利用Azure Redis Cache构建百万量级缓存读写
2016-11-23 13:30
489 查看
Redis是一个非常流行的基于内存的,低延迟,高吞吐量的key/value数据存储,被广泛用于数据库缓存,session的管理,热数据高速访问,甚至作为数据库方式提高应用程序可扩展性,吞吐量,和实施处理性能。
Azure的Redis Cache是一个PAAS服务,开箱即用,完全兼容开源的Redis 3.0服务, 并且提供了更多增强的服务提供给企业级应用使用,比如SSL支持,主从服务器,Redis集群,虚拟网络支持,数据持久化备份等等,本文介绍如何使用这些高级特性并构建百万量级的缓存读写访问。
在使用Azure Redis之前,我们需要理解不同版本的Redis服务的差异,根据你的业务选择合适的服务层级,目前Azure Redis有三个不同的版本:
基本版本:这个版本是单个节点,只适用于开发测试,没有SLA,内存大小从250M到53GB。
标准版本:主从复制架构,99.9%的SLA保障,内存大小同样是250M到53GB大小,最大C6级别的缓存可以达到15万每秒的RPS(每秒请求数),可用带宽250MB/s。
高级版本:主从复制架构,支持集群,分区分片,支持数据持久化,最为重要的是支持虚拟网络,也就意味着可以将Redis部署到你的虚拟网络中去就像访问本地服务一样,内存大小单个节点6GB大53GB,最大支持10个节点,因此最大内存值可以达到530GB。
在大部分的生产环境中,Redis都是作为本地缓存提供低延迟高吞吐量的缓存服务,所以在生产环境的部署中,我建议大家使用高级版本将Azure Redis部署到虚拟网络中获得最佳性能和体验,本示例中也是以高级版本作为演示。
基本安装配置
首先我们需要创建一个虚拟网络,测试的虚拟机和Azure Redis cache都会被部署在这个虚拟机网络,虚拟机对于Redis的访问就和本地访问一样了,在"网络"中创建虚拟网络,输入相关参数,进行创建:
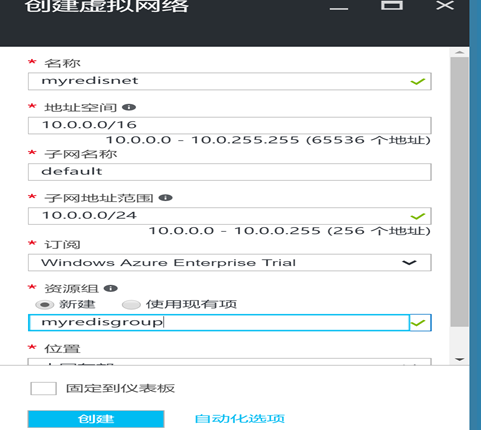
接下来我们创建一个Redis Cache, Redis的高级版本只能使用资源管理器模式创建,所以我们可以用Powershell或者新Portal来创建,打开新portal,选择Redis缓存:
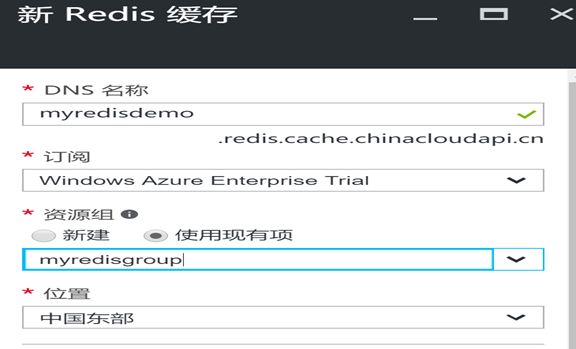
输入Redis的名称,资源组(和虚拟网络的资源组一样),位置也和虚拟网络一致:
为便于性能测试,在Redis大小上,选择P4高级最高级别并确定:
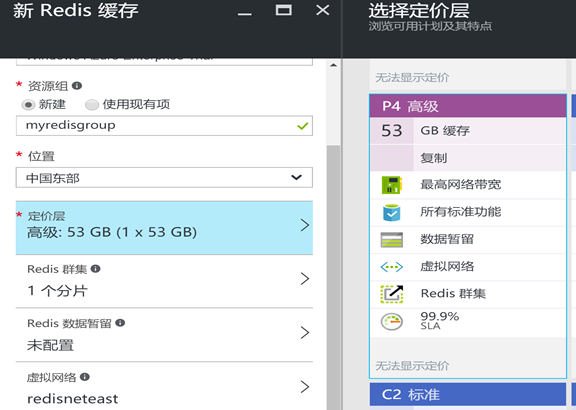
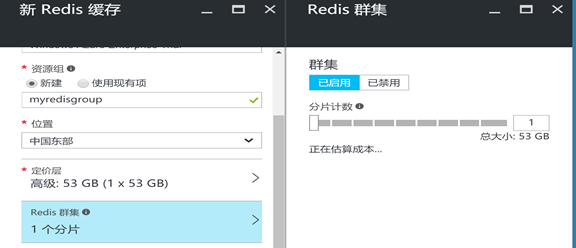
在群集配置上,选择"已启用"启用集群功能,分片暂时保持不变为1个分片:
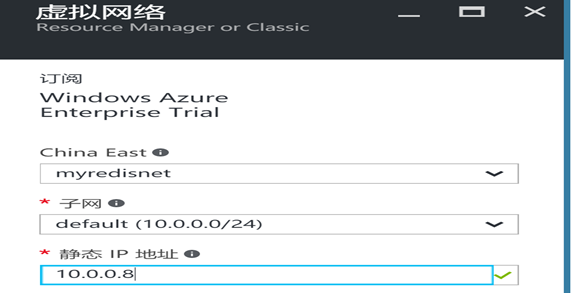
虚拟网络,选择之前创建的虚拟网络,并点击确定,点击确定开始部署:
为便于测试,创建一台CentOS 7.2虚拟机,用户安装Redis客户端及Benchmark工具,资源组和Redis资源组保持一致,虚拟网络和Redis一致,然后进行创建,如果创建成功,在资源组myredisgroup下看起来如下:

请注意:将 Azure Redis 缓存部署到 ARM VNet 时,缓存必须位于专用子网中,其中只能包含 Azure Redis 缓存实例,而不能包含其他任何资源。如果尝试将 Azure Redis 缓存部署到包含其他资源的 ARM VNet 子网,部署将会失败;所以如果你需要将虚拟机部署到Redis所在的ARM vnet,需要新建一个子网,比如App;经典模式的vnet无此限制。
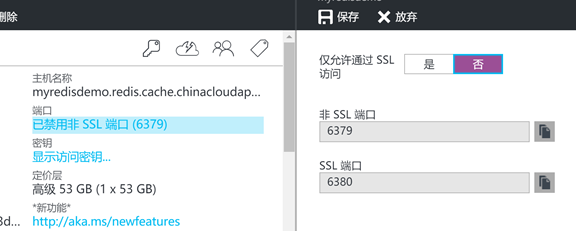
在Azure Redis上,默认只循序SSL访问,但对于放在内网的缓存来说,没有必要,并且支持SSL的客户端比较少;登录新portal,选择Redis,端口,点击"已禁用SSL端口",配置为否,允许非SSL访问,点击保存:
性能测试
我们用标准的redis-benchmark来实际压测一下Azure Redis cache的处理性能,首先我们需要配置一下测试虚拟机,并安装Redis测试相关工具。Redis测试的相关工具,比如redis-benchmark等都在Redis的源码包中。
下载最新的Redis并解压缩,最新的稳定版本是3.2.5:
$ wget http://download.redis.io/releases/redis-3.2.5.tar.gz
$ tar xzf redis-3.2.5.tar.gz
$ cd redis-3.2.5
在正式编译之前,需要安装下gcc,make等工具:
$ sudo yum install gcc make
编译Redis,目前由于Redis编译文件的问题,需要先编译依赖包deps,然后再进行Redis编译:
$ cd deps
$ make hiredis lua jemalloc linenoise jemalloc geohash-int
$ cd ..
$ make
Deps的编译结果和命令如下:
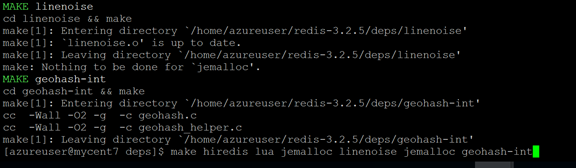
单个节点,即一个分片性能测试:
在该测试中,执行100万次SET/GET操作,并发客户数50,每个对象大小1024,用来测试Redis的处理性能,当然Redis测试性能也和测试的客户端有关系,当前测试的客户端是一台DS12(4核心)。
src/redis-benchmark -h 10.0.0.8 -a bAukX3LpNeJaOdDd6tfhzjifkXm4LS8gmASapxkgU04= -t SET -n 1000000 -d 1024 -P 30 -c 50
写操作,即SET操作,可以达到SET: 120496.45 requests per second

src/redis-benchmark -h 10.0.0.8 -a bAukX3LpNeJaOdDd6tfhzjifkXm4LS8gmASapxkgU04= -t GET -n 1000000 -d 1024 -P 30 -c 50
读操作,即GET操作,可以达到GET: 284414.09 requests per second

使用集群,增加分片数目,测试客户端不需要做任何修改,首先增加节点数到5个节点:

在该测试中,执行300万次SET/GET操作,并发客户数500,每个对象大小1024,用来测试Redis的处理性能,当然Redis测试性能也和测试的客户端有关系,当前测试的客户端是一台DS14(16核心)
使用同样的测试程序进行测试,可以看到Redis Cluster节点增加到5个的时候:
SET操作:SET: 861573.75 requests per second

GET操作:GET: 2038043.50 requests per second

使用同样的测试程序进行测试,可以看到Redis Cluster节点增加到10个的时候
SET的操作可以达到:929368.06 requests per second

GET的操作可以达到:3118503.00 requests per second

做一个简单的汇总可以看到,在将Azure Redis部署在虚拟网络中,并且客户端同一个虚拟网络中进行测试的时候,Redis的处理性能随着节点的增加呈现线程增长,可以达到百万量级的缓存访问,并且目前客户处理每天千万量级的用户请求而处理非常平稳:
注意:
1. 测试的性能和你的客户端处理能力以及参数有关,比如即使使用了10个节点,但你的客户端处理能力有限,测试出来的性能会受限于客户端
2. 每次测试的结果并不一定完全一致,和处理能力,网络等会有关系
高可用测试
之前我们讲到,其实每个Redis的标准和高级版本中,有主从复制,那么主从复制对我们的程序有什么影响?我们如何看到主从复制昵?我们用redis-cli工具和redis-benchmark来进行测试看看。
登陆到之前的测试Linux虚拟机,运行azure-cli命令,输入info命令,可以看到服务器端的Redis相关信息:
src/redis-cli -h 10.0.0.8 -a bAukX3LpNeJaOdDd6tfhzjifkXm4LS8gmASapxkgU04=

我们输入cluster nodes命令,可以看到,单节点的Redis有一个master和一个slave机器来保证高可用性,即使一个发生问题,另外一个也会实时接管,客户无感知:

我们在新的azure portal上进行节点的scale out,即增加到5个节点,
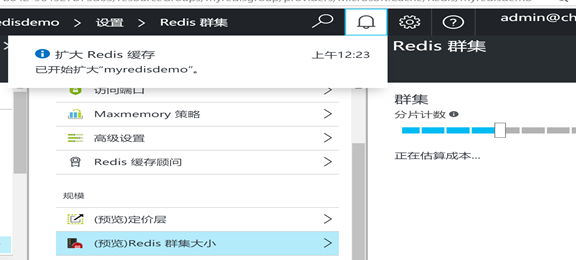
在服务器端进行增加扩展的时候,继续运行客户端测试,你会看到由于使用了主从机制,客户端并无感知,服务不会中断,可以继续进行测试:

Azure Redis的数据持久化
需要新建一个Redis集群,或者硬件损坏,或者需要回滚数据的时候,都需要用到Redis的备份持久化功能。
标准Redis提供两种数据持久化的方式将Redis内存中的数据持久化到磁盘上,一种是RDB方式,一种是AOF方式. RDB是Redis默认的方式,提供时间点的快照,是一种二进制压缩文件;AOF方式实际上会是记录Redis服务器上所有的操作,当你需要恢复的时候,利用AOF文件重新执行即可。
可以看到RDB更加高效,性能更好,速度更快,但缺点是粒度较大,时间点内可能会有数据损失;AOF方式粒度更小,就如数据库的操作日志一样,由于是文本文件,即使出现问题也比较容易修复,但缺点是效率较低,文本文件较大,比RDB方式较慢。
Azure Redis cache目前只支持RDB方式的持久化,配置相对来讲比较简单:
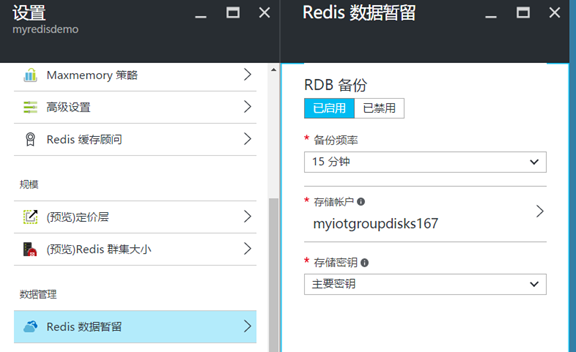
备份频率最低为15分钟,建议使用高级存储账号进行存储,需要注意的是,Azure上RDB存储的格式是page blob格式。
Azure Redis的导入导出
Azure Redis的导入/导出功能目前还是预览阶段,需要了解的是,目前,Redis在界面上可以接受的导入导入格式只能是RDB格式,还有一个很重要的问题,在Azure上,目前导入,导出的格式只支持RDB格式,并且只能是Page Blob格式。
使用RDB并且使用page blob导入的限制在于:
如果你是从你的数据中心的Redis集群到处的RDB文件,其大小必须是512字节的整数倍。
如果不是整数倍,即使你用azcopy按照page blob上传过去,也无法导入,会报错,需要修改文件
另外,如果你的Redis是较高版本,比如Redis 3.2,导入大Azure Redis的时候,因为目前Azure上的Redis 是3.0版本,也会报错,Azure Redis文件中的版本是REDIS0006:
解决办法?
目前在实际的案例中,有两种解决办法比较高效:
虽然AOF通过界面不支持,但通过redis-cli,使用AOF文件方式可以进行文件的导入导出:
首先,从本地Redis cache 生成AOF文件,使用Redis-cli连接本地Redis执行BGREWRITEAOF命令,生成AOF文件如backup.aof
然后,使用redis-cli连接Azure的redis,执行:
redis-cli -h 10.0.0.8 –a ACCESSKEY -p 6379 --pipe < backup.aof
第三方工具,最好是CentOS7+作为客户端:
https://github.com/vipshop/redis-migrate-tool
该工具非常强大,可以从各种源,比如RDB导入到Azure Redis,需要编译安装。
从以上的测试可以看出,Azure Reids是一个高可用的,低延迟,并且可分区的高性能Reids存储,可以支持百万量级的缓存读写,并且维护配置非常简单。
Azure的Redis Cache是一个PAAS服务,开箱即用,完全兼容开源的Redis 3.0服务, 并且提供了更多增强的服务提供给企业级应用使用,比如SSL支持,主从服务器,Redis集群,虚拟网络支持,数据持久化备份等等,本文介绍如何使用这些高级特性并构建百万量级的缓存读写访问。
在使用Azure Redis之前,我们需要理解不同版本的Redis服务的差异,根据你的业务选择合适的服务层级,目前Azure Redis有三个不同的版本:
基本版本:这个版本是单个节点,只适用于开发测试,没有SLA,内存大小从250M到53GB。
标准版本:主从复制架构,99.9%的SLA保障,内存大小同样是250M到53GB大小,最大C6级别的缓存可以达到15万每秒的RPS(每秒请求数),可用带宽250MB/s。
高级版本:主从复制架构,支持集群,分区分片,支持数据持久化,最为重要的是支持虚拟网络,也就意味着可以将Redis部署到你的虚拟网络中去就像访问本地服务一样,内存大小单个节点6GB大53GB,最大支持10个节点,因此最大内存值可以达到530GB。
在大部分的生产环境中,Redis都是作为本地缓存提供低延迟高吞吐量的缓存服务,所以在生产环境的部署中,我建议大家使用高级版本将Azure Redis部署到虚拟网络中获得最佳性能和体验,本示例中也是以高级版本作为演示。
基本安装配置
首先我们需要创建一个虚拟网络,测试的虚拟机和Azure Redis cache都会被部署在这个虚拟机网络,虚拟机对于Redis的访问就和本地访问一样了,在"网络"中创建虚拟网络,输入相关参数,进行创建:接下来我们创建一个Redis Cache, Redis的高级版本只能使用资源管理器模式创建,所以我们可以用Powershell或者新Portal来创建,打开新portal,选择Redis缓存:
输入Redis的名称,资源组(和虚拟网络的资源组一样),位置也和虚拟网络一致:
为便于性能测试,在Redis大小上,选择P4高级最高级别并确定:
在群集配置上,选择"已启用"启用集群功能,分片暂时保持不变为1个分片:
虚拟网络,选择之前创建的虚拟网络,并点击确定,点击确定开始部署:
为便于测试,创建一台CentOS 7.2虚拟机,用户安装Redis客户端及Benchmark工具,资源组和Redis资源组保持一致,虚拟网络和Redis一致,然后进行创建,如果创建成功,在资源组myredisgroup下看起来如下:
请注意:将 Azure Redis 缓存部署到 ARM VNet 时,缓存必须位于专用子网中,其中只能包含 Azure Redis 缓存实例,而不能包含其他任何资源。如果尝试将 Azure Redis 缓存部署到包含其他资源的 ARM VNet 子网,部署将会失败;所以如果你需要将虚拟机部署到Redis所在的ARM vnet,需要新建一个子网,比如App;经典模式的vnet无此限制。
在Azure Redis上,默认只循序SSL访问,但对于放在内网的缓存来说,没有必要,并且支持SSL的客户端比较少;登录新portal,选择Redis,端口,点击"已禁用SSL端口",配置为否,允许非SSL访问,点击保存:
性能测试
我们用标准的redis-benchmark来实际压测一下Azure Redis cache的处理性能,首先我们需要配置一下测试虚拟机,并安装Redis测试相关工具。Redis测试的相关工具,比如redis-benchmark等都在Redis的源码包中。下载最新的Redis并解压缩,最新的稳定版本是3.2.5:
$ wget http://download.redis.io/releases/redis-3.2.5.tar.gz
$ tar xzf redis-3.2.5.tar.gz
$ cd redis-3.2.5
在正式编译之前,需要安装下gcc,make等工具:
$ sudo yum install gcc make
编译Redis,目前由于Redis编译文件的问题,需要先编译依赖包deps,然后再进行Redis编译:
$ cd deps
$ make hiredis lua jemalloc linenoise jemalloc geohash-int
$ cd ..
$ make
Deps的编译结果和命令如下:
单个节点,即一个分片性能测试:
在该测试中,执行100万次SET/GET操作,并发客户数50,每个对象大小1024,用来测试Redis的处理性能,当然Redis测试性能也和测试的客户端有关系,当前测试的客户端是一台DS12(4核心)。
src/redis-benchmark -h 10.0.0.8 -a bAukX3LpNeJaOdDd6tfhzjifkXm4LS8gmASapxkgU04= -t SET -n 1000000 -d 1024 -P 30 -c 50
写操作,即SET操作,可以达到SET: 120496.45 requests per second
src/redis-benchmark -h 10.0.0.8 -a bAukX3LpNeJaOdDd6tfhzjifkXm4LS8gmASapxkgU04= -t GET -n 1000000 -d 1024 -P 30 -c 50
读操作,即GET操作,可以达到GET: 284414.09 requests per second
使用集群,增加分片数目,测试客户端不需要做任何修改,首先增加节点数到5个节点:
在该测试中,执行300万次SET/GET操作,并发客户数500,每个对象大小1024,用来测试Redis的处理性能,当然Redis测试性能也和测试的客户端有关系,当前测试的客户端是一台DS14(16核心)
使用同样的测试程序进行测试,可以看到Redis Cluster节点增加到5个的时候:
SET操作:SET: 861573.75 requests per second
GET操作:GET: 2038043.50 requests per second
使用同样的测试程序进行测试,可以看到Redis Cluster节点增加到10个的时候
SET的操作可以达到:929368.06 requests per second
GET的操作可以达到:3118503.00 requests per second
做一个简单的汇总可以看到,在将Azure Redis部署在虚拟网络中,并且客户端同一个虚拟网络中进行测试的时候,Redis的处理性能随着节点的增加呈现线程增长,可以达到百万量级的缓存访问,并且目前客户处理每天千万量级的用户请求而处理非常平稳:
| Redis节点数目 及内存 | SET操作(requests/second) | GET操作(requests/second) | 测试客户端 |
| 1 node(53GB) | 120496 | 284414 | DS12 |
| 5 nodes(5X53GB) | 861573 | 2038043 | DS14 |
| 10 nodes(10X53GB) | 929368 | 3118503 | DS14 |
1. 测试的性能和你的客户端处理能力以及参数有关,比如即使使用了10个节点,但你的客户端处理能力有限,测试出来的性能会受限于客户端
2. 每次测试的结果并不一定完全一致,和处理能力,网络等会有关系
高可用测试
之前我们讲到,其实每个Redis的标准和高级版本中,有主从复制,那么主从复制对我们的程序有什么影响?我们如何看到主从复制昵?我们用redis-cli工具和redis-benchmark来进行测试看看。登陆到之前的测试Linux虚拟机,运行azure-cli命令,输入info命令,可以看到服务器端的Redis相关信息:
src/redis-cli -h 10.0.0.8 -a bAukX3LpNeJaOdDd6tfhzjifkXm4LS8gmASapxkgU04=
我们输入cluster nodes命令,可以看到,单节点的Redis有一个master和一个slave机器来保证高可用性,即使一个发生问题,另外一个也会实时接管,客户无感知:
我们在新的azure portal上进行节点的scale out,即增加到5个节点,
在服务器端进行增加扩展的时候,继续运行客户端测试,你会看到由于使用了主从机制,客户端并无感知,服务不会中断,可以继续进行测试:
Azure Redis的数据持久化
需要新建一个Redis集群,或者硬件损坏,或者需要回滚数据的时候,都需要用到Redis的备份持久化功能。标准Redis提供两种数据持久化的方式将Redis内存中的数据持久化到磁盘上,一种是RDB方式,一种是AOF方式. RDB是Redis默认的方式,提供时间点的快照,是一种二进制压缩文件;AOF方式实际上会是记录Redis服务器上所有的操作,当你需要恢复的时候,利用AOF文件重新执行即可。
可以看到RDB更加高效,性能更好,速度更快,但缺点是粒度较大,时间点内可能会有数据损失;AOF方式粒度更小,就如数据库的操作日志一样,由于是文本文件,即使出现问题也比较容易修复,但缺点是效率较低,文本文件较大,比RDB方式较慢。
Azure Redis cache目前只支持RDB方式的持久化,配置相对来讲比较简单:
备份频率最低为15分钟,建议使用高级存储账号进行存储,需要注意的是,Azure上RDB存储的格式是page blob格式。
Azure Redis的导入导出
Azure Redis的导入/导出功能目前还是预览阶段,需要了解的是,目前,Redis在界面上可以接受的导入导入格式只能是RDB格式,还有一个很重要的问题,在Azure上,目前导入,导出的格式只支持RDB格式,并且只能是Page Blob格式。使用RDB并且使用page blob导入的限制在于:
如果你是从你的数据中心的Redis集群到处的RDB文件,其大小必须是512字节的整数倍。
如果不是整数倍,即使你用azcopy按照page blob上传过去,也无法导入,会报错,需要修改文件
另外,如果你的Redis是较高版本,比如Redis 3.2,导入大Azure Redis的时候,因为目前Azure上的Redis 是3.0版本,也会报错,Azure Redis文件中的版本是REDIS0006:
解决办法?
目前在实际的案例中,有两种解决办法比较高效:
虽然AOF通过界面不支持,但通过redis-cli,使用AOF文件方式可以进行文件的导入导出:
首先,从本地Redis cache 生成AOF文件,使用Redis-cli连接本地Redis执行BGREWRITEAOF命令,生成AOF文件如backup.aof
然后,使用redis-cli连接Azure的redis,执行:
redis-cli -h 10.0.0.8 –a ACCESSKEY -p 6379 --pipe < backup.aof
第三方工具,最好是CentOS7+作为客户端:
https://github.com/vipshop/redis-migrate-tool
该工具非常强大,可以从各种源,比如RDB导入到Azure Redis,需要编译安装。
从以上的测试可以看出,Azure Reids是一个高可用的,低延迟,并且可分区的高性能Reids存储,可以支持百万量级的缓存读写,并且维护配置非常简单。

相关文章推荐
- Azure Redis Cache作为ASP.NET 缓存输出提供程序
- 利用Cache缓存数据提高大数据量访问性能
- 在ASP.NET 中实现单用户登录(利用Cache, 将用户信息保存在服务器缓存中)[转]
- 【构建Android缓存模块】(二)Memory Cache & File Cache
- Solr 利用缓存(Cache)的时刻
- 【构建Android缓存模块】(二)Memory Cache & File Cache
- 在ASP.NET 中实现单点登录(利用Cache, 将用户信息保存在服务器缓存中)
- nginx利用proxy_cache来缓存文件
- Windows Azure Marketplace入门教学-利用TabLeau Public构建可视化DataMarket应用
- Windows Azure Marketplace入门教学-利用TabLeau Public构建可视化DataMarket应用
- Redis缓存服务搭建及实现数据读写
- 如何利用Linux构建免费的缓存DNS服务器
- Windows Azure Marketplace入门教学-利用TabLeau Public构建可视化DataMarket应用
- Windows Azure Marketplace入门教学-利用TabLeau Public构建可视化DataMarket应用
- 关于使用ASP.NET4.0 OutputCacheProvider做缓存注意的地方(缓存放入redis)
- 如何利用Linux构建免费的缓存DNS服务器
- Windows Azure Marketplace入门教学-利用TabLeau Public构建可视化DataMarket应用
- 有效利用 Domino/Notes 缓存(Cache)机制
- Python Web 框架 Django缓存层 - django-redis-cache
- Redis缓存服务搭建及实现数据读写