elasticsearch(二) 基本概念和使用
2016-11-26 15:55
561 查看
reference book:
《Elasticsearch: The Definitive Guide》
或者使用sense建索引
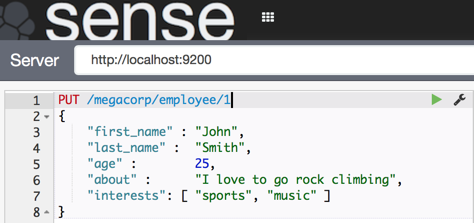
termianl建索引逼格太高,后面我都是用sense啦!
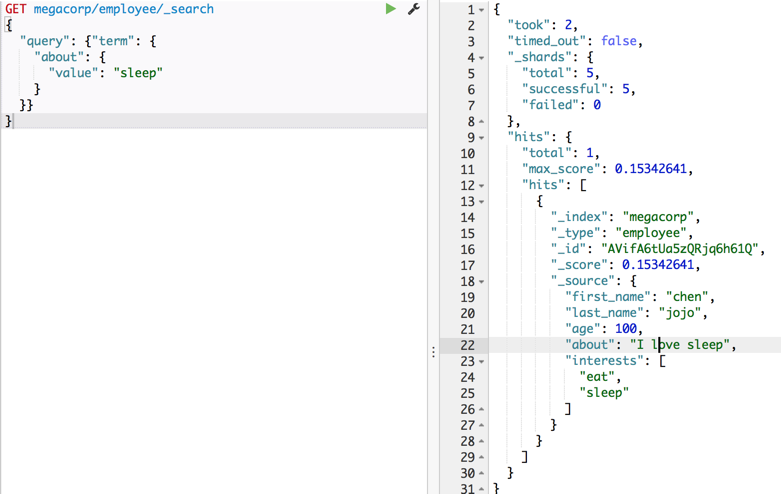
type: employee
document:
field: frst_name,last_name,age,about,interests
Note: type(employee)后面跟个1是什么鬼?这是doc的ID,我们建索引的时候就指定了ID为1,也可以让系统自动生产id。
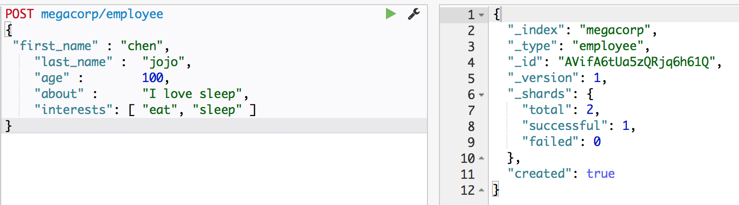
PUT-> POST
_id AVifA6tUa5zQRjq6h61Q 就是es自动生成的id
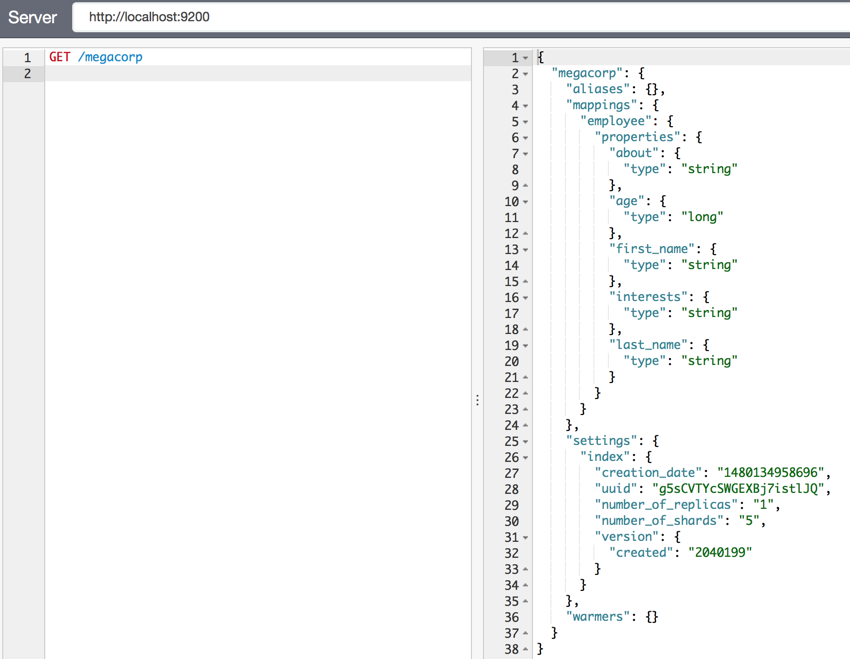
查看特定索引可以看到索引的所有信息和配置,包括分片(number_of_shards)数为5,备胎数(number_of_replicas)为1,后面填坑。
Note:关键是mappings!elastic给每一个field都自动确定了一个类型(type),这里的type不是table,而是数据类型,后面讲到模版的时候,就可以自定义类型啦!基本类型,让es自动确定已经挺方便哒!

炸出2个索引(-。-;
Note: 5 1 2 分别为 number_of_shards number_of_replicas 文档数目
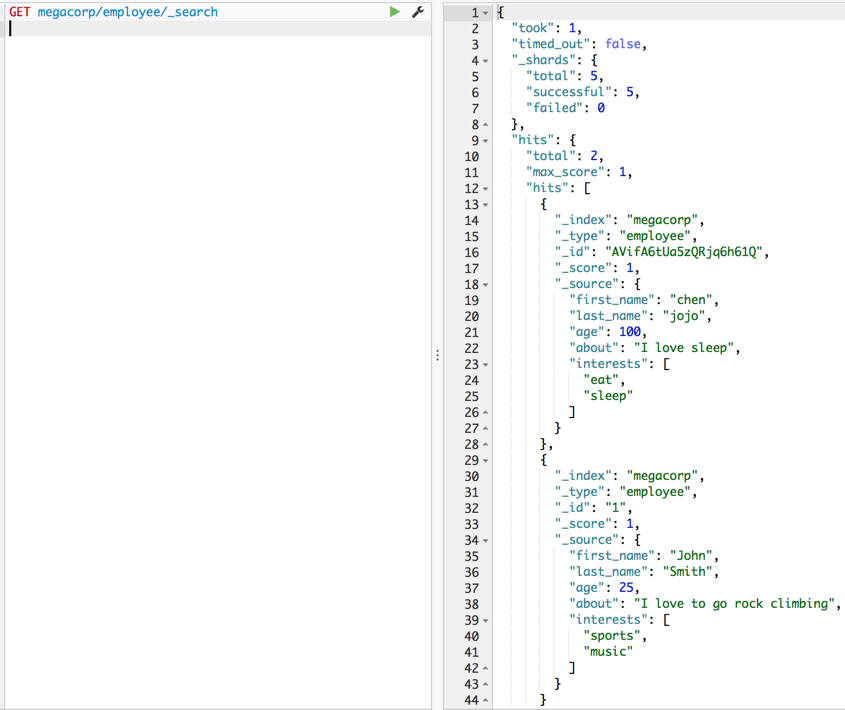
信息详解:
- took: 耗时1ms
- time_out: 木有超时
- _shards.total: 总共有5个分片
- _shards.successful: 5个分片搜索成功
- _shards.failed: 0个分片搜索失败
- hits:命中的doc
- hits._index,hits.type,hits._id 不累述
- hits.score:doc和查询条件的相关性,后面填坑
- _source:建索引的原始文档

我们直接指定要获取的doc ID,好吧,我也觉得不算搜索(~_~;)
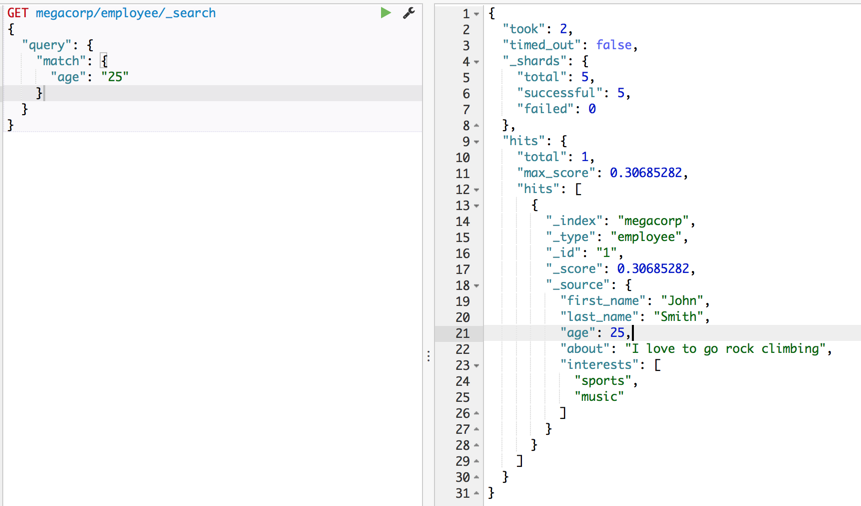
query: 查询体
math: 查询方式为 math
age: 查询年龄field
25: 查询值
类似于:
Note:
- _score是无意义的
- ”25“ 改成 25 也是阔以的,es容忍能力很强大!
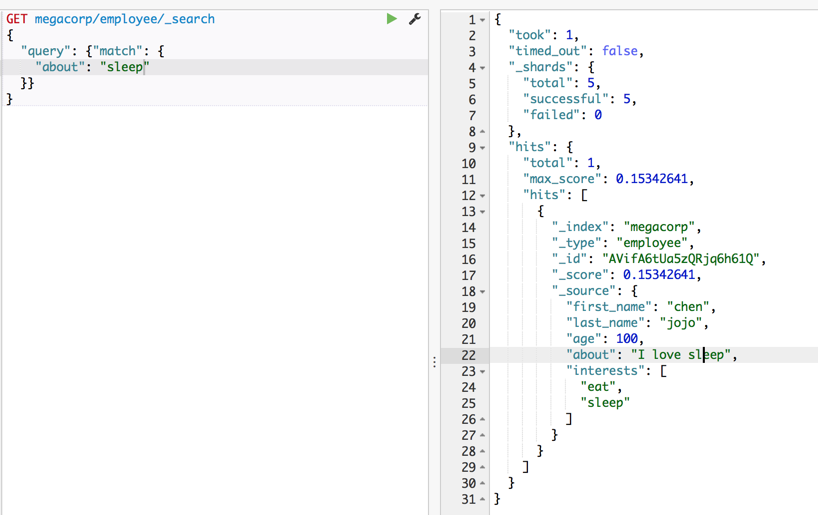
索引处理

查询 “slee” (少个p),是不会有结果的哦!因为es不是直接去匹配字符串,它会es先对field分词,“i love sleep” 这句话会被 “ ”(停用词),分拆成i,love,sleep三个单词,然后建倒排索引
,所以用slee查不到的!,扯远了,以后填坑,自定义分词
查询处理
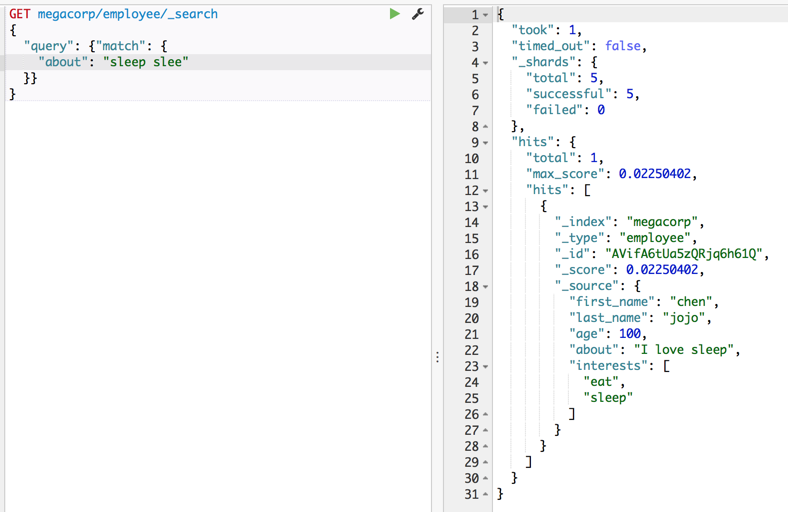
咋这个能命中呢?真相是,es会对查询也进行分词会把“sleep slee” 分词,拆成”sleep”,”slee”,然后去搜索,只要命中一个就算命中!也就是或的关系,但是命中大查询词越多得分越高,这也就是为什么相对于上一条查询,得分从0.15降低到0.02的原因,前者命中所有查询词,后者只命中1/2的查询词。
score机制
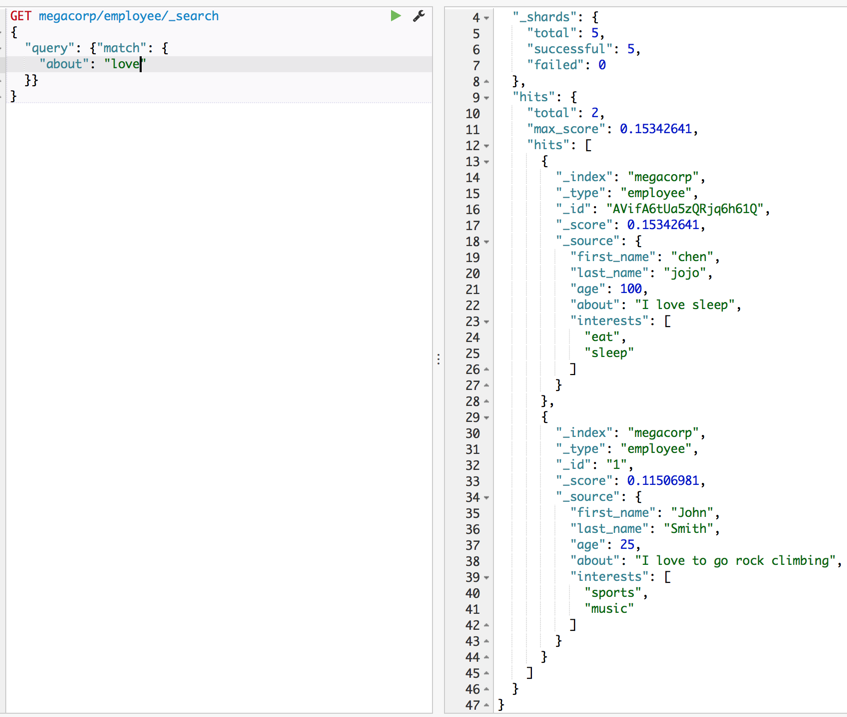
同样命中love的两个文档,为啥”I love sleep”得分大于”I love to go rock climbing”,很显然,后者更长,相关性更低.
Note:命中的文档会按score从高到低排序
只支持单个取值过滤

支持多个取值,默认命中任何一个查询词都会返回
看起来和match差不大是吧,其实match是典型的query,term是典型的filter.
filter
A filter asks a yes|no question of every document and is used for fields that contain exact values:
Is the created date in the range 2013 - 2014?
Does the status field contain the term published?
Is the lat_lon field within 10km of a specified point?(e.g.距离人民广场炸鸡店一百米内的所有用户)
query
A query is similar to a filter, but also asks the question: How well does this document match?
A typical use for a query is to find documents
Best matching the words full text search
Containing the word run, but maybe also matching runs, running, jog, or sprint(词干,同义词)
Containing the words quick, brown, and fox—the closer together they are, the more relevant the document
Tagged with lucene, search, or java—the more tags, the more relevant the document(见索引处理)
《Elasticsearch: The Definitive Guide》
索引
refIndex (noun)
As explained previously, an index is like a database in a traditional relational database. It is the place to store related documents. The plural of index is indices or indexes.type
类似mysql的tabledocument
类似mysql的一行field
类似mysql的一列Index (verb)
To index a document is to store a document in an index (noun) so that it can be retrieved and queried. It is much like the INSERT keyword in SQL except that, if the document already exists, the new document would replace the old建索引
使用terminal建一条索引(index a document)curl -XPUT 'localhost:9200/megacorp/employee/1?pretty' -d'
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}'或者使用sense建索引
termianl建索引逼格太高,后面我都是用sense啦!
概念对应
Index: megacorptype: employee
document:
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}'field: frst_name,last_name,age,about,interests
Note: type(employee)后面跟个1是什么鬼?这是doc的ID,我们建索引的时候就指定了ID为1,也可以让系统自动生产id。
PUT-> POST
_id AVifA6tUa5zQRjq6h61Q 就是es自动生成的id
查看索引
查看特定索引可以看到索引的所有信息和配置,包括分片(number_of_shards)数为5,备胎数(number_of_replicas)为1,后面填坑。
Note:关键是mappings!elastic给每一个field都自动确定了一个类型(type),这里的type不是table,而是数据类型,后面讲到模版的时候,就可以自定义类型啦!基本类型,让es自动确定已经挺方便哒!
查看所有索引
炸出2个索引(-。-;
Note: 5 1 2 分别为 number_of_shards number_of_replicas 文档数目
查看文档
信息详解:
- took: 耗时1ms
- time_out: 木有超时
- _shards.total: 总共有5个分片
- _shards.successful: 5个分片搜索成功
- _shards.failed: 0个分片搜索失败
- hits:命中的doc
- hits._index,hits.type,hits._id 不累述
- hits.score:doc和查询条件的相关性,后面填坑
- _source:建索引的原始文档
搜索文档
我们直接指定要获取的doc ID,好吧,我也觉得不算搜索(~_~;)
简单搜索
match
query: 查询体
math: 查询方式为 math
age: 查询年龄field
25: 查询值
类似于:
SELECT * FROM employee WHERE age = 25
Note:
- _score是无意义的
- ”25“ 改成 25 也是阔以的,es容忍能力很强大!
索引处理
查询 “slee” (少个p),是不会有结果的哦!因为es不是直接去匹配字符串,它会es先对field分词,“i love sleep” 这句话会被 “ ”(停用词),分拆成i,love,sleep三个单词,然后建倒排索引
,所以用slee查不到的!,扯远了,以后填坑,自定义分词
查询处理
咋这个能命中呢?真相是,es会对查询也进行分词会把“sleep slee” 分词,拆成”sleep”,”slee”,然后去搜索,只要命中一个就算命中!也就是或的关系,但是命中大查询词越多得分越高,这也就是为什么相对于上一条查询,得分从0.15降低到0.02的原因,前者命中所有查询词,后者只命中1/2的查询词。
score机制
同样命中love的两个文档,为啥”I love sleep”得分大于”I love to go rock climbing”,很显然,后者更长,相关性更低.
Note:命中的文档会按score从高到低排序
term
只支持单个取值过滤
terms
支持多个取值,默认命中任何一个查询词都会返回
看起来和match差不大是吧,其实match是典型的query,term是典型的filter.
书中总结
Queries and Filters
Although we refer to the query DSL, in reality there are two DSLs: the query DSL and the filter DSL. Query clauses and filter clauses are similar in nature, but have slightly different purposes.filter
A filter asks a yes|no question of every document and is used for fields that contain exact values:
Is the created date in the range 2013 - 2014?
Does the status field contain the term published?
Is the lat_lon field within 10km of a specified point?(e.g.距离人民广场炸鸡店一百米内的所有用户)
query
A query is similar to a filter, but also asks the question: How well does this document match?
A typical use for a query is to find documents
Best matching the words full text search
Containing the word run, but maybe also matching runs, running, jog, or sprint(词干,同义词)
Containing the words quick, brown, and fox—the closer together they are, the more relevant the document
Tagged with lucene, search, or java—the more tags, the more relevant the document(见索引处理)
When to Use Which
As a general rule, use query clauses for full-text search or for any condition that should affect the relevance score, and use filter clauses for everything else.
相关文章推荐
- (2.1.2)Java线程:多线程的基本概念和使用
- elasticsearch基本操作之--使用java操作elasticsearch
- 第十二章 异常处理 概念和基本使用
- 分布式搜索elasticsearch 基本概念
- ajax的基本概念及使用
- Git的基本概念与使用
- elasticsearch基本概念
- Java装箱和拆箱的基本概念及使用
- 数组的基本概念,定义及使用方法
- grunt入门讲解1:grunt的基本概念和使用
- Elasticsearch 5.x 基本概念
- CALayer 的基本概念和基本使用
- IOS学习笔记(十)之UIImageView图片视图的基本概念和使用方法
- VxWorks6.6 pcPentium BSP 使用说明(一):基本概念 分类: vxWorks 2014-06-28 08:28 565人阅读 评论(0) 收藏
- Elasticsearch java api 基本使用之增、删、改、查
- elasticsearch基本概念介绍
- lucene.net的一些基本使用方法和概念
- UICollectionView的基本概念与使用
- java多线程的基本概念与线程的使用方法
- Elasticsearch学习总结一 基本用法及概念