Redis核心知识之—— 时延问题分析及应对、性能问题和解决方法
2016-11-30 19:27
633 查看
参考网址:
Redis时延问题分析及应对:http://www.cnblogs.com/me115/p/5032177.htmlRedis常见的性能问题和解决方法:http://www.searchdatabase.com.cn/showcontent_63439.htm
Redis主从配置详细过程:http://sofar.blog.51cto.com/353572/861276
读后感:
1、在架构设计中,有“分流”一招,说的是将处理快的请求和处理慢的请求分离来开,否则,慢的影响到了快的,让快的也快不起来;这在redis的设计中体现的非常明显,redis的纯内存操作,epoll非阻塞IO事件处理,这些快的放在一个线程中搞定,而持久化,AOF重写、Master-slave同步数据这些耗时的操作就单开一个进程来处理,不要慢的影响到快的;
2、控制每个redis实例的最大内存量,一般建议不超过20G,可根据自己服务器的性能来确定(内存越大,持久化的时间越长,复制页表的时间越长,对事件循环的阻塞就延长)
新浪微博给的建议是不超过20G,而我们虚机上的测试,要想保证应用毛刺不明显,可能得在10G以下;
3、master-slave:在主结点上开持久化,主结点不对外提供查询,查询由slave结点提供,从结点不提供持久化;这样,所有的fork耗时的操作都在主结点上,而查询请求由slave结点提供;
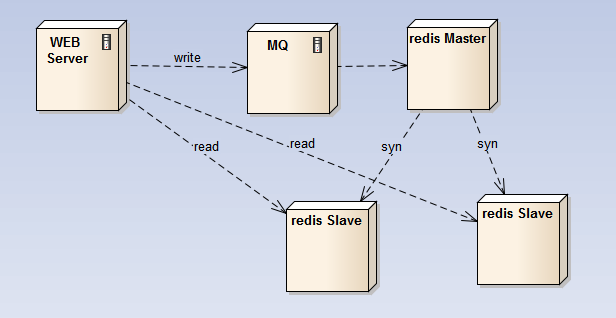
简单的实现方案是主不具有可替代性,坏了之后,redis集群对外就只能提供读,而无法更新;待主结点启动后,再继续更新操作;对于之前的更新操作,可以用MQ缓存起来,等主结点起来之后消化掉故障期间的写请求;
4、子进程持久化时,子进程的write和主进程的fsync冲突造成阻塞
在开启了AOF持久化的结点上,当子进程执行AOF重写或者RDB持久化时,出现了Redis查询卡顿甚至长时间阻塞的问题, 此时, Redis无法提供任何读写操作;
原因分析:
Redis 服务设置了 appendfsync everysec, 主进程每秒钟便会调用 fsync(), 要求内核将数据”确实”写到存储硬件里. 但由于服务器正在进行大量IO操作, 导致主进程 fsync()/操作被阻塞, 最终导致 Redis 主进程阻塞.
当执行AOF重写时会有大量IO,这在某些Linux配置下会造成主进程fsync阻塞;
解决方案:
设置 no-appendfsync-on-rewrite yes, 在子进程执行AOF重写时, 主进程不调用fsync()操作;注意, 即使进程不调用 fsync(), 系统内核也会根据自己的算法在适当的时机将数据写到硬盘(Linux 默认最长不超过 30 秒).
这个设置带来的问题是当出现故障时,最长可能丢失超过30秒的数据,而不再是1秒。
解决方案:
将硬盘设置的足够大,将AOF重写的阈值调高,保证高峰期间不会触发重写操作;在闲时使用crontab 调用AOF重写命令;
Redis常见的性能问题和解决方法
1.Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。总结:
1.Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
2.如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
3.为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
4.尽量避免在压力较大的主库上增加从库
5.为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系为:Master<--Slave1<--Slave2<--Slave3.......,这样的结构也方便解决单点故障问题,实现Slave对Master的替换,也即,如果Master挂了,可以立马启用Slave1做Master,其他不变。

相关文章推荐
- Redis核心知识之—— 时延问题分析及应对、性能问题和解决方法【★★★★★】
- 单线程你别阻塞,Redis时延问题分析及应对
- Redis 常见的性能问题和解决方法
- Redis 常见的性能问题和解决方法
- Redis 常见的性能问题和解决方法
- Redis常见的性能问题和解决方法
- Redis 常见的性能问题和解决方法
- Redis时延问题分析及应对
- Redis 常见的性能问题和解决方法
- Redis时延问题分析及应对
- Redis时延问题分析及应对
- 单线程你别阻塞,Redis时延问题分析及应对
- Redis时延问题分析及应对
- Redis 常见的性能问题和解决方法
- 单线程你别阻塞,Redis时延问题分析及应对
- Redis 常见的性能问题和解决方法
- Redis 常见的性能问题和解决方法
- Redis时延问题分析及应对
- Redis 常见的性能问题和解决方法
- 【案例】关于weblogic性能问题的分析和解决方法