[深度学习论文笔记][Video Classification] Delving Deeper into Convolutional Networks for Learning Video Repre
2016-11-17 16:01
1176 查看
Ballas, Nicolas, et al. “Delving Deeper into Convolutional Networks for Learning Video Representations.” arXiv preprint arXiv:1511.06432 (2015). (Citaions: 14).
1 Motivation
Previous works on Recurrent CNNs has tended to focus on high-level features extracted from the 2D CNN top-layers. High-level features contain highly discriminative informa-
tion, they tend to have a low-spatial resolution. Thus, we argue that current RCN architectures are not well suited for capturing fine motion information. Instead, they are more
likely focus on global appearance changes.
Low-level features, on the other hand, preserve a higher spatial resolution from which we can model finer motion patterns. However, applying an RNN directly on intermediate
convolutional maps, inevitably results in a drastic number of parameters characterizing the input-to-hidden transformation due to the convolutional maps size. On the other hand,
convolutional maps preserve the frame spatial topology. To leverage these, we extend the GRU model and replace the fc RNN linear product operation with a convolution. Our GRU extension therefore encodes the locality and temporal smoothness prior of videos directly
in the model structure. Thus, all neurons in the CNN are recurrent.
2 Architecture
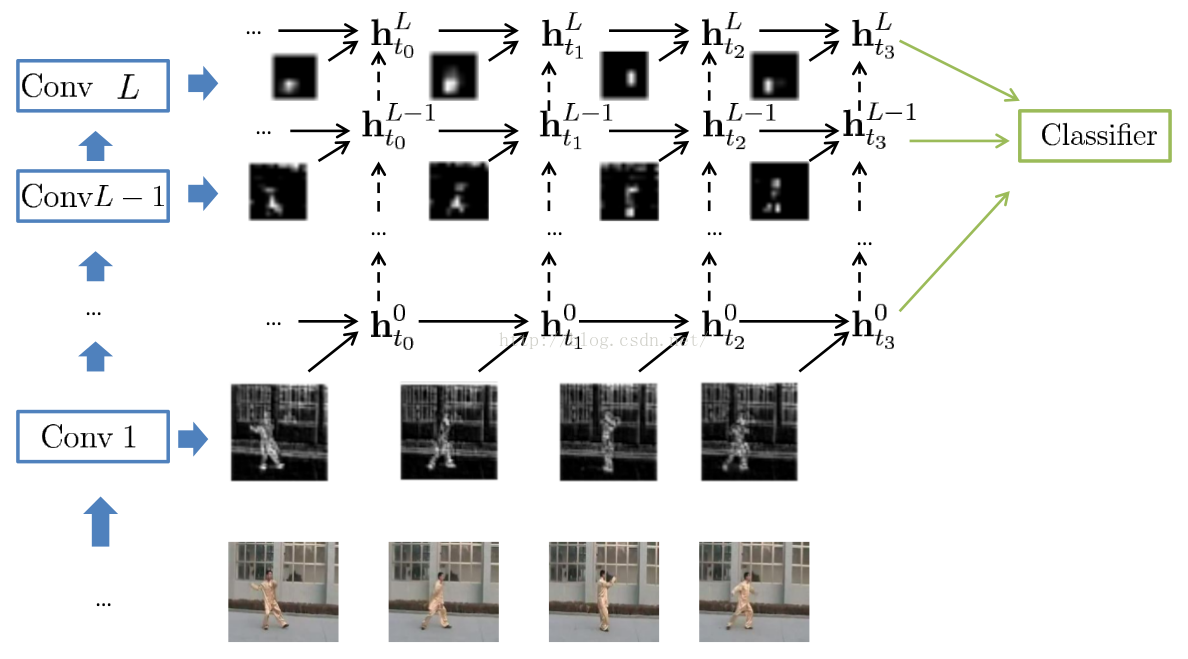
See Fig. 19.10. The inputs are RGB and flow representations of videos. Networks are pre-trained on ImageNet. We apply average pooling on the hidden-representations of the
last time-step to reduce their spatial dimension to 1 × 1, and feed the representations to 5 classifiers, composed by a linear layer with a softmax nonlineary. The classifier outputs are then averaged to get the final decision.
1 Motivation
Previous works on Recurrent CNNs has tended to focus on high-level features extracted from the 2D CNN top-layers. High-level features contain highly discriminative informa-
tion, they tend to have a low-spatial resolution. Thus, we argue that current RCN architectures are not well suited for capturing fine motion information. Instead, they are more
likely focus on global appearance changes.
Low-level features, on the other hand, preserve a higher spatial resolution from which we can model finer motion patterns. However, applying an RNN directly on intermediate
convolutional maps, inevitably results in a drastic number of parameters characterizing the input-to-hidden transformation due to the convolutional maps size. On the other hand,
convolutional maps preserve the frame spatial topology. To leverage these, we extend the GRU model and replace the fc RNN linear product operation with a convolution. Our GRU extension therefore encodes the locality and temporal smoothness prior of videos directly
in the model structure. Thus, all neurons in the CNN are recurrent.
2 Architecture
See Fig. 19.10. The inputs are RGB and flow representations of videos. Networks are pre-trained on ImageNet. We apply average pooling on the hidden-representations of the
last time-step to reduce their spatial dimension to 1 × 1, and feed the representations to 5 classifiers, composed by a linear layer with a softmax nonlineary. The classifier outputs are then averaged to get the final decision.

相关文章推荐
- Delving Deeper into Convolutional Networks for Learning Video Representations
- [深度学习论文笔记][Semantic Segmentation] Fully Convolutional Networks for Semantic Segmentation
- 深度学习论文笔记-Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- [深度学习论文笔记][Neural Arts] Inceptionism: Going Deeper into Neural Networks
- [深度学习论文笔记][Video Classification] Long-term Recurrent Convolutional Networks for Visual Recognition a
- 深度学习论文笔记:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- [深度学习论文笔记][Video Classification] Two-Stream Convolutional Networks for Action Recognition in Videos
- [深度学习论文笔记][Semantic Segmentation] Recurrent Convolutional Neural Networks for Scene Labeling
- [深度学习论文笔记][Video Classification] Large-scale Video Classification with Convolutional Neural Networks
- [深度学习论文笔记][Video Classification] Beyond Short Snippets: Deep Networks for Video Classification
- 深度学习论文笔记(六)--- FCN-2015年(Fully Convolutional Networks for Semantic Segmentation)
- [深度学习论文笔记][Image Classification] Very Deep Convolutional Networks for Large-Scale Image Recognitio
- deeplearning论文学习笔记(2)A critical review of recurrent neural networks for sequence learning
- Joint Deep Learning For Pedestrian Detection(论文笔记-深度学习:行人检测)
- 论文笔记之Learning Convolutional Neural Networks for Graphs
- [深度学习论文笔记] Convolutional Neuron Networks and its Applications
- deeplearning论文学习笔记(1)Convolutional Neural Networks for Sentence Classification
- 深度学习论文-Cyclical Learning Rates for Training Neural Networks
- 深度学习论文理解3:Flexible, high performance convolutional neural networks for image classification