Java数据结构和算法-栈和队列(1-前言+栈)
2016-12-05 15:09
190 查看
本章要将的栈和队列与之前所讲的数据结构和算法有三个不同之处:
而本章所要讲的栈和队列是作为程序员的工具来使用的。它们主要作为构思算法的辅助工具,而不是完全的用来数据存储。这些数据结构的生命周期要比那些数据库类型的结构要短,它们只有在程序操作执行期间才会被创建,通常用它们来执行某些特殊任务,当任务结束之后,它们就会被销毁。
这些数据结构的接口增加了访问的限制,从而使得访问其他数据项是不允许的。
例如:栈可以通过数组也可以通过链表来实现,优先级队列的内部实现可以用数组或者一种特殊的书-堆来实现。
同时栈也作为了其他复杂数据结构算法的便利工具。比如“二叉树”可以利用栈来遍历树的所有节点,“图”利用栈来辅助查找所有的顶点。
大部分的微处理器的运用也是基于栈的结构,当调用一个方法时,将方法的返回地址及参数压入栈中,当方法结束返回时,将其对应的数据从栈中移除。
在一些老式的便携式计算器也是基于栈的结构的,但是在栈中存放的不是算数表达式,而是其中间运算的结果。
4000
去做B,但在此时,大老板又给他分派了一项C任务要完成,于是他只能先完成C,在C做完时再去完成B,最后再解决其最初的工作A。那么这种先进后出的方式就是一种显示生活中的栈。
Stack类封装了表示最大容量的变量(即数组的大小),以及top变量用于表示栈顶的下标,不过要注意的是,因为当前的栈是利用数组来实现的,所以大小是固定不变的,如果利用之后所学的链表来存储栈的数据,那么栈的大小就是可变的了。
在类中,同时也封装了一些实现一些操作的方法:
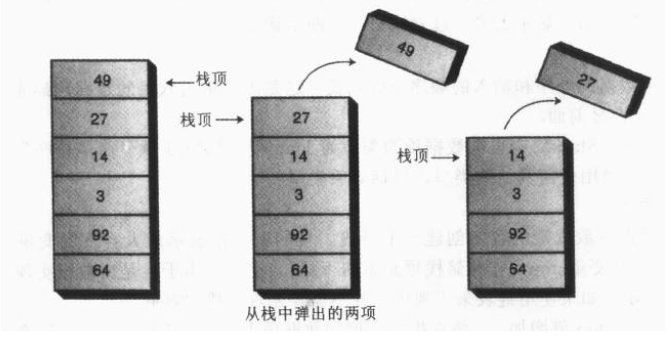
pop方法用于移除在栈顶的数据,并且返回其值,该方法现将top指向的下标位置的值返回,然后将top值减1是其指向新的栈顶。虽然此时该数据任然存在数组当中(直到有新的数据压入栈中覆盖掉该数据),但是由于top值得下移,这个数据是不可能在访问到的。
push方法用于在栈中插入一个新的数据,该方法先将top值加1,是其指向新栈顶的位置,然后在新栈顶中存放要插入的新数据。
peak方法用于读取栈顶的数据,但不移除,它将返回top所对应的数据值。
对于对栈出错处理交给用户来实现,用户可以通过判断栈是否为空isEmpty()来确定能否移除或者访问数据,通过判断是否已满isFull()来确定能否再插入数据。
下图表达了代码的整个过程:

文本不一定是Java当中代码,但它需要使用和Java一样的分隔符。分隔符可以是大括号“{”和“}”,中括号“[”和“]”,及小括号“(”和“)”。每个左分隔符都必须与其对应的右分隔符匹配,也就是说,左大括号“{”必须与右大括号“}”匹配,依此类推。同时,后出现的左分隔符一定比早出现的左分隔符先匹配到对应的右分隔符。下面是例子:
a{b[cd]e} //正确
df{c[(d)]} //正确
sww{[dsa)s} //错误
w[asd{r}g]] //错误
具体以a{b[cd]e}为例,其过程如下表:
当读取完数据之后,栈中内容也为空了,说明该文本串的左右分隔符完全匹配。这个方法的可行性在于,最后出现的左分隔符需要最先匹配,这正好符合栈的先进后出的原则。
程序员的工具
前面所讲的数组和后面要讲的其他数据结构(链表、树等)都是用来记录数据库中的数据,常常用于存储现实世界的对象和活动的数据。如学生档案和商务数据等等,这些数据结构都具有便于插入、删除和查找的优点。而本章所要讲的栈和队列是作为程序员的工具来使用的。它们主要作为构思算法的辅助工具,而不是完全的用来数据存储。这些数据结构的生命周期要比那些数据库类型的结构要短,它们只有在程序操作执行期间才会被创建,通常用它们来执行某些特殊任务,当任务结束之后,它们就会被销毁。
访问限制
在之前所讲的数组中,只要我们知道下标,我们就可以随时访问数组中的数据项,并且对其进行一系列的操作。但在本章的数据结构中,访问是受到限制的,在某个时刻,结构中的只有一个数据项能够被删除或者查看。这些数据结构的接口增加了访问的限制,从而使得访问其他数据项是不允许的。
更加抽象
本章所讲的栈和队列都是通过接口来定义的,这些接口表明了这些数据结构能够进行的操作,而对这些操作的实现机制用户是不可见的。这种方式增加了结构的抽象性。例如:栈可以通过数组也可以通过链表来实现,优先级队列的内部实现可以用数组或者一种特殊的书-堆来实现。
栈
栈只允许访问一个数据项:即最后插入的数据,只有在这个数据移除后才能访问倒数第二个数据,也就是先进后出的原则。这种机制在许多编程环境中都有用,比如在这节中要举的利用栈来检验括号是否匹配的例子,以及本章最后要讲的栈在解析算数表达式中起到的重要作用,比如解析3*(4+5)。同时栈也作为了其他复杂数据结构算法的便利工具。比如“二叉树”可以利用栈来遍历树的所有节点,“图”利用栈来辅助查找所有的顶点。
大部分的微处理器的运用也是基于栈的结构,当调用一个方法时,将方法的返回地址及参数压入栈中,当方法结束返回时,将其对应的数据从栈中移除。
在一些老式的便携式计算器也是基于栈的结构的,但是在栈中存放的不是算数表达式,而是其中间运算的结果。
栈的现实例子
某一个职员在进行某项A工作时,一个朋友让他帮忙完成B工作,于是他将A工作暂时放下4000
去做B,但在此时,大老板又给他分派了一项C任务要完成,于是他只能先完成C,在C做完时再去完成B,最后再解决其最初的工作A。那么这种先进后出的方式就是一种显示生活中的栈。
栈的Java代码
下面的代码利用Stack类来实现栈的接口:class Stack {
private int maxSize; //栈最多能存放多少数据
private int[] array;
private int top //表示当前在栈最顶端的数据下标
public Stack(int s) {
maxSize = s;
array = new int[s];
top = -1;
}
public int pop() {//移除数据
return array[top --];
}
public void push(int val) {//压入新的数据
array[++ top] = val;
}
public int peak() {//查看最顶端的数据
return array[top];
}
public boolean isEmpty() {
return (top == -1);
}
public boolean isFull() {
return (top == maxSize-1);
}
}//end StackStack类封装了表示最大容量的变量(即数组的大小),以及top变量用于表示栈顶的下标,不过要注意的是,因为当前的栈是利用数组来实现的,所以大小是固定不变的,如果利用之后所学的链表来存储栈的数据,那么栈的大小就是可变的了。
在类中,同时也封装了一些实现一些操作的方法:
pop方法用于移除在栈顶的数据,并且返回其值,该方法现将top指向的下标位置的值返回,然后将top值减1是其指向新的栈顶。虽然此时该数据任然存在数组当中(直到有新的数据压入栈中覆盖掉该数据),但是由于top值得下移,这个数据是不可能在访问到的。
push方法用于在栈中插入一个新的数据,该方法先将top值加1,是其指向新栈顶的位置,然后在新栈顶中存放要插入的新数据。
peak方法用于读取栈顶的数据,但不移除,它将返回top所对应的数据值。
对于对栈出错处理交给用户来实现,用户可以通过判断栈是否为空isEmpty()来确定能否移除或者访问数据,通过判断是否已满isFull()来确定能否再插入数据。
下图表达了代码的整个过程:
栈的实例1-单词逆序
让用户输入一个单词,再按下确定之后,输出单词字母的逆序。该实例可以用栈来实现,在输入单词时,将单词字母一个接一个压入到栈中,在输出时,将栈中的字母一个个弹出,实现代码如下:class MyStack {
private int maxSize;
private char[] array;
private int top;
//方法实现略,与之前类似
}
class Reverse {
private String input;
private String output;
public Reverse(String input) {
this.input = input;
}
public String doReverse() {
int stackSize = input.length();
MyStack stack = new MyStack(stackSize);
for(int i = 0; i < stackSize; i ++) {
stack.push(input.charAt(i));
}
output = "";
while(!stack.isEmpty()) {
output += stack.pop();
}
return output;
}//end doReverse
}//end Reverse
class ReverseApp {
public static void main(String[] args) {
String input, output;
while(true) {
System.out.print("please enter a String: ");
System.out.flush();
input = getString();
if("".equal(input))
break;
Reverse reverse = new Reverse(input);
output = reverse.doReverse();
System.out.println("Reversed" + output);
}//end while
}//end main
public static String getString() {//读取输入的字符串
InputStreamReader isr = new InputStreamReader(System.in);
BufferedReader br = new BufferedReader(isr);
String s = br.readLine();
return s;
}
}栈的实例2-分隔符匹配
栈通常用于解析某些类型的文本。一般情况下,文本串是用计算机语言写的代码行,那么解析这些文本串的即是解析器。文本不一定是Java当中代码,但它需要使用和Java一样的分隔符。分隔符可以是大括号“{”和“}”,中括号“[”和“]”,及小括号“(”和“)”。每个左分隔符都必须与其对应的右分隔符匹配,也就是说,左大括号“{”必须与右大括号“}”匹配,依此类推。同时,后出现的左分隔符一定比早出现的左分隔符先匹配到对应的右分隔符。下面是例子:
a{b[cd]e} //正确
df{c[(d)]} //正确
sww{[dsa)s} //错误
w[asd{r}g]] //错误
栈中的左分隔符
在文本串中自左向右不断的读取字符,当遇到左分隔符时就利用栈压入分隔符,当遇到右分隔符时,就从栈中弹出栈顶的左分隔符,将其与遇到的分隔符进行比较,若不匹配,则程序报错,或者一直没有分隔符与之匹配,则程序也会报错。没有分隔符匹配是指,在文本串的字符读取完之后,栈中仍有未弹出的左分隔符,或者,在读取到右分隔符时,栈中已为空。具体以a{b[cd]e}为例,其过程如下表:
| 读取的字符 | 栈中内容 |
|---|---|
| a | |
| { | { |
| b | { |
| [ | {[ |
| c | {[ |
| d | {[ |
| ] | { |
| e | { |
| } |
Java代码的实现
该程序要使用的栈的实现类,与上一个单词逆序的实例的相同,所以不再详写,一下只写了对匹配过程的封装:class MyStack {
//...
}
class TextChecker {
private String text;
public TextChecker(String t) {
text = t;
}
public boolean isMatch() {
MyStack stack = new MyStack(text.length());
for(int i = 0; i < text.length(); i ++) {
char c = text.charAt(i);
switch(c) {
case '{':
case '[':
case '(':
stack.push(c);
break;
case '}':
case ']':
case ')':
if(!stack.isEmpty()) {
char s = stack.pop();
if((s == '{' && c != '}') ||
(s == '[' && c != ']') ||
(s == '(' && c != ')'))//左右分隔符不匹配
System.out.println("Error: " + ch + " at " + i);
return false;
} else {//栈为空,但是仍有右分隔符未匹配
System.out.println("Error: " + ch + " at " + i);
return false;
}
break;
}//end switch
}//end for
if(!stack.isEmpty()) {//文本串读取完,但仍有左分隔符存在
System.out.println("Error: dismiss right delimiter");
return false;
}
return true;
}//end isMatch
}//end TextChecker
class TextApp {
public static void main(String[] args) {
String input;
while(true) {
System.out.print("Enter a text: ");
input = getString();
if("".equal(input))
break;
TextChecker checker = new TextChecker(input);
if(checker.isMatch())
System.out.println("输入文本分隔符匹配");
else
System.out.println("输入文本分隔符不匹配");
}
}
public static String getString() {
InputStreamReader isr = new InputStreamReader(System.in);
BufferedReader br = new BufferedReader(isr);
String s = br.readLine();
return s;
}
}栈是一种概念上的辅助工具
有上述两个实例,让我们知道了栈的方便性,当然也可以直接使用数组来进行上述两个实例的操作,但是那样的话,我们就必须记住数组的下标。栈在抽象概念上更便于使用,栈使用pop和push方法来限定性的访问数据,也增强了程序的易读性且不易出错。栈的效率
栈的插入和移除所要消耗的时间都为O(1),也就是说消耗的时间不与栈中的数据个数有关,无论是插入还是移除所需要的时间都是一个常数。
相关文章推荐
- Java数据结构与算法解析(三)——队列与背包
- Java数据结构和算法-栈和队列(4-解析算术表达式)
- Java数据结构与算法:队列
- Java数据结构与算法之Queue队列
- Java数据结构和算法--栈与队列
- Java数据结构和算法-栈和队列(3-优先级队列)
- 队列的创建 入队出队 Java数据结构与算法
- Java数据结构和算法(五)——队列
- JAVA数据结构和算法:第三章(栈和队列)
- java数据结构与算法 第4章 栈和队列
- Java数据结构与算法之优先级队列
- Java数据结构和算法(五)——队列
- 【Java数据结构学习笔记之三】Java数据结构与算法之队列(Queue)实现
- java数据结构和算法------队列
- java数据结构与算法之(Queue)队列设计与实现
- Java数据结构和算法--栈与队列
- 【Java】Java数据结构和算法(二)——栈和队列
- Java数据结构和算法——队列
- Java数据结构与算法 - 栈和队列
- java数据结构与算法-优先级队列