循环神经网络教程 Part 4笔记
2016-12-05 23:09
211 查看
Note: RECURRENT NEURAL NETWORK TUTORIAL, PART 4 – IMPLEMENTING A GRU/LSTM RNN WITH PYTHON AND THEANO
本教程包括以下几个部分
1.Introduction To RNNs
2.Implementing a RNN using Python and Theano
3.Understanding the Backpropagation Through Time (BPTT) algorithm and the vanishing gradient problem
4.Implementing a GRU/LSTM RNN
本文我们将学习LSTM网络和GRUs(Gated Recurrent Units).LSTMs首次由 Sepp Hochreiter和 Jürgen Schmidhuber于1997年提出。GRUs,于2014年首次使用,是LSTMs的一个简单变体。
ifogctst=σ(xtUi+st−1Wi)=σ(xtUf+st−1Wf)=σ(xtUo+st−1Wo)=σ(xtUg+st−1Wg)=ct−1∘f+g∘i=tanh(ct)∘o
i,f,o 分别叫做input,forget,output gates(门)。注意他们方程完全相同,只是参数不同。称其为门限,是因为sigmod函数将向量的值压缩到0-1之间,通过将其与另一个向量元素相乘,你就可以确定该向量的哪些部分可以通过。输入门定义了对输入新计算的状态的允许通过的部分。遗忘门定义了前一状态允许通过的程度,输出门定义了允许中间层输出暴露给外部网络的程度。
g是候选隐层状态,根据当前输入及前一隐层状态计算。与原始RNN计算方式完全相同。
ct是中间记忆单元。是前一状态和遗忘门的乘积,以及新状态g和输入门的乘积。
对于记忆ct。不是所有的中间状态层与隐层状态相关。
标准RNN可以看做LSTMs的一个特例。即输入门置1,遗忘门置0,输出门置1。
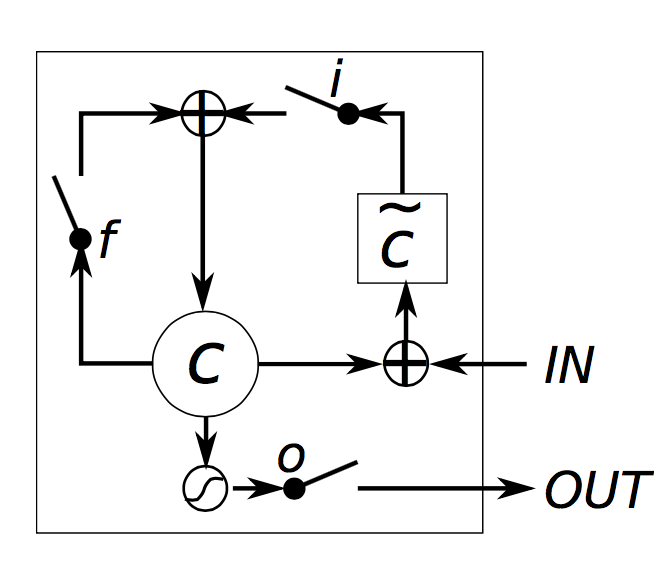
另外还有很多LSTM的变体。一个比较常见的变体是创建一个peephole连接,从而允许门限不仅依赖于上一隐层,还依赖于上一中间状态层。 LSTM: A Search Space Odyssey 介绍了各种LSTM结构。
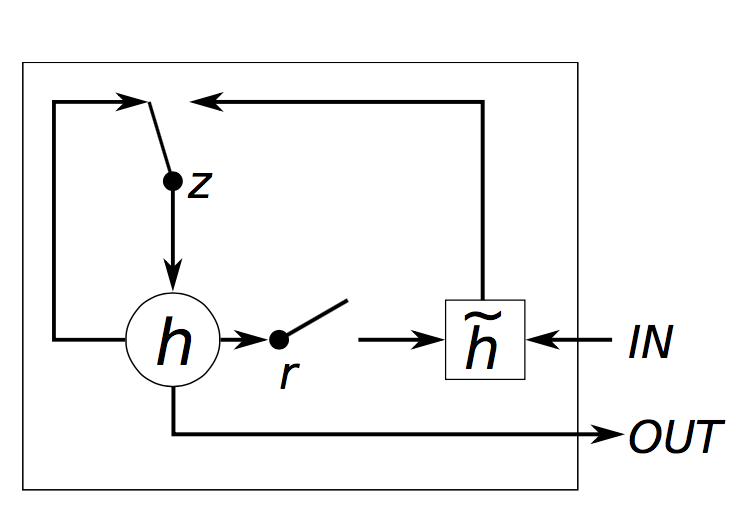
zrhst=σ(xtUz+st−1Wz)=σ(xtUr+st−1Wr)=tanh(xtUh+(st−1∘r)Wh)=(1−z)∘h+z∘st−1
GRU有两个门,重置门r,和更新门z。重置门决定如何将新的输入与先前记忆连接,更新门决定保留多少先前记忆。如果我们设置重置门为1,更新门为0,我们又得到标准RNN。利用门限机制学习长依赖的基本思想与LSTM相同,但有几点关键区别:
GRU有两个门限,LSTM有三个。
输入门和遗忘门通过更新门组合,重置门直接应用于前一隐层状态。因此,LSTM中的重置门的任务分担到(GRU中的)重置门与更新门中。
计算输出时没有采用第二个非线性单元。
参考博文
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano/
本教程包括以下几个部分
1.Introduction To RNNs
2.Implementing a RNN using Python and Theano
3.Understanding the Backpropagation Through Time (BPTT) algorithm and the vanishing gradient problem
4.Implementing a GRU/LSTM RNN
本文我们将学习LSTM网络和GRUs(Gated Recurrent Units).LSTMs首次由 Sepp Hochreiter和 Jürgen Schmidhuber于1997年提出。GRUs,于2014年首次使用,是LSTMs的一个简单变体。
LSTM网络
LSTMs我们通过一个门限机制设计用来处理梯度消失问题。首先来看LSTM如何计算隐层状态st(用∘代表元素相乘)ifogctst=σ(xtUi+st−1Wi)=σ(xtUf+st−1Wf)=σ(xtUo+st−1Wo)=σ(xtUg+st−1Wg)=ct−1∘f+g∘i=tanh(ct)∘o
i,f,o 分别叫做input,forget,output gates(门)。注意他们方程完全相同,只是参数不同。称其为门限,是因为sigmod函数将向量的值压缩到0-1之间,通过将其与另一个向量元素相乘,你就可以确定该向量的哪些部分可以通过。输入门定义了对输入新计算的状态的允许通过的部分。遗忘门定义了前一状态允许通过的程度,输出门定义了允许中间层输出暴露给外部网络的程度。
g是候选隐层状态,根据当前输入及前一隐层状态计算。与原始RNN计算方式完全相同。
ct是中间记忆单元。是前一状态和遗忘门的乘积,以及新状态g和输入门的乘积。
对于记忆ct。不是所有的中间状态层与隐层状态相关。
标准RNN可以看做LSTMs的一个特例。即输入门置1,遗忘门置0,输出门置1。
另外还有很多LSTM的变体。一个比较常见的变体是创建一个peephole连接,从而允许门限不仅依赖于上一隐层,还依赖于上一中间状态层。 LSTM: A Search Space Odyssey 介绍了各种LSTM结构。
GRUs
GRU的思想与LSTM十分类似,如公式:zrhst=σ(xtUz+st−1Wz)=σ(xtUr+st−1Wr)=tanh(xtUh+(st−1∘r)Wh)=(1−z)∘h+z∘st−1
GRU有两个门,重置门r,和更新门z。重置门决定如何将新的输入与先前记忆连接,更新门决定保留多少先前记忆。如果我们设置重置门为1,更新门为0,我们又得到标准RNN。利用门限机制学习长依赖的基本思想与LSTM相同,但有几点关键区别:
GRU有两个门限,LSTM有三个。
输入门和遗忘门通过更新门组合,重置门直接应用于前一隐层状态。因此,LSTM中的重置门的任务分担到(GRU中的)重置门与更新门中。
计算输出时没有采用第二个非线性单元。
GRU VS LSTM
许多任务中,GRU和LSTM具有相当的性能,超参数的调整比结构的选择更为重要。GRUs参数更少,因此训练速度会快一点,或者需要更少的数据去泛化。也就是说,如果你有更多的数据,LSTMs也许会有更好的结果。参考博文
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano/

相关文章推荐
- 循环神经网络教程 Part 1笔记
- 循环神经网络教程 Part 2笔记
- 循环神经网络教程 Part 3笔记
- 循环神经网络教程3-BP算法和梯度消失问题, Part 3 – Backpropagation Through Time and Vanishing Gradients
- [机器学习入门] 李宏毅机器学习笔记-33 (Recurrent Neural Network part 2;循环神经网络 part 2)
- [机器学习入门] 李宏毅机器学习笔记-32 (Recurrent Neural Network part 1;循环神经网络 part 1)
- 循环神经网络教程Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
- 循环神经网络教程4-用Python和Theano实现GRU/LSTM RNN, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano
- [机器学习入门] 李宏毅机器学习笔记-34 (Recurrent Neural Network part 3;循环神经网络 part 3)
- 循环神经网络教程-第二部分 用python numpy theano实现RNN
- UFLDL 教程学习笔记(一)神经网络
- TensorFlow深度学习笔记 循环神经网络实践
- 神经网络学习笔记-02-循环神经网络
- Stanford机器学习笔记-5.神经网络Neural Networks (part two)
- 循环神经网络教程第3部分 BPTT
- 神经网络学习笔记-02-循环神经网络
- UFLDL 教程学习笔记(一)神经网络
- CS231n 学习笔记(4)——神经网络 part4 :BP算法与链式法则
- UFLDL教程笔记及练习答案四(建立分类用深度学习---栈式自编码神经网络)
- Stanford机器学习笔记-4. 神经网络Neural Networks (part one)