王小草【深度学习】笔记第四弹--卷积神经网络与迁移学习
2016-12-08 17:08
351 查看
标签(空格分隔): 王小草深度学习笔记
图像识别,图像识别+定位,物体检测,图像分割。
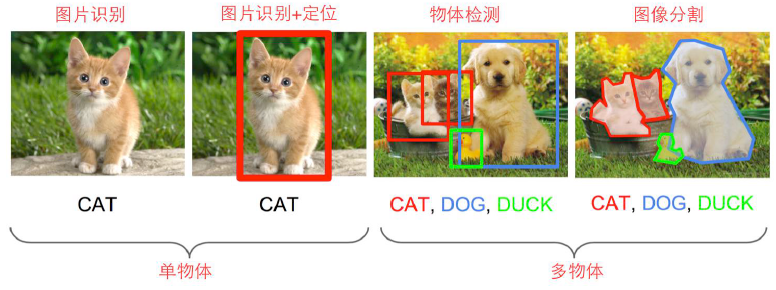
图像的定位就是指在这个图片中不但识别出有只猫,还把猫在图片中的位置给精确地抠出来今天我们来讲一讲如何神经网络来做图像识别与定位。
图像的识别:
可以看成是图像的分类》C个类别
输入:整个图片
输出:类别标签(每个类别会有一个概率,选出概率最大的标签)
评估标准:准确率
图形的定位:
输入:整个图像
输出:物体边界框(x,y,w,h)。x,y是物体边界框的左上定点的横纵坐标;w,h是这个图片的长和高。通过这4个指标就可以定位出图中的物体的位置。
评估标准:交并准则
所以图像的识别与定位就是以上两个任务组成。
下面介绍2中思路去实现图像的识别与定位。
与之前分类问题不同的是,现在我们使用L2loss也就是欧氏距离来求损失函数。
步骤1:
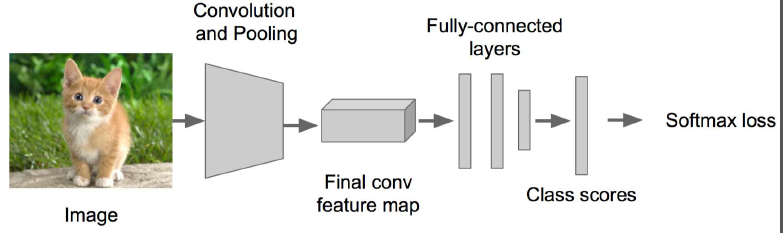
首先得搭一个图像识别的神经网络,可以在VGG,GoogleLenet这些优秀的模型上fine-tuning一下。
步骤2:
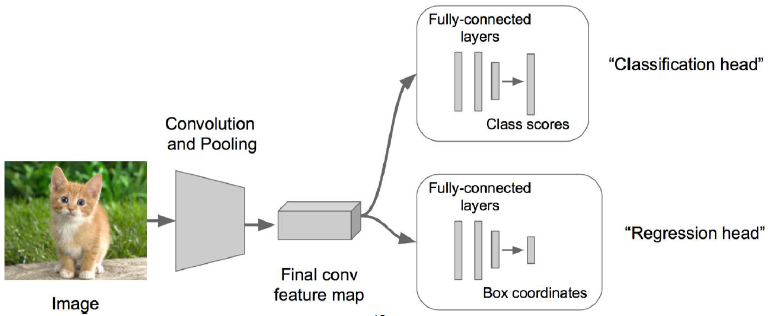
接下来在上述神经网络的尾部展开成两个部分:成为classification + regression的模式。前者是为了识别,后者是为了定位。一般这个展开会放在卷积层后面,也有时候放在全连接层后面。
步骤3:
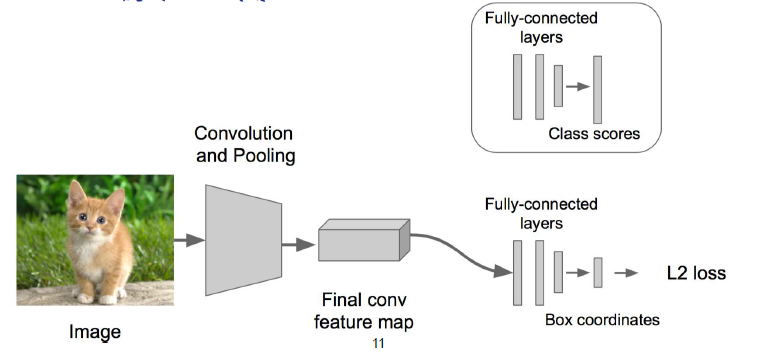
在regression回归部分使用欧氏距离计算损失,然后运用SGD来训练,在classification部分和以前一样不变。
步骤4:
在预测阶段,将classification和regression两个模块拼上,让他们各自去实现自己不同的功能。
regression模块加在什么位置呢?
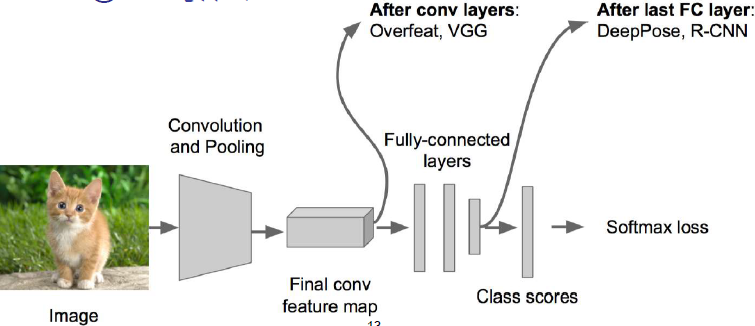
可以放在卷积层后,如VGG
也可以放在全连接层后, 如DeepPose
能否对主体有更细致的识别?
神经网络能够对图形进行定位,那么能否识别出这个物体在干啥子在做什么动作呢?
这也可以,需要提前把规定好K个组成部分,然后分别去做k个部分的回归就行了。
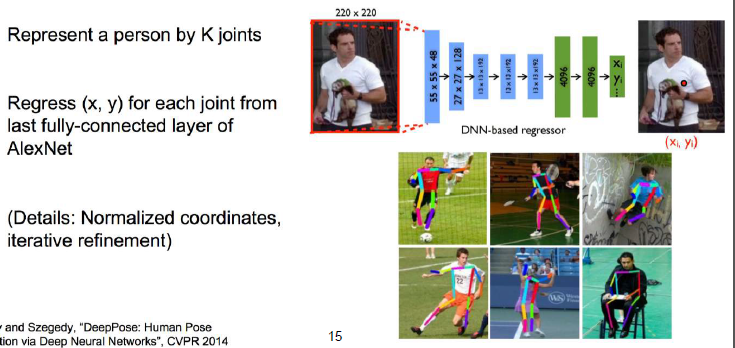
比如识别人的姿势,每个人的组成部分是固定的,可以将人分成K个首尾相接的线段,然后对这些线段分别求回归。
如下图,取一个3*221*221的一个框,让它在图像的4个位置走一遍,然后得出每个位置的得分,右下角的框得分最高,识别出猫的概率为0.8.

这个方法存在最大的问题是:“参数多”,“计算慢”。因为要去尝试不同大小的框并放在不同位置。但是论文中提到了解决这两个缺陷的方案。
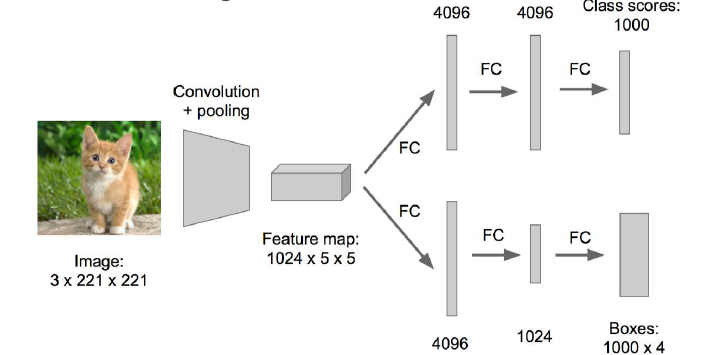
下图是神经网络最初的形式,从卷积层出来或分成了两个模块,每个模块中分别有及几层的全连接。如果FC层中的神经元有4096个,那么这个过程会产生4096*4096个参数。
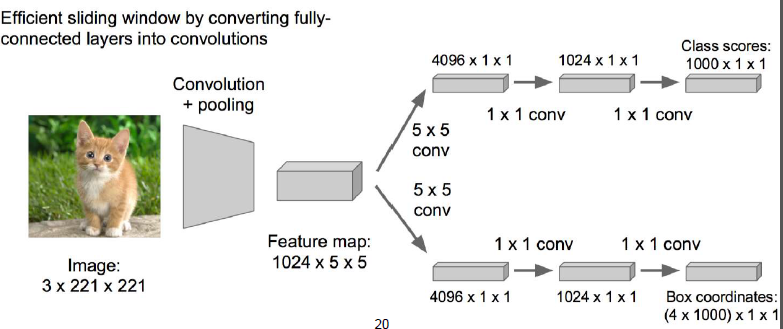
论文作者提出了这样的方案,从卷积层出来后的两个模块中,将FC层乘以一个1*1的conv卷积层,那么参数的数量就下降到了4069*1了。
论文里的东东拿出来讲的要十分庞大,有兴趣的童鞋直接看原文论,哈哈。


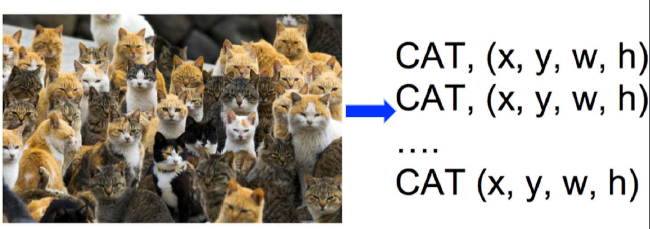
用回归来做物体识别需要先确定物体的个数K。但是通常情况下,我们并不知道图像中有多少个物体,就像下图这样。
于是我们又回到了分类问题,让不同大小的框去移动然后做分类,就像下图这样。

但是分类问题来做物体识别也有难处:
–你需要找很多位置,还需要设定很多不同大小的框
–还要对每个框在每个位置的图像做分类
–而且你选的框的大小也不一定对啊
–…..
–也就是说,想办法找到包含内容的图框。
原理是这样的,先找到一个像素点,然后将它周围与它相近的点也包罗进来形成了一个小的候选框,这些小的候选框再向周围扩张,将颜色相似的点包含进来,如此一轮一轮候选框就会逐渐扩大了。具体过程如下图:
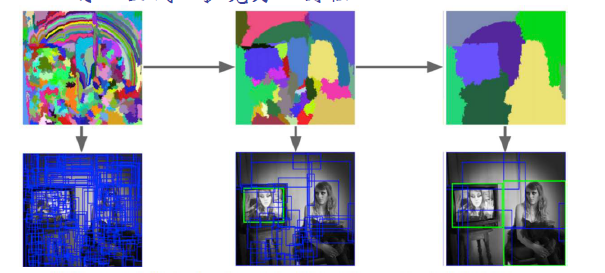
最后一张图中其实已经非常清晰地识别出来墙上的相框和旁边的美女了。
它的实验大概是这样做的:
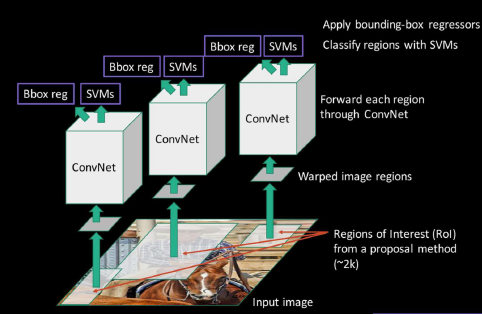
首先对图片使用边缘策略进行物体识别,然后将每个候选框输入卷积层产出特征,接着一边让卷基层的输出进入SVM做一个“有无物体”的分类,如果有的话就进行回归计算。回归计算是去调整候选框,使其能刚好抠出一个物体。
有兴趣的童鞋还是可以去看原版论文:

这是这位童鞋与好基友在玩耍的照片

这是家喻户晓的名画“星空”

做了融合之后,这是星空风格的基友玩耍图:

有木有醉醉的。类似的例子有多,比如:

再比如:

还比如:

也就是说,你可以把任何一张以自己的或是猫猫狗狗的或是风景的照片,变换成任何风格的大师作品。
总结一下,就是酱紫的:

我的中文翻译链接:
看论文有点绕绕的,还是我来总结一下。
首先,明确我们有三张图,一张图是照片,一张图是画作,一张是融合了画作风格和照片内容的新图。既然这张新图是来自于照片的内容,和画作的风格,那么这张新图必然与照片在内容上的差距越小越好,与画作在风格上的差距越小越好。这么说,我们找到了目标,有了目标就可以建立目标函数,这里是建立两个损失函数,即:
loss_total = loss(照片内容-新图内容)+ loss(画作风格-新图风格)。
这就是我们的目标函数。当目标函数最小的时候所生成的新图就是我们要得到的结果!
那么问题来了,如何提取照片的内容,和画作的风格呢?
提取照片的内容:
首先,让我们站上巨人的肩膀上,下载一个已经搭建好的并且非常棒的卷积神经网络模型,比如VGG,比如Alexnet.论文中用的是VGG, 我们这边用Alexnet.
然后我们往这个模型中输入一张照片(注意我们现在要提取内容,所以输入的是照片)
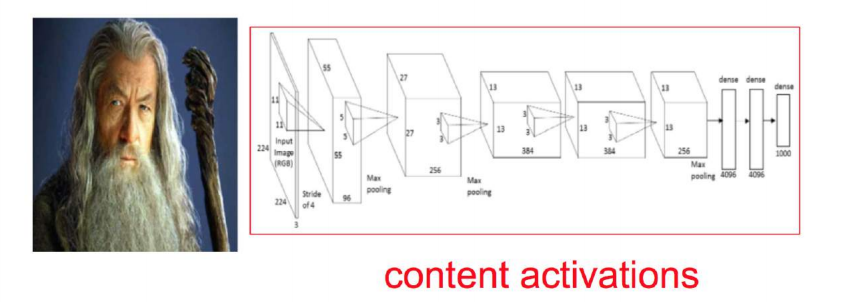
这张照片一层一层地经过卷基层,在第5层的时候输出的是一个14*14*256的矩阵。256是第五层卷基层中神经元的个数,不同的模型不同,也可以自己调整,这边只是举个例子。14 * 14 是一个feature map,所以这里总共有256个feature map.我们知道一个神经元会关注某一个特征,所以一个feature map隐含着一类特征信息。而这一整个14 * 14 * 256的输出我们称之为content representation–内容表征。也就是我们提取出来的“照片内容”。
这里注意的是,我们直接使用了Alexnet,它已经训练好了权重即其他所有参数,我们不需要去训练得到,在这里,我们直接使用这些参数,做一次前向计算,将图片输出成内容的表征。
提取画作的风格:
首先,我们仍然直接使用Alexnet这个模型。
然后向这个模型输入一张画作:

这张画作经过层层卷基层进行前向计算,在某一层,比如第一层的输出是224 * 224 * 64,同样,64是这一层神经元的个数,可以自己调整的。于是可以看成是有64个224*224的二维矩阵。
接下来是重点。
我们将这64个平面两两做点乘,最后会得到64 * 64 的矩阵,这个矩阵,就是style representation–风格表征。叫做gram matrix.
建立目标函数:
我们已经提取了照片的内容和画作的风格,但是我们需要将它们分别与新图做比较。于是,我们也需要将新图分别输入这两个神经网络,并且提取出新图的内容和新图的风格。
那么问题又来了,新图是我们要最后生成的图,我们一开始是没有的,怎么输入?
是这样滴,在一开始的时候我们会随机定义一个新图,这个随机真的是随便的,你可以把照片作为初始的新图,也可以把画作作为初始的新图,也可以随机产生任何一张新图。
将这张初始的新图输入两个模型中分别会得到一个内容表征与一个风格表征。
于是,我们就可以建立完整的损失函数了!:
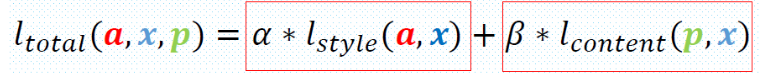
p是照片,a是画作,x是新图。
Lcontent是照片与新图的内容上的差距,即对应位置相减的平方和,之所以乘以1/2是为了求导方便。
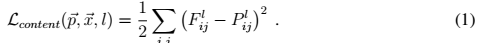
Lstyle是画作与新图在风格上的差距,也是差值的平方和,公式与上同
α和β分别是内容和风格两个损失的权重。α+β=1.如果α比较大,那么输出后的新图会更多地倾向于内容上的吻合,如果β较大,那么输出的新图会更倾向于与风格的吻合。这两个参数是一个trade-off,可以根据自己需求去调整最好的平衡。论文的作者给出了它调整参数的不同结果,如下图,从左到右四列分别是α/β = 10^-5, 10^-4,10^-3, 10^-2.也就是α越来越大,的确图像也越来越清晰地呈现出了照片的内容。

现在损失函数已经确定了,在这个损失函数中,所有的模型的参数都是一开始就给定的,不需要去调整。在训练过程中,需要调整与更新的是输入的新图x。最后输出的是,是的损失函数最小的时候的新图!这样,本次大师模仿秀就完美结束了。
tensorflow源码链接:https://github.com/Christiph/neural-style
1. 图像识别与定位
图像的相关任务可以分成以下两大类和四小类:图像识别,图像识别+定位,物体检测,图像分割。
图像的定位就是指在这个图片中不但识别出有只猫,还把猫在图片中的位置给精确地抠出来今天我们来讲一讲如何神经网络来做图像识别与定位。
图像的识别:
可以看成是图像的分类》C个类别
输入:整个图片
输出:类别标签(每个类别会有一个概率,选出概率最大的标签)
评估标准:准确率
图形的定位:
输入:整个图像
输出:物体边界框(x,y,w,h)。x,y是物体边界框的左上定点的横纵坐标;w,h是这个图片的长和高。通过这4个指标就可以定位出图中的物体的位置。
评估标准:交并准则
所以图像的识别与定位就是以上两个任务组成。
下面介绍2中思路去实现图像的识别与定位。
1.1 思路1:视作回归
对于图像定位来说只要求出了(x,y,w,h)这四个值就得到了定位,因为这四个值是连续性,所以不能用分类的方法来做,这里考虑用回归来做。与之前分类问题不同的是,现在我们使用L2loss也就是欧氏距离来求损失函数。
步骤1:
首先得搭一个图像识别的神经网络,可以在VGG,GoogleLenet这些优秀的模型上fine-tuning一下。
步骤2:
接下来在上述神经网络的尾部展开成两个部分:成为classification + regression的模式。前者是为了识别,后者是为了定位。一般这个展开会放在卷积层后面,也有时候放在全连接层后面。
步骤3:
在regression回归部分使用欧氏距离计算损失,然后运用SGD来训练,在classification部分和以前一样不变。
步骤4:
在预测阶段,将classification和regression两个模块拼上,让他们各自去实现自己不同的功能。
regression模块加在什么位置呢?
可以放在卷积层后,如VGG
也可以放在全连接层后, 如DeepPose
能否对主体有更细致的识别?
神经网络能够对图形进行定位,那么能否识别出这个物体在干啥子在做什么动作呢?
这也可以,需要提前把规定好K个组成部分,然后分别去做k个部分的回归就行了。
比如识别人的姿势,每个人的组成部分是固定的,可以将人分成K个首尾相接的线段,然后对这些线段分别求回归。
1.2 思路2:借助图像窗口
另一个思路是来自于2014年发表的一篇论文。它的逻辑是这样的:取不同大小的“框”,让框出现在不同位置,判定每个框在每个为上的得分,按照得分高低对结果宽工作抽取与合并。如下图,取一个3*221*221的一个框,让它在图像的4个位置走一遍,然后得出每个位置的得分,右下角的框得分最高,识别出猫的概率为0.8.
这个方法存在最大的问题是:“参数多”,“计算慢”。因为要去尝试不同大小的框并放在不同位置。但是论文中提到了解决这两个缺陷的方案。
下图是神经网络最初的形式,从卷积层出来或分成了两个模块,每个模块中分别有及几层的全连接。如果FC层中的神经元有4096个,那么这个过程会产生4096*4096个参数。
论文作者提出了这样的方案,从卷积层出来后的两个模块中,将FC层乘以一个1*1的conv卷积层,那么参数的数量就下降到了4069*1了。
论文里的东东拿出来讲的要十分庞大,有兴趣的童鞋直接看原文论,哈哈。
2. 物体识别
2.1 背景
在衣服图中可能有多个物体,此时就需要去把每个物体都识别出来。比如下图中有4个物体,两个猫星人,一个汪星人,一个小鸭子。如果用回归,要去识别四个物体就需要预测4*4 = 16 个连续值了。用回归来做物体识别需要先确定物体的个数K。但是通常情况下,我们并不知道图像中有多少个物体,就像下图这样。
于是我们又回到了分类问题,让不同大小的框去移动然后做分类,就像下图这样。
但是分类问题来做物体识别也有难处:
–你需要找很多位置,还需要设定很多不同大小的框
–还要对每个框在每个位置的图像做分类
–而且你选的框的大小也不一定对啊
–…..
2.2 边缘策略
我们来换一个角度想问题,为什么要用那么多的框大海捞针呢,为什么不在图中先找到一个可能成框的东东作为候选框呢。–也就是说,想办法找到包含内容的图框。
原理是这样的,先找到一个像素点,然后将它周围与它相近的点也包罗进来形成了一个小的候选框,这些小的候选框再向周围扩张,将颜色相似的点包含进来,如此一轮一轮候选框就会逐渐扩大了。具体过程如下图:
最后一张图中其实已经非常清晰地识别出来墙上的相框和旁边的美女了。
2.3 R-CNN
一个大牛在2014年发表了一篇物体识别的论文。它的实验大概是这样做的:
首先对图片使用边缘策略进行物体识别,然后将每个候选框输入卷积层产出特征,接着一边让卷基层的输出进入SVM做一个“有无物体”的分类,如果有的话就进行回归计算。回归计算是去调整候选框,使其能刚好抠出一个物体。
有兴趣的童鞋还是可以去看原版论文:
3. Neural Style
人人都是梵高
有没有这样一个可能,传入一张我的自画像,再传入一张大师的画作,然后将我的自画像变成大师画作一样的风格。2015年,德国的几位同学,本来想研究研究有没有新的更优秀的损失函数,不小心发现了用卷积神经网络提取图像风格的方法。这么一来,我们是不是可以一方面提取出自己照片内的内容,一方面提取出大师画作的风格,将两者融合,就等于让大师帮我画了一张自画像了。说得如果有点绕,来看看一个中国的童鞋做的一个案例这是这位童鞋与好基友在玩耍的照片
这是家喻户晓的名画“星空”
做了融合之后,这是星空风格的基友玩耍图:
有木有醉醉的。类似的例子有多,比如:
再比如:
还比如:
也就是说,你可以把任何一张以自己的或是猫猫狗狗的或是风景的照片,变换成任何风格的大师作品。
总结一下,就是酱紫的:
原理介绍
原论文链接:https://arxiv.org/abs/1508.06576我的中文翻译链接:
看论文有点绕绕的,还是我来总结一下。
首先,明确我们有三张图,一张图是照片,一张图是画作,一张是融合了画作风格和照片内容的新图。既然这张新图是来自于照片的内容,和画作的风格,那么这张新图必然与照片在内容上的差距越小越好,与画作在风格上的差距越小越好。这么说,我们找到了目标,有了目标就可以建立目标函数,这里是建立两个损失函数,即:
loss_total = loss(照片内容-新图内容)+ loss(画作风格-新图风格)。
这就是我们的目标函数。当目标函数最小的时候所生成的新图就是我们要得到的结果!
那么问题来了,如何提取照片的内容,和画作的风格呢?
提取照片的内容:
首先,让我们站上巨人的肩膀上,下载一个已经搭建好的并且非常棒的卷积神经网络模型,比如VGG,比如Alexnet.论文中用的是VGG, 我们这边用Alexnet.
然后我们往这个模型中输入一张照片(注意我们现在要提取内容,所以输入的是照片)
这张照片一层一层地经过卷基层,在第5层的时候输出的是一个14*14*256的矩阵。256是第五层卷基层中神经元的个数,不同的模型不同,也可以自己调整,这边只是举个例子。14 * 14 是一个feature map,所以这里总共有256个feature map.我们知道一个神经元会关注某一个特征,所以一个feature map隐含着一类特征信息。而这一整个14 * 14 * 256的输出我们称之为content representation–内容表征。也就是我们提取出来的“照片内容”。
这里注意的是,我们直接使用了Alexnet,它已经训练好了权重即其他所有参数,我们不需要去训练得到,在这里,我们直接使用这些参数,做一次前向计算,将图片输出成内容的表征。
提取画作的风格:
首先,我们仍然直接使用Alexnet这个模型。
然后向这个模型输入一张画作:
这张画作经过层层卷基层进行前向计算,在某一层,比如第一层的输出是224 * 224 * 64,同样,64是这一层神经元的个数,可以自己调整的。于是可以看成是有64个224*224的二维矩阵。
接下来是重点。
我们将这64个平面两两做点乘,最后会得到64 * 64 的矩阵,这个矩阵,就是style representation–风格表征。叫做gram matrix.
建立目标函数:
我们已经提取了照片的内容和画作的风格,但是我们需要将它们分别与新图做比较。于是,我们也需要将新图分别输入这两个神经网络,并且提取出新图的内容和新图的风格。
那么问题又来了,新图是我们要最后生成的图,我们一开始是没有的,怎么输入?
是这样滴,在一开始的时候我们会随机定义一个新图,这个随机真的是随便的,你可以把照片作为初始的新图,也可以把画作作为初始的新图,也可以随机产生任何一张新图。
将这张初始的新图输入两个模型中分别会得到一个内容表征与一个风格表征。
于是,我们就可以建立完整的损失函数了!:
p是照片,a是画作,x是新图。
Lcontent是照片与新图的内容上的差距,即对应位置相减的平方和,之所以乘以1/2是为了求导方便。
Lstyle是画作与新图在风格上的差距,也是差值的平方和,公式与上同
α和β分别是内容和风格两个损失的权重。α+β=1.如果α比较大,那么输出后的新图会更多地倾向于内容上的吻合,如果β较大,那么输出的新图会更倾向于与风格的吻合。这两个参数是一个trade-off,可以根据自己需求去调整最好的平衡。论文的作者给出了它调整参数的不同结果,如下图,从左到右四列分别是α/β = 10^-5, 10^-4,10^-3, 10^-2.也就是α越来越大,的确图像也越来越清晰地呈现出了照片的内容。
现在损失函数已经确定了,在这个损失函数中,所有的模型的参数都是一开始就给定的,不需要去调整。在训练过程中,需要调整与更新的是输入的新图x。最后输出的是,是的损失函数最小的时候的新图!这样,本次大师模仿秀就完美结束了。
代码实现
代码链接:https://github.com/jcjohnson/neural-styletensorflow源码链接:https://github.com/Christiph/neural-style

相关文章推荐
- 网络 运输层(Transport)
- c# 使用Sharpcap进行网络数据包监听
- DHCP+HTTP+KICKSTART自动化光盘启动部署服务器
- 瞻博网络收购AppFormix“升级”的产品,听说财富500强企业都在用
- 瞻博网络收购AppFormix“升级”的产品,听说财富500强企业都在用
- Android新手系列教程(申明:来源于网络)
- Promise对象
- 3.2 神经网络基本结构及梯度下降算法
- HTTP 2.0与HTTP 1.1区别
- HTTP1.1协议详解
- 读《TCP/IP详解》第17、18章:TCP传输控制协议的连接和终止
- HTTP response codes
- windows7安装whl文件
- 【卷积神经网络-进化史】从LeNet到AlexNet
- TCP 粘包 和 拆包
- HttpClient4.5 SSL访问工具类
- iOS 升级HTTPS通过ATS你所要知道的
- TCP和UDP的区别
- Fiddler抓取HTTPs流量
- Chrome谷歌浏览器插件,Request Maker,用来模拟http 请求,这个插件怎么使用?