Hadoop 2.X 动态添加 datanode(详细图文)
2016-12-03 18:18
435 查看
准备工作:
我们的三个节点的集群(master,slave1,slave2)已经安装成功并且启动,具体安装方法可以参照之前的一篇教程Hadoop-2.6.4集群安装(详细图文)。
由于我们之前已经克隆出来一台,这次我们可以拿这一台来练习,先备份,搞崩了拿新的再搞!
当然,大家也可以自己重新安装一台,然后要安装配置好 jdk,最好是跟之前安装的版本一致,免得出什么幺蛾子。
既然是动态添加,就意味着机器不重启,其实在实际工作环境中,集群跑起来之后是不会那么容易就重启的。
比如,我们需要修改第四台机器的 hostname,配置静态IP,配置 ssh。这些可以参照之前的安装方法,我也就不再重复一遍了,相信大家这么长时间了,这些东西早就搞的很6了。
这里我把第四台机器的 hostname 配置成了 slave3。
声明:在工作环境中最好是不要用 root 用户来配置 hadoop,不然就是徒增麻烦。用我们之前的 hadoop 用户,但是我们是学习阶段,为了方便操作,就一路使用了 root 用户。
之后我们到 slave3 主机上,进到 /usr/hadoop/hadoop-2.6.4 目录,将 logs 目录中的文件全删掉:
我没有在逗你,”*.*“表示的任意格式的文件,不是表情^&^
这样就表示我们的 slave3 主机上的 datanode 启动成功了。
然后我们可以到 master 主机上,其实准确来说是到 namenode 上,因为之前我们被没有配置高可用,就是默认把 master 主机当作了 namenode。
所以,如果大家有不同的配置就要注意了,要到 namenode 所在的节点上 查看当前集群的情况:
然后大家会看到我也不想解释的一堆东西下来了…
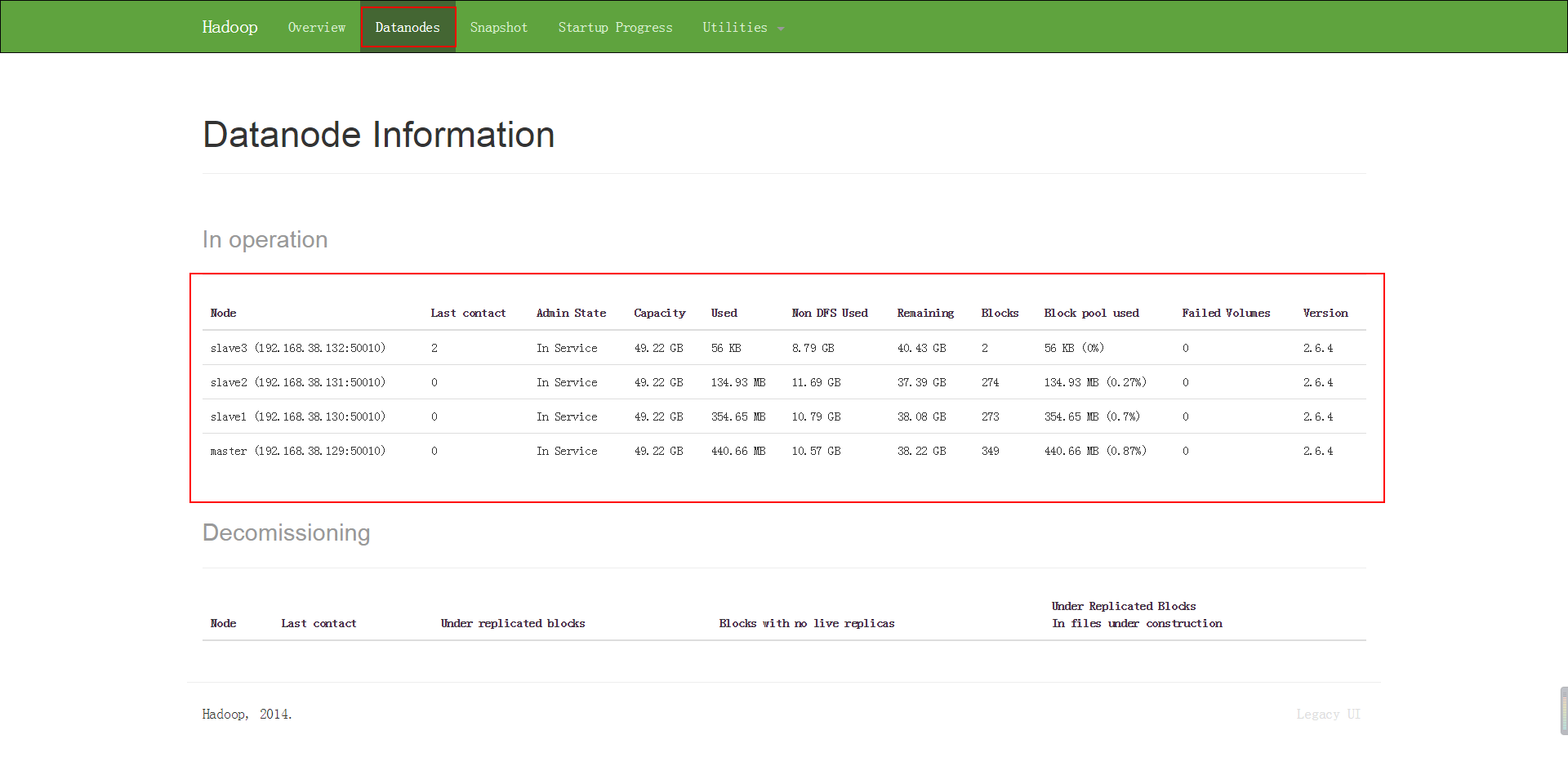
之后稍微等一下下,然后我们可以通过 webUI 来验证一下,我们现在的集群是不是真的有四个节点。
通过浏览器访问: http://master:50070 ,这里的 master 是 namenode(active) 的主机名。
首先在 slave3 主机上启动 nodemanager :
这个时候,我们再使用 jps 命令来查看 java 进程的话会发现:
是不是跟 slave2 和 slave1 节点的进程一样了。
这样一来,我们的 slave3 的节点就正式加入到 hadoop 集群了,并且也交由 yarn 来管理了。
到 ResourceManager 进程所在的节点执行:
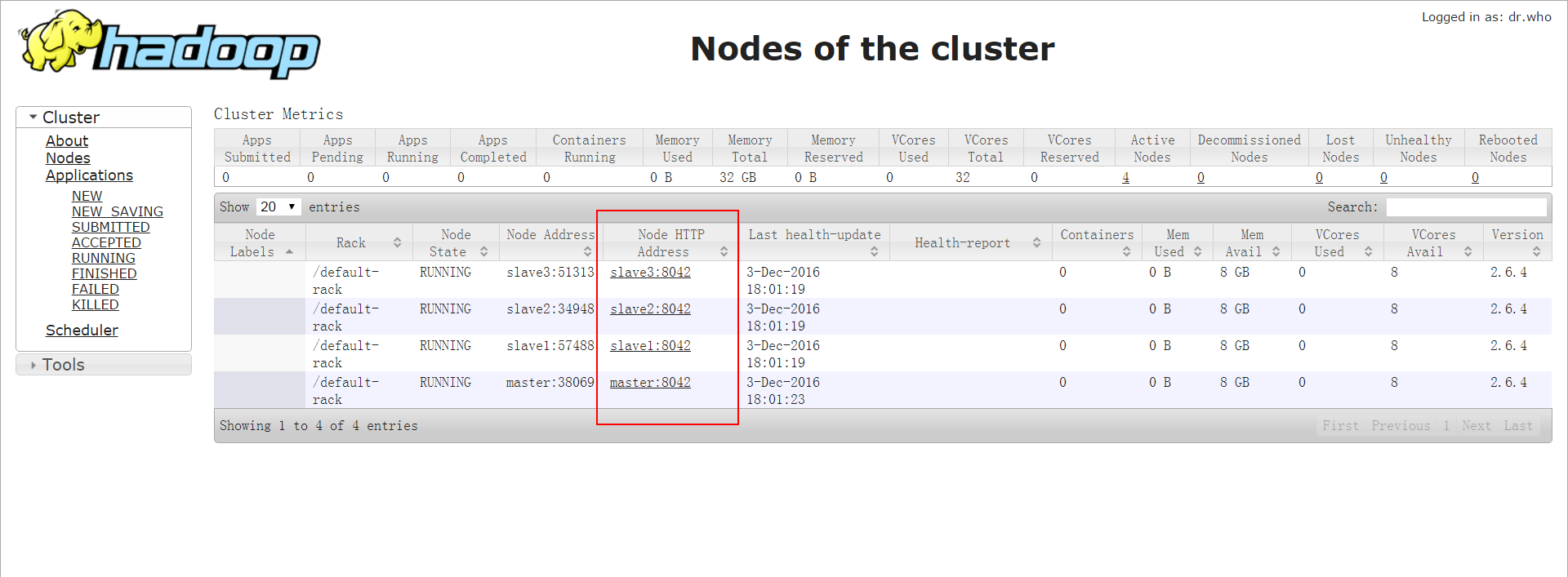
通过浏览器访问 http://master:8088 ,这里的 master 可以替换成你们集群中 resourceManager 所在的主机。来查看:
这个时候我们动态添加 datanoda 就完成了,可以等到下次重启集群的时候,把我们的 slave3 加入到 hadoop 的配置文件 slaves 中
(此处应有图片)
我们再启动集群的时候就会把 slave3 节点加进去了,不用我们再去手动启动一系列进程。
我们的三个节点的集群(master,slave1,slave2)已经安装成功并且启动,具体安装方法可以参照之前的一篇教程Hadoop-2.6.4集群安装(详细图文)。
由于我们之前已经克隆出来一台,这次我们可以拿这一台来练习,先备份,搞崩了拿新的再搞!
当然,大家也可以自己重新安装一台,然后要安装配置好 jdk,最好是跟之前安装的版本一致,免得出什么幺蛾子。
既然是动态添加,就意味着机器不重启,其实在实际工作环境中,集群跑起来之后是不会那么容易就重启的。
1 准备工作之后的一堆小工作
机器我们是准备好了,但是我们还需要配置好多东西才可以正式开始。比如,我们需要修改第四台机器的 hostname,配置静态IP,配置 ssh。这些可以参照之前的安装方法,我也就不再重复一遍了,相信大家这么长时间了,这些东西早就搞的很6了。
这里我把第四台机器的 hostname 配置成了 slave3。
声明:在工作环境中最好是不要用 root 用户来配置 hadoop,不然就是徒增麻烦。用我们之前的 hadoop 用户,但是我们是学习阶段,为了方便操作,就一路使用了 root 用户。
2 正式工作
在之前的准备工作之后的一堆小工作做完之后,我们就可以开始配置了。2.1 复制 hadoop-2.6.4
在 master 主机上,将 hadoop-2.6.4 整个目录复制到 slave3 上:[root@master hadoop-2.6.4]# hostname master [root@master hadoop-2.6.4]# pwd /usr/hadoop/hadoop-2.6.4 [root@master hadoop-2.6.4]# scp . root@slave3:/usr/hadoop/hadoop-2.6.4 ... [root@master hadoop-2.6.4]#
之后我们到 slave3 主机上,进到 /usr/hadoop/hadoop-2.6.4 目录,将 logs 目录中的文件全删掉:
[root@slave3 ~]# hostname slave3 [root@slave3 ~]# cd /usr/hadoop/hadoop-2.6.4/logs [root@slave3 logs]# rm -f *.* [root@slave3 logs]#
我没有在逗你,”*.*“表示的任意格式的文件,不是表情^&^
2.2 修改 slave3 的环境变量
其实这个我们可以偷个懒,直接拷贝 master 上的就可以了:[root@master hadoop-2.6.4]# hostname master [root@master hadoop-2.6.4]# scp /etc/profile root@slave3:/etc/ ~~ [root@master hadoop-2.6.4]# source /etc/profile [root@master hadoop-2.6.4]#
2.3 在 slave3 节点上启动 datanode
启动 datanode,但是这次用到的命令不一样:[root@slave3 sbin]# hostname slave3 [root@slave3 sbin]# pwd /usr/hadoop/hadoop-2.6.4/sbin [root@slave3 sbin]# hadoop-daemon.sh start datanode starting datanode, logging to /usr/hadoop/hadoop-2.6.4/logs/hadoop-root-datanode-slave3.out [root@slave3 sbin]# [root@slave3 sbin]# jps 33650 Jps 3096 DataNode [root@slave3 sbin]#
这样就表示我们的 slave3 主机上的 datanode 启动成功了。
然后我们可以到 master 主机上,其实准确来说是到 namenode 上,因为之前我们被没有配置高可用,就是默认把 master 主机当作了 namenode。
所以,如果大家有不同的配置就要注意了,要到 namenode 所在的节点上 查看当前集群的情况:
[root@master hadoop-2.6.4]# hostname master [root@master hadoop-2.6.4]# hdfs dfsadmin -report 16/12/03 17:49:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Configured Capacity: 211378749440 (196.86 GB) Present Capacity: 166457806848 (155.03 GB) DFS Remaining: 165482319872 (154.12 GB) DFS Used: 975486976 (930.30 MB) DFS Used%: 0.59% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Live datanodes (4): Name: 192.168.38.131:50010 (slave2) Hostname: slave2 Decommission Status : Normal Configured Capacity: 52844687360 (49.22 GB) DFS Use 4000 d: 141488128 (134.93 MB) Non DFS Used: 12553523200 (11.69 GB) DFS Remaining: 40149676032 (37.39 GB) DFS Used%: 0.27% DFS Remaining%: 75.98% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sat Dec 03 17:49:09 CST 2016 Name: 192.168.38.132:50010 (slave3) Hostname: slave3 Decommission Status : Normal Configured Capacity: 52844687360 (49.22 GB) DFS Used: 57344 (56 KB) Non DFS Used: 9435111424 (8.79 GB) DFS Remaining: 43409518592 (40.43 GB) DFS Used%: 0.00% DFS Remaining%: 82.15% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sat Dec 03 17:49:10 CST 2016 Name: 192.168.38.130:50010 (slave1) Hostname: slave1 Decommission Status : Normal Configured Capacity: 52844687360 (49.22 GB) DFS Used: 371875840 (354.65 MB) Non DFS Used: 11586138112 (10.79 GB) DFS Remaining: 40886673408 (38.08 GB) DFS Used%: 0.70% DFS Remaining%: 77.37% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sat Dec 03 17:49:09 CST 2016 Name: 192.168.38.129:50010 (master) Hostname: master Decommission Status : Normal Configured Capacity: 52844687360 (49.22 GB) DFS Used: 462065664 (440.66 MB) Non DFS Used: 11346169856 (10.57 GB) DFS Remaining: 41036451840 (38.22 GB) DFS Used%: 0.87% DFS Remaining%: 77.65% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sat Dec 03 17:49:09 CST 2016 [root@master hadoop-2.6.4]#
然后大家会看到我也不想解释的一堆东西下来了…
2.4 设置 hdfs 的负载均衡
同样的,这一列的命令也需要在 namenode 所在的节点执行,我的是 master。[root@master hadoop-2.6.4]# hostname master [root@master hadoop-2.6.4]# hdfs dfsadmin -setBalancerBandwidth 67108864 Balancer bandwidth is set to 67108864 [root@master hadoop-2.6.4]# start-balancer.sh -threshold 5 starting balancer, logging to /usr/hadoop/hadoop-2.6.4/logs/hadoop-root-balancer-master.out [root@master hadoop-2.6.4]#
之后稍微等一下下,然后我们可以通过 webUI 来验证一下,我们现在的集群是不是真的有四个节点。
通过浏览器访问: http://master:50070 ,这里的 master 是 namenode(active) 的主机名。
2.5 添加 slave3 到 yarn 集群
其实我都是糊弄的,当初也是没有分配 yarn 集群中个角色的…不过既然你现在来看这一篇教程,说明你对hadoop2.X是有一定了解的,我就只是点一下吧!首先在 slave3 主机上启动 nodemanager :
[root@slave3 sbin]# hostname slave3 [root@slave3 sbin]# pwd /usr/hadoop/hadoop-2.6.4/sbin [root@slave3 sbin]# yarn-daemon.sh start nodemanager starting nodemanager, logging to /usr/hadoop/hadoop-2.6.4/logs/yarn-root-nodemanager-slave3.out [root@slave3 sbin]#
这个时候,我们再使用 jps 命令来查看 java 进程的话会发现:
[root@slave3 sbin]# jps 33488 Jps 3096 DataNode 3195 NodeManager [root@slave3 sbin]#
是不是跟 slave2 和 slave1 节点的进程一样了。
这样一来,我们的 slave3 的节点就正式加入到 hadoop 集群了,并且也交由 yarn 来管理了。
到 ResourceManager 进程所在的节点执行:
[root@master hadoop-2.6.4]# yarn node -list 16/12/03 18:10:43 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.38.129:8032 16/12/03 18:10:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Total Nodes:4 Node-Id Node-State Node-Http-Address Number-of-Running-Containers slave3:51313 RUNNING slave3:8042 0 slave2:34948 RUNNING slave2:8042 0 slave1:57488 RUNNING slave1:8042 0 master:38069 RUNNING master:8042 0 [root@master hadoop-2.6.4]#
通过浏览器访问 http://master:8088 ,这里的 master 可以替换成你们集群中 resourceManager 所在的主机。来查看:
这个时候我们动态添加 datanoda 就完成了,可以等到下次重启集群的时候,把我们的 slave3 加入到 hadoop 的配置文件 slaves 中
(此处应有图片)
我们再启动集群的时候就会把 slave3 节点加进去了,不用我们再去手动启动一系列进程。

相关文章推荐
- Hadoop 2.X 动态添加 datanode(详细图文)
- Hadoop动态添加删除datanode及tasktracker
- Hadoop2.2.0动态添加,删除datanode,tasktracker
- Hadoop动态添加Datanode节点
- Hadoop动态添加删除datanode及tasktracker
- hadoop 动态添加节点datanode及tasktracker
- cui-----Hadoop动态添加删除datanode及tasktracker【需要整理】
- Hadoop动态添加/删除节点(datanode和tacktracker)
- Hadoop动态添加删除datanode及tasktracker
- hadoop集群中动态添加新的DataNode节点
- Hadoop集群动态添加datanode节点步骤
- hadoop1.1.2集群动态添加datanode节点
- hadoop 中添加和删除 datanode和tasktracker(一)
- hadoop 中添加和删除 datanode和tasktracker(二)
- 【转 】Hadoop datanode添加与删除
- Hadoop添加节点datanode(生产环境)
- Hadoop 添加删除数据节点(datanode)
- Hadoop动态加入/删除节点(datanode和tacktracker)
- Hadoop之添加新的datanode
- Hadoop 添加删除DataNode 和 TaskTracker