《编程珠玑》习题练习In Python——第二章 啊哈!算法
2016-12-02 19:39
483 查看

开篇三个问题的思路
问题1:给定最多40亿随机排列的32位整数的文件,找出一个不存在该文件中的32位整数。在内存足够和仅有几百字节的内存的情况下如何解决该问题?
内存足够:使用第一章的位图法,时间复杂度O(n)。
内存不够:那么可以使用一种特殊的二分法。首先我们知道32位整数(非负整数)的取值范围是[0,2^32),一共存在40亿多个不同的整数。只要给定的数的个数小于范围可以取的数的个数,说明该范围中一定有一个数是没有给定的。等分取值区间为两个区间[0,2^31)和[2^31,2^32)。分别统计40亿个数中落在两个区间的次数。对次数小于范围可取数的区间(一定存在)再次等分。一次进行知道找到该数。这个方法时间复杂度O(nlogn)。
答案给出的方法中提到每次搜索将对应区间数复制到新的文件,这样每一轮搜索数的数量会减少一半,时间复杂度会变为O(n)
问题2:
数组的循环位移。有三种方法。
第一种:“杂耍法”
对于数组a,如果向左位移3。那么a[0]处移动之后应该是a[3]。取出a[0]元素,将a[3]移动到a[0],紧接着可以将a[6]移动到a[3],到达末尾时取数组开头对应元素继续。当所有元素都移动了一遍之后,循环位移就成功了。
第二种:“递归法”
对于向左位移3的数组a。将a[:3]和a[3:]的开头3个元素交换。对a[3:]做同样的递归操作。直到开头3个元素移动到最末尾。
第三种:“转置法”
对于向左位移3的数组a。分别翻转数组的两个部分,之后翻转整个数组。数组的两个部分就被交换了。
问题3:
给一个英文词典,找出所有的变位词。例如“pots”,”stop”和“tops”是变位词。
将一个单词的字母排序,相同排序的单词是变位词。
习题1
给定一个输入单词,找出在字典中的所有变位词。仅给定单词和字典时,如何解决?如果有一些时间和空间对字典进行预处理,又会如何?1、生成字典
第一个问题是如何得到字典。我考虑生成一个假的字典。随机生成的方法本质是只能生成随机数的,如何将数转换为字符串呢?
如果把仅有小写字母的单词看做是26进制的数,a-z分别表示0-25。那么随机生成一个数,就可以通过进制变换(也就是多次整除和取余)来获得单词了。
代码如下:
def create_dic(wordCount=10**6):
minLetterCount = 5
reqLetterCount = math.ceil(math.log(wordCount*2,26))
letterCount = max(minLetterCount,reqLetterCount)
numDict = rand_uint(letterCount,wordCount)
wordDict = []
while(len(numDict)>0):
n = numDict.pop()
word = []
while(n != 0):
c = chr(n % 26 + ord('a'))
n = n//26
word.append(c)
wordDict.append(''.join(word))
return wordDict首先根据输入参数需要的单词个数,计算生成的单词最多多个少字母。rand_uint()为根据最大字母数和单词个数生成不重复随机数序列的函数。
2、仅给定输入单词和字典
将变位词的字母排序,得到的新序列应该是相同的。根据这个原理,只需要将输入单词和字典中单词全部排序,选出排序序列相同的即可。代码如下:
def test_1_1(): given_word = "given" dic = create_dic() given_sig = sort_word(given_word) ans = [] for word in dic: sig = sort_word(word) if(sig == given_sig): ans.append(word) print(ans[:10],len(ans))
3、允许对词典预处理
方法也是一样,首先对词典中单词进行一次排序。将单词存储到字典中,使用排序后的序列作为键。代码如下:
def test_1_2():
given_word = "given"
words = create_dic()
given_sig = sort_word(given_word)
dic = {}
while(len(words)>0):
word = words.pop()
sig = sort_word(word)
if dic.get(sig) == None:
dic[sig] = [word]
else:
dic[sig].append(word)
ans = dic[given_sig]
print(ans[:10],len(ans))输出
['ivgne', 'gvnie', 'egnvi', 'gevin', 'vegni', 'vngei', 'iegnv', 'gneiv', 'iengv', 'ginev'] 13
对于100万个单词,数组占用8Mb内存,字典占用12Mb内存。内存使用可以接受。
习题2
给定包含43亿个32位整数的顺序文件,如何找出至少出现两次的整数?计算器计算2^32=4,294,967,296。给定数的个数大于32位整数取值范围,说明一定有重复。思路同这一章的问题1。代码如下:
def test_2():
rng = 10**5
num,rand = create_data(rng)# 返回生成的数组,和重复的那个数
l = 0
r = rng
while(r-l>1):
m = (r+l)//2
if count_num(l,m,num)>m-l: # 统计范围左闭右开
r = m
continue
elif count_num(m,r,num)>r-m:
l = m
continue
else:
raise Exception("input error")
print(l,rand)输出的两个数相同,说明程序实现成功。
习题3.1
“杂耍法”计算数组的循环位移。杂耍法思路很简单,但是其中有一个不容易发现的陷阱。举两个例子说明。
1、数组长度7,左移3个单位。
移动的顺序应该是
0 <- 3 <- 6 <- 2 <- 5 <- 1 <- 4 <- 0
这是一般的预想情况。
2、数组长度9,左移3个单位。
使用一样的思路,移动顺序应该是
0 <- 3 <- 6 <- 0
移动三个元素之后移动就终止了。数组长度正好是移动距离的倍数时,需要移动多轮。
代码如下:
def move_juggle(word,step): l = len(word) si = 0 # 一轮的起始位置 start index c = 0 # 移动次数 count while(1): tmp = word[si] i = si # 一轮中,数组空位下标 index while(1): ni = (i+step)%l # 待移动元素下标 next index if ni == si: word[i] = tmp c+=1 break word[i] = word[ni] i = ni c+=1 if c < l: # 当移动次数和数组长度相同时终止 si+=1 continue else: break return "".join(word)
习题3.2
递归法计算数组的循环位移。递归函数:
def move_word(word,strt,step): l = len(word)-strt if l > 2*step: tmp = word[strt:strt+step] word[strt:strt+step]=word[strt+step:strt+step*2] word[strt + step:strt + step * 2] = tmp return move_word(word,strt+step,step) else: tmp = word[strt:strt+step] left = word[strt+step:] word[strt:strt+len(left)] = left word[strt+len(left):strt+len(left)+step] = tmp return word
习题4.1
实现求逆算法的数组循环位移。比较简单,代码如下:
def move_reverse(word,step): def reverse(word): start = 0 end = len(word)-1 while(start<end): tmp = word[start] word[start] = word[end] word[end] = tmp start += 1 end -= 1 return word ans = reverse(reverse(word[:step])+reverse(word[step:])) return "".join(ans)
习题4.2
比较三种求循环位移的方法的速度。在固定数组距离,变换交换距离的情况下。作者给出的结果如下:
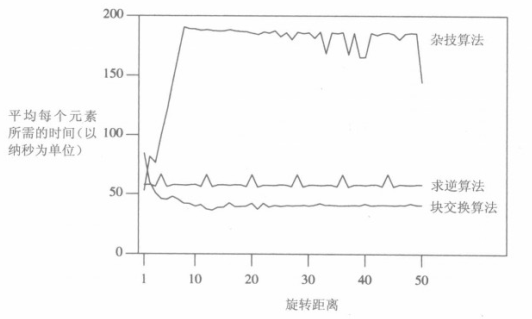
“杂技算法”在交换距离增加之后,所需时间会急剧增加。这是因为该算法的高速缓存性能差,高速缓存大小很小,在交换距离增加的时候,“杂技算法”每次只从高速缓存读取一个元素,导致高速缓存需要读取的次数大大增加。
然而,在Python实现的算法中,没有出现这个情况。杂技算法一直是最快的。这应该与Python底层实现有关系。
习题5
(aTbTcT)T = cba习题6
电话上的号码簿搜索程序。标准电话按键如下:
问题是,如果给定一个号码簿,求拨号时遇到重名的概率?另外,如何实现以名字的按键编码为参数,并返回所有可能的匹配名字的函数。
这题思路和变位词一样。对于寻找具有共性的元素的问题,我们变化元素表示的方式,使不同的但具有共性的元素拥有同样的内容。这里可以将人名转换为对应的号码字符串,或者可以直接表示为整数。将这个号码作为键把人名存储在字典中。代码如下:
def test_6():
def cal_num(word):
num = []
for c in word:
asc = ord(c)-ord('a')
n = asc//3+2
if n>9:
n = 0
num.append(str(n))
return ''.join(num)
nameCount = 10**5
name_list = create_dic(nameCount)
dic = {}
while(len(name_list)>0):
name = name_list.pop()
num = cal_num(name)
if dic.get(num) == None:
dic[num] = [name]
else:
dic[num].append(name)
# 重复率
print((nameCount-len(dic.keys()))/nameCount)
# 查询
given_name = "vince"
ans = dic.get(cal_num(given_name))
print(ans)输出结果为:
0.50736 ['xhncf']
习题8
给定一个n元实数集合,一个实数t和一个整数k,如何快速确定n是否存在一个k元子集,其元素之和不超过t?方案1:
对整个数组排序,取最小k个数求和。时间复杂度O(nlogn)。
方案2:
顺序读取所有数,保存所遇到的数中最小的k个。可以使用堆保存k个数,整体时间复杂度为O(nlogk)。整体来说方案2更好,不仅速度更快,而且所需要的内存也更少。首先写一个大顶堆:
# 大顶堆 def swap(a, i, j): temp = a[i] a[i] = a[j] a[j] = temp def insert_full_heap(a,n):# 新元素替换根节点,向下移动 def sort_heap(a,ind): l = ind*2+1 r = ind*2+2 if l>=len(a) or (a[ind]>=a[l] and (r>=len(a) or a[ind]>=a[r])):# 左右节点均走不通 return elif r>=len(a) or a[l] >a[r]:# 与左节点交换的情况 swap(a, l, ind) sort_heap(a, l) else:# 剩下只能和右节点交换 swap(a, r, ind) sort_heap(a, r) if n>a[0]: return a[0] = n sort_heap(a,0) def insert_empty_heap(a,n):# 新元素放在末尾,往上移动 def up(a,ind): if ind==0: return p = (ind-1)//2 if a[p] < a[ind]: swap(a,p,ind) up(a,p) ind = len(a) a.append(n) up(a,ind)
整个程序:
num = rand_uint(2,100) k = 5 t = 200 s = [] for n in num: if len(s) < k: insert_empty_heap(s,n) else: insert_full_heap(s,n) print(sum(s)<t,s)
输出结果为:
True [20, 17, 6, 5, 7]

相关文章推荐
- 《编程珠玑》习题练习In Python——第三章 数据决定程序结构
- 《编程珠玑》习题练习In Python——第一章 开篇
- 《编程珠玑》 第二章 算法 习题
- learning python in the hard way习题6~10的附加题练习
- learning python in the hard way习题1~5的附加题练习
- learning python in the hard way习题11~15的附加题练习
- 算法导论第二版习题试解-第二章练习2.2
- 编程珠玑_第二章_啊哈 算法
- 编程珠玑第二章读书笔记 第二章 Aha!算法 (手摇法)
- 编程珠玑第二章习题2
- 《Python核心编程》第二版第36页第二章练习 -Python核心编程答案-自己做的-
- CDays-3 习题二 (字典及文件读取练习)及相关内容解析。Python 基础教程
- 《编程珠玑》-第二章:寻找兄弟单词+电话簿功能 算法研究
- {算法竞赛入门经典}第二章 习题解答及例题小结
- 算法练习:字符串原地逆序(in-place reverse)(只用基本数据结构)
- 《编程珠玑》--第二章 啊哈!算法
- 算法竞赛-入门经典 第二章上机练习
- 《编程珠玑》第二章 “杂技算法” 和 “翻转算法” C语言实现
- 《Python核心编程》第二版第36页第二章练习 续三 -Python核心编程答案-自己做的-
- 《编程珠玑》读书笔记2------------第二章习题及个人答案