人的代码,没有考虑到post_key,可能也就最近才加上这一层为了更加安全?确实浪费了我很多时间,整整一晚上,差点放弃了。。所以在下面模拟登录是不能只给账号密码,还有一个动态的post_key,思路就是用session来记录这一次会话的post_key,以及后面登录的cookies。代码如下。
baseurl就是这个页面,注意P站的登录界面特别慢,不过登陆进去就好了,监控登录的nework的时候真的是急死我了
此时F12查看network情况,勾选preserve log(不然登录界面跳转后原来的POST信息就没了),点击登陆后可以发现浏览器向服务器发送了POST的请求,打开这个POST看一下,
我们就模拟这个Form data来post自己的信息,模拟登陆,代码如下:
def __init__(self):
self.baseUrl = "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index"
self.LoginUrl = "https://accounts.pixiv.net/api/login?lang=zh"
self.firstPageUrl = 'http://www.pixiv.net/member_illust.php?id=7210261&type=all'
self.loginHeader = {
'Host': "accounts.pixiv.net",
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36",
'Referer': "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index",
'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8",
'Connection': "keep-alive"
}
self.return_to = "http://www.pixiv.net/"
self.pixiv_id = '7xxxxxxx@qq.m',
self.password = '********'
self.postKey = []
#获取此次session的post_key
def getPostKey(self):
loginHtml = s.get(self.baseUrl)
pattern = re.compile('<input type="hidden".*?value="(.*?)">', re.S)
result = re.search(pattern, loginHtml.text)
self.postKey = result.group(1)
#获取登陆后的页面
def getPageAfterLogin(self):
loginData = {"pixiv_id": self.pixiv_id, "password": self.password, 'post_key': self.postKey, 'return_to': self.return_to}
s.post(self.LoginUrl, data = loginData, headers = self.loginHeader)
targetHtml = s.get(self.firstPageUrl)
return targetHtml.text可以说登录这一步是最难的了,因为网上找不到任何反爬虫的内容和post_key相关的,实际到现在我也不是太清楚它具体的机制。每个网站都有自己的方法来增加安全性,第一个尝试的人可能都会感觉比较难吧,当然也可能因为我是外行,只学了三天python还有两年前学的计算机网络。。后面的话其实就和平常的爬虫代码差不多了,分析网页,获取图片源地址,下载到本地,因为这一次只是一个尝试的过程,所以选取的任务比较简单,就是爬取关注的千叶大大@千叶QY3的所有作品,其实一开始想爬Miku标签下所有高赞作品的,过两天尝试了一下也实现了python使用requests和BeautifulSoup包爬取Pixiv图片--指定tag下的所有作品
然后开始码代码吧,我这里用的是requests包,感觉比urllib2+cookielib的方式确实简单很多。
#获取每页每一张图片的详细页面地址,总共11页作品
def getImgDetailPage(self, pageHtml):
pattern = re.compile('<li class="image-item.*?<a href="(.*?)" class="work _work.*?</a>', re.S)
imgPageUrls = re.findall(pattern, pageHtml)
return imgPageUrls#打开图片详细页面,获得图片对应的最大分辨率图片
def getImg(self, pageUrls):
#查找本页面内最大分辨率的图片的url的正则表达式
pattern = re.compile('<div class="_illust_modal.*?<img alt="(.*?)".*?data-src="(.*?)".*?</div>', re.S)
for pageUrl in pageUrls:
#之前查找得到的只是图片页面的半截url,这里加上前缀使之完整
wholePageUrl = 'http://www.pixiv.net' + str(pageUrl)
pageHtml = s.get(wholePageUrl).text
result = re.search(pattern, pageHtml) #如果这个页面只有一张图片,那就返回那张图片的url和名字,如果是多张图片 那就找不到返回none
if(result):
imgName = result.group(1)
imgSourceUrl = result.group(2)
print u'这个地址含有1张图片,地址:' + wholePageUrl
print u'正在获取第1张图片.....'
print u'名字: ' + result.group(1)
print u'源地址:' + result.group(2)
self.getBigImg(imgSourceUrl, wholePageUrl, imgName)
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
else:
self.getMultipleImg(wholePageUrl) #否则执行多张图片时的特殊处理方法这里要说一下 ,因为pixiv将原图压缩很多次,有各种不同分辨率的图,当然我们想要的是最大分辨率的,最小的就是在所有作品那里看到的,你也可以直接抓那个,如果用来做深度学习的训练数据足够了,其次是点开一张图片看到的 下面就有评论那种,最大的是要在图片详情页点图片此时页面只有一张图片,其他什么都没有,我们要最后一个的url。另外还要注意有的一个作品它有好几张,但有的你点开它不止一张,这种的html和单张图片的不怎么一样,需要重新分析并提取地址,相当于在那个图片详情页面的地址再多点一次才能提取到想要的最大分辨率图片的url,这里也花了很长时间,我的代码如下,可以参考python爬虫学习--pixiv爬虫(2)--国际排行榜的图片爬取,里面的对P站三种不同图片(单图,多图,动图)的处理方法,比我不知高到哪去了,后悔没有一开始看到他的解决方法。不过算了一下,感觉复杂度都是差不多的,毕竟就这么几行代码,不过那篇博客的代码确实更优秀,值得学习。
#多张图片的处理方法
def getMultipleImg(self, wholePageUrl):
imgAlmostSourceUrl = str(wholePageUrl).replace("medium", "manga")
header = {
'Referer': imgAlmostSourceUrl,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
}
pageHtml = s.get(imgAlmostSourceUrl, headers = header).text
totalNumPattern = re.compile('<span class="total">(\d)</span></div>', re.S) #找到这一页共有几张图
totalNum = re.search(totalNumPattern, pageHtml)
#运行了一段时间报错,因为动图这里处理不了,实在没精力了,暂时不抓动图了吧。。。
if (totalNum):
print u'这个地址含有' + totalNum.group(1) + u'张图片,转换后的
f309
地址:' + str(imgAlmostSourceUrl)
urlPattern = re.compile('<div class="item-container.*?<img src=".*?".*?data-src="(.*?)".*?</div>', re.S)
namePattern = re.compile('<section class="thumbnail-container.*?<a href="/member_illust.*?>(.*?)</a>', re.S)
urlResult = re.findall(urlPattern, pageHtml)
nameResult = re.search(namePattern, pageHtml)
for index,item in enumerate(urlResult):
print u'正在获取第' + str(index + 1) + u'张图片......'
print u'名字: ' + nameResult.group(1) + str(index + 1)
print u'源地址:' + item
self.getBigImg(item, wholePageUrl, nameResult.group(1)+str(index + 1))
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
else:
print u'这个网址是一个gif,实在没精力去研究怎么保存动图了。。跳过吧'
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'然后下载图片到本地#下载指定url的图片
def getBigImg(self, sourceUrl, wholePageUrl, name):
header = {
'Referer': wholePageUrl, #这个referer必须要,不然get不到这个图片,会报403Forbidden,具体机制也不是很清楚,可能也和cookies之类的有关吧
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
}
img = s.get(sourceUrl, headers = header)
f = open(name + '.jpg', 'wb') #写入多媒体文件要 b 这个参数
f.write(img.content) #多媒体文件要是用conctent
f.close()#输入文件夹名,创建文件夹
def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
if not isExists:
print u'建了一个名字叫做' + path + u'的文件夹!'
os.makedirs(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
return True
else:
print u'名字叫做' + path + u'的文件夹已经存在了!'
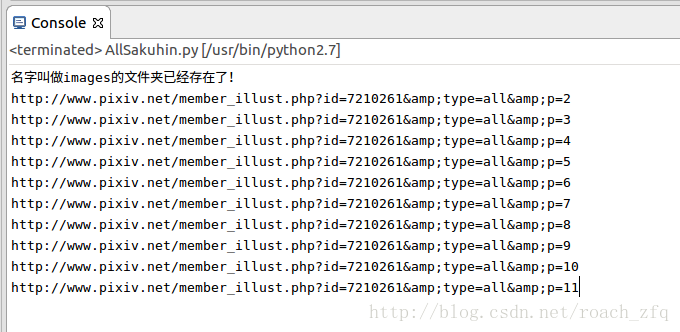
return False关于如何获取下一页作品的html,因为在第一页html中没有找打总共有多少页,所以只能用while循环来判断获取页面上下一页按钮得到的url是否为空来结束,不过后来在其他博客里看到第一页可以获取总共作品的数量,然后每一页20个,用总数量除以20向上取整就得到总页数了,这个方法也是可行的。这里先把获取每一页上的图片注释掉,测试一下我的方法能否正常工作,如下:
#输入文件夹名,创建文件夹
def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
if not isExists:
print u'建了一个名字叫做' + path + u'的文件夹!'
os.makedirs(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path))
return True
else:
print u'名字叫做' + path + u'的文件夹已经存在了!'
return False
def start(self):
pathName = 'images'
self.mkdir(pathName) #调用mkdir函数创建文件夹!这儿path是文件夹名
os.chdir(pathName) #切换到目录
self.getPostKey() #获得此次会话的post_key
firstPageHtml = self.getPageAfterLogin() #从第一页url开始
imgPageUrls = self.getImgDetailPage(firstPageHtml) #获取第一页所有图片url
# self.getImg(imgPageUrls) #获取第一页所有图片url所指向页面的一张或多张图片
currentPageUrl = self.getNextUrl(firstPageHtml)
while(currentPageUrl):
print currentPageUrl
currentPageHtml = self.getPageWithUrl(currentPageUrl)
imgPageUrls = self.getImgDetailPage(currentPageHtml)
# self.getImg(imgPageUrls)
currentPageUrl = self.getNextUrl(currentPageHtml)
p = Pixiv()
p.start()运行结果:
说明这种方法还是可行的。
下面整理一下,贴上完整的,并运行
# -*- coding:utf-8 -*-
#created by zfq
#first edited: 2016.12.08
import requests
import re
import os
s = requests.Session()
class Pixiv:
def __init__(self):
self.baseUrl = "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index"
self.LoginUrl = "https://accounts.pixiv.net/api/login?lang=zh"
self.firstPageUrl = 'http://www.pixiv.net/member_illust.php?id=7210261&type=all'
self.loginHeader = {
'Host': "accounts.pixiv.net",
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36",
'Referer': "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index",
'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8",
'Connection': "keep-alive"
}
self.return_to = "http://www.pixiv.net/"
self.pixiv_id = '7xxxxxxxx.com',
self.password = 'xxxxxxx'
self.postKey = []
#获取此次session的post_key
def getPostKey(self):
loginHtml = s.get(self.baseUrl)
pattern = re.compile('<input type="hidden".*?value="(.*?)">', re.S)
result = re.search(pattern, loginHtml.text)
self.postKey = result.group(1)
#获取登陆后的页面
def getPageAfterLogin(self):
loginData = {"pixiv_id": self.pixiv_id, "password": self.password, 'post_key': self.postKey, 'return_to': self.return_to}
s.post(self.LoginUrl, data = loginData, headers = self.loginHeader)
targetHtml = s.get(self.firstPageUrl)
return targetHtml.text
#获取页面
def getPageWithUrl(self, url):
return s.get(url).text
#获取下一页url
def getNextUrl(self, pageHtml):
pattern = re.compile('<ul class="page-list.*?<span class="next.*?href="(.*?)" rel="next"', re.S)
url = re.search(pattern, pageHtml)
if url:
#如果存在,则返回url
nextUrl = 'http://www.pixiv.net/member_illust.php' + str(url.group(1))
return nextUrl
else:
return None
#获取每一页每一张图片的详细页面地址
def getImgDetailPage(self, pageHtml):
pattern = re.compile('<li class="image-item.*?<a href="(.*?)" class="work _work.*?</a>', re.S)
imgPageUrls = re.findall(pattern, pageHtml)
return imgPageUrls
#下载指定url的图片
def getBigImg(self, sourceUrl, wholePageUrl, name):
header = {
'Referer': wholePageUrl,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
}
imgExist = os.path.exists('/home/zfq/workspace/Pixiv/QianYe/images/' + name + '.jpg')
if (imgExist):
print u'该图片已经存在,不用再次保存,跳过!'
else:
img = s.get(sourceUrl, headers = header)
f = open(name + '.jpg', 'wb') #写入多媒体文件要 b 这个参数
f.write(img.content) #多媒体文件要是用conctent!
f.close()
#打开图片详细页面,获得图片对应的最大分辨率图片
def getImg(self, pageUrls):
#查找本页面内最大分辨率的图片的url的正则表达式
pattern = re.compile('<div class="_illust_modal.*?<img alt="(.*?)".*?data-src="(.*?)".*?</div>', re.S)
for pageUrl in pageUrls:
#之前查找得到的只是图片页面的半截url,这里加上前缀使之完整
wholePageUrl = 'http://www.pixiv.net' + str(pageUrl)
pageHtml = self.getPageWithUrl(wholePageUrl)
result = re.search(pattern, pageHtml) #如果这个页面只有一张图片,那就返回那张图片的url和名字,如果是多张图片 那就找不到返回none
if(result):
imgName = result.group(1)
imgSourceUrl = result.group(2)
print u'这个地址含有1张图片,地址:' + wholePageUrl
print u'正在获取第1张图片.....'
print u'名字: ' + result.group(1)
print u'源地址:' + result.group(2)
self.getBigImg(imgSourceUrl, wholePageUrl, imgName)
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
else:
self.getMultipleImg(wholePageUrl) #否则执行多张图片时的特殊处理方法
#多张图片的处理方法
def getMultipleImg(self, wholePageUrl):
imgAlmostSourceUrl = str(wholePageUrl).replace("medium", "manga")
pageHtml = self.getPageWithUrl(imgAlmostSourceUrl)
totalNumPattern = re.compile('<span class="total">(\d)</span></div>', re.S) #找到这一页共有几张图
totalNum = re.search(totalNumPattern, pageHtml)
#运行了一段时间报错,因为动图这里处理不了,实在没精力了,暂时不抓动图了吧。。。
if (totalNum):
print u'这个地址含有' + totalNum.group(1) + u'张图片,转换后的地址:' + str(imgAlmostSourceUrl)
urlPattern = re.compile('<div class="item-container.*?<img src=".*?".*?data-src="(.*?)".*?</div>', re.S)
namePattern = re.compile('<section class="thumbnail-container.*?<a href="/member_illust.*?>(.*?)</a>', re.S)
urlResult = re.findall(urlPattern, pageHtml)
nameResult = re.search(namePattern, pageHtml)
for index,item in enumerate(urlResult):
print u'正在获取第' + str(index + 1) + u'张图片......'
print u'名字: ' + nameResult.group(1) + str(index + 1)
print u'源地址:' + item
self.getBigImg(item, wholePageUrl, nameResult.group(1)+str(index + 1))
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
else:
print u'这个网址是一个gif,实在没精力去研究怎么保存动图了。。跳过吧'
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
#输入文件夹名,创建文件夹 def mkdir(self, path): path = path.strip() isExists = os.path.exists(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path)) if not isExists: print u'建了一个名字叫做' + path + u'的文件夹!' os.makedirs(os.path.join("/home/zfq/workspace/Pixiv/QianYe", path)) return True else: print u'名字叫做' + path + u'的文件夹已经存在了!' return False
def start(self):
pathName = 'images'
self.mkdir(pathName) #调用mkdir函数创建文件夹!这儿path是文件夹名
os.chdir(pathName) #切换到目录
self.getPostKey() #获得此次会话的post_key
firstPageHtml = self.getPageAfterLogin() #从第一页url开始
imgPageUrls = self.getImgDetailPage(firstPageHtml) #获取第一页所有图片url
self.getImg(imgPageUrls) #获取第一页所有图片url所指向页面的一张或多张图片
currentPageUrl = self.getNextUrl(firstPageHtml)
while(currentPageUrl):
currentPageHtml = self.getPageWithUrl(currentPageUrl)
imgPageUrls = self.getImgDetailPage(currentPageHtml)
self.getImg(imgPageUrls)
currentPageUrl = self.getNextUrl(currentPageHtml)
p = Pixiv()
p.start()
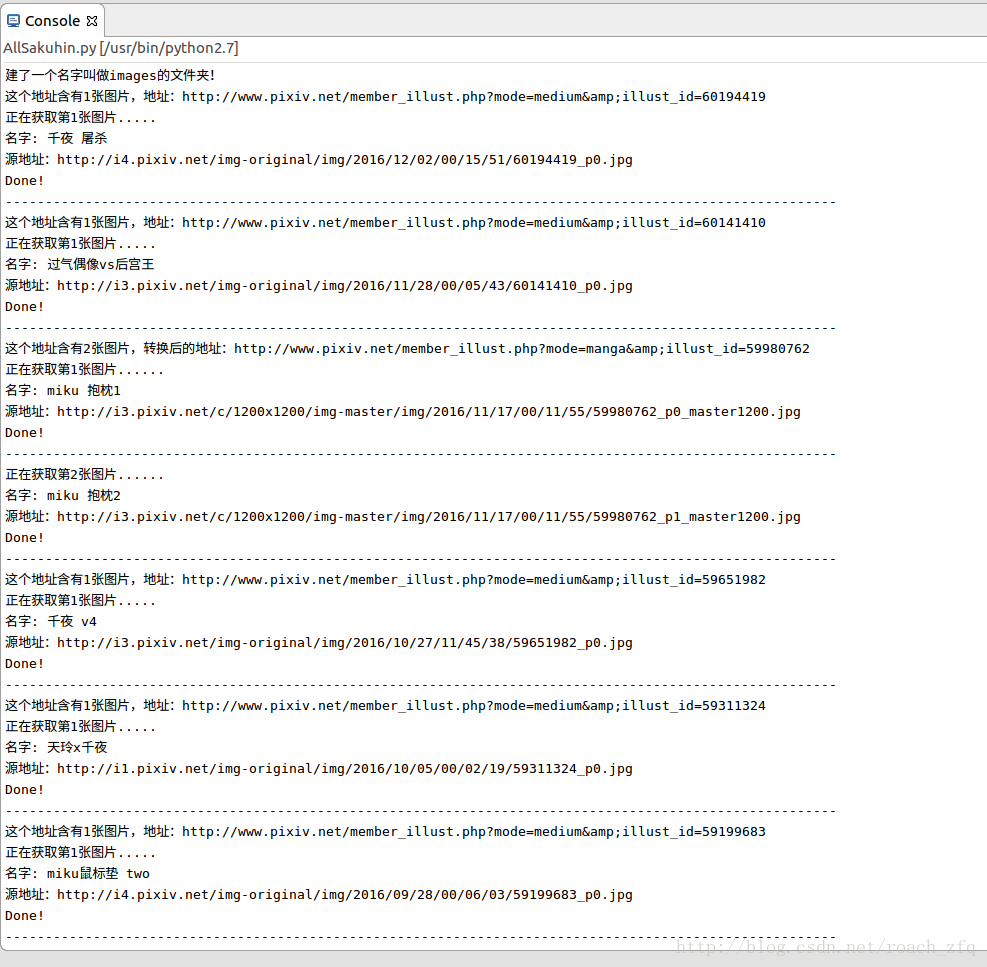
运行,并没有刷刷刷的效果,连接P站的速度很慢,可能因为P站是外源吧。。部分结果如下,总共就太长了,得运行很久:
偶尔还会在某一张图片卡很久,然后下载不全,可能也是因为网络的原因吧,像这样:
它底下是空的,乱码的。。这样的还好几张呢
最后看一下到目前的成果
才30几张,还有85%呢,让它跑一夜吧,完了再来更新。
第二早发现运行到第3页遇到第一个动图获取不了,于是添上了上面处理动图的方法。
不过偶尔会get不到某个指定url的页面,可能是P站的某种反爬虫技术吧,限制IP访问频率?限制User-Agent?不过又很不确定,有时候可以get上百张突然报错get不了,有时候才十几张就不让继续get,也还是没太多时间的原因,没有太多精力去研究了,暂且就这样吧,给它加了检查是否已经下载过该图片报错下载过的话自动跳过的语句,这样发生错误的话从错误的那一页重新开始就好了(将firstPageUrl设为该页的url)
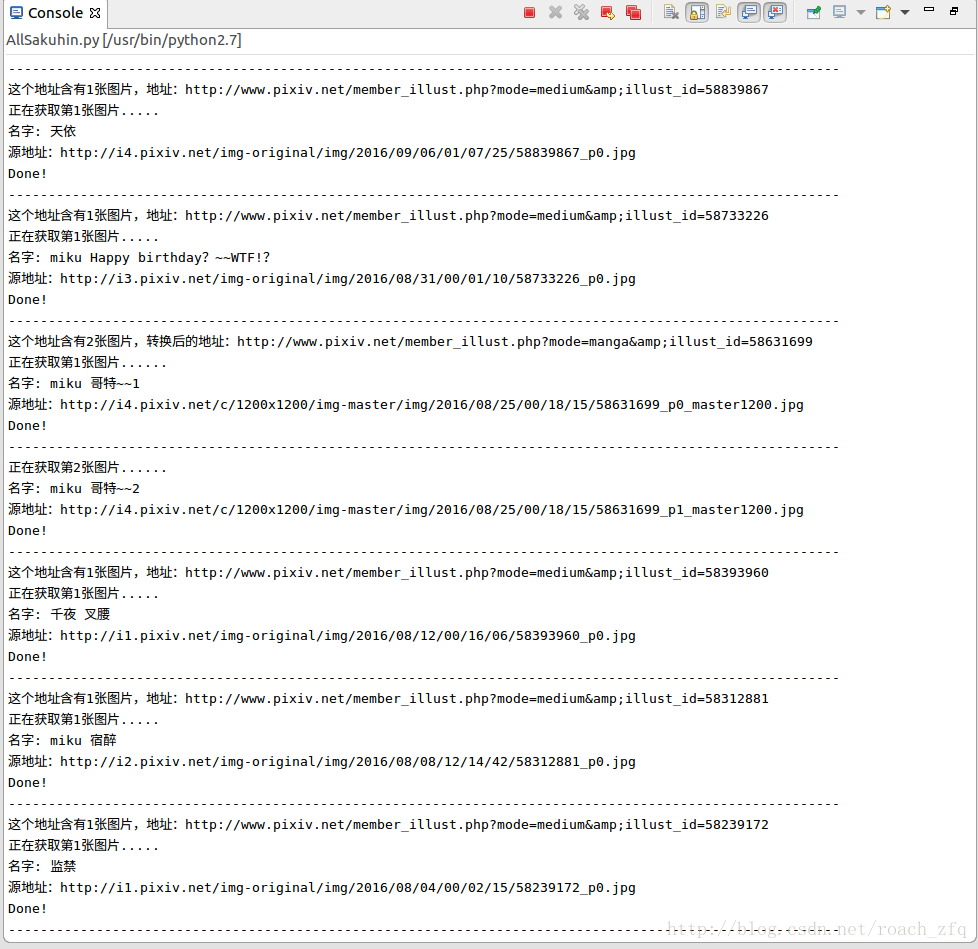
这样运行一会的话,有这样的结果:
重新从某一页开始获取时:
遇到gif是的情况:
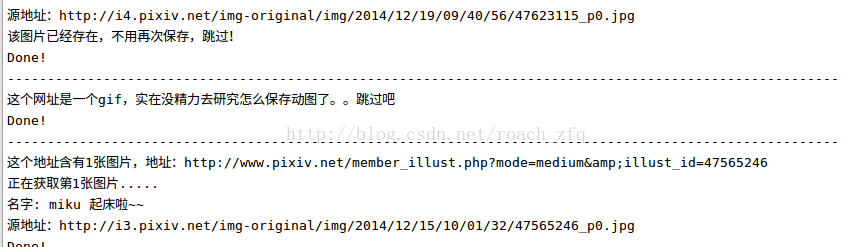
不过当所有都get完了从第一页再重新开始的时候,速度很快,刷刷刷的,大概用了3分钟检查完了所有11页的内容,中间没有任何阻碍,看来P站真的限制同一次会话get原图的次数?,你不去get原图只是依次check每一个原图的url就完全没问题。然后检查结果就是全都已经存在不用再保存,也顺便把那几张黑掉的图 如下图,删掉重新get到了完整的,今早的网还不错呢!>_<~~~
最后快结束时,get最后几张图片时的控制台输出:
这就是最后一张啦!运行结束啦~
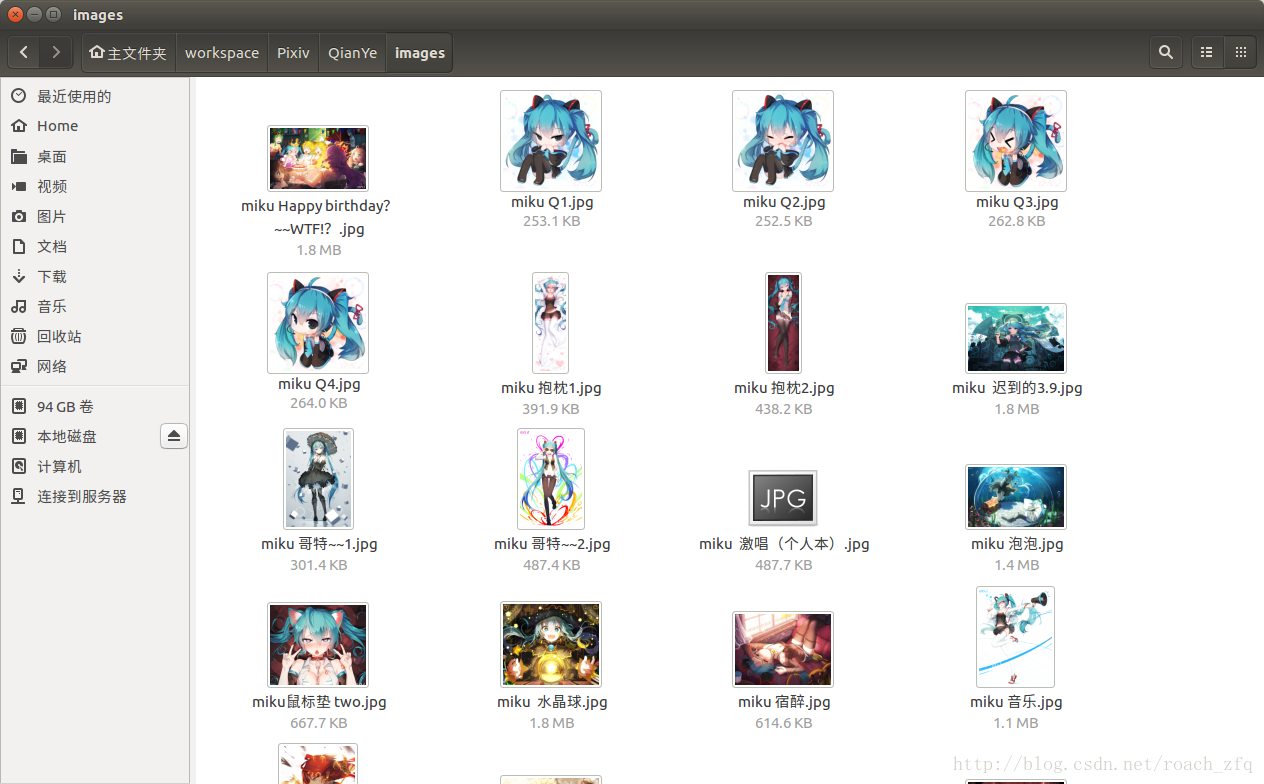
最后晒一下成果,总共219张图片:
注意全都是高清大图哦,每个1-2MB左右的,可以做桌面的那种,跟网页上看到的那种小图可不一样。。
遗留问题:代码不稳定,每次运行不确定的迭代次数后直到self.getPageWithUrl(Url)报错:requests.exceptions.ConnectionError: ('Connection aborted.', BadStatusLine("''",)),有时候可以直接运行到最后,get到所有的图片,有时候get到50张,有时候30,有时候甚至才几张就报错,不过增加了判断图片是否存在机制后直接运行就好 会跳过已经下载好的,目前不太清楚具体原因,这个可能要很深入的学习才能理解吧。
最后来张V家众人图,完结\(≧▽≦)/~
参考的文章:
Python爬虫之Pixiv(续)python爬虫学习--pixiv爬虫(3)--关注用户作品爬取
Python利用Requests库写爬虫(一)
感谢互联网,感谢他们的博客,学习了python:
崔庆才的个人博客Python快速教程

相关文章推荐
- python爬虫学习--pixiv爬虫(3)--关注用户作品爬取
- 使用Python正则表达式从文章中取出所有图片路径
- [Python 爬虫之路4] 使用selenium爬取知乎任意一个问题下,所有回答中的图片
- 用python下载xxxx网站封面作品的所有图片
- python程序设计基础5:python文件使用(遍历一个文件夹中所有的图片)
- 使用python查询某目录下所有‘jpg’结尾的图片文件
- 使用Python获取所有非偶数尺寸图片资源信息
- 使用python抓取CSDN关注人的所有发布的文章
- Android使用加载器(Loader)实现获取本机中所有图片
- python成长日记1:使用python访问网站,下载图片
- 使用Python抓取网页图片[转载]
- 使用ImageMagick进行图片缩放、合成与裁剪(js+python)
- 使用ImageMagick进行图片缩放、合成与裁剪(js+python)
- 使用python处理没有被Web用到的图片
- 使用Python下载Bing图片(代码)
- 使用Python编写客户端 上传文字or图片至新浪微博 by OAuth 2.0
- Python下使用qrcode模块生成vCard电子名片二维码图片
- [Python]_[使用正则表达式提取迅雷界面配置文件XLUE的图片]
- 使用Python将文本转为图片
- 使用Python编写客户端 上传文字or图片至新浪微博