神经网络一:介绍,示例,代码
2016-10-22 14:34
441 查看
有关神经网络的基本概述和神经网络模型,这里就不仔细介绍了。具体详细介绍可参见斯坦福大学的大牛Ng等人的介绍神经网络概述及其模型。这里主要介绍反向传导算法(Backpropagation
Algorithm)的具体推导,以及神经网络有关的简单示例和相关Python代码。
假设我们有一个固定样本集
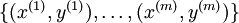
,它包含
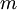
个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例
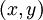
,其代价函数为:
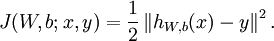
其中y是真实标签值,h是预测值。(注:这里相关变量取名是根据神经网络概述及其模型中的变量而来)给定一个包含
个样例的数据集,我们可以定义整体代价函数为:
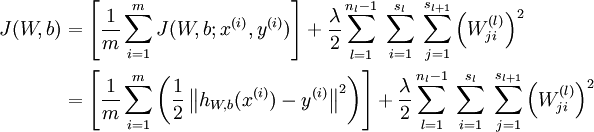
以上公式中的第一项
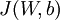
是一个均方差项。第二项是一个正则化项,其目的是减小权重的幅度,防止过拟合。
梯度下降法中每一次迭代都按照如下公式对参数
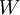
和
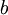
进行更新:
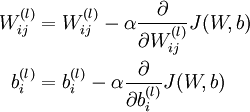
其中
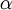
是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
首先来讲一下如何使用反向传播算法来计算
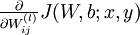
和
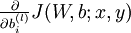
,这两项是单个样例
的代价函数
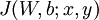
的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数
的偏导数:
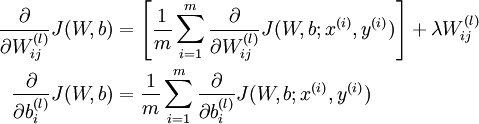
反向传播算法的思路如下:给定一个样例
,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括
的输出值。之后,针对第
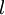
层的每一个节点

,我们计算出其偏差
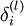
,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为
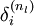
(第
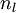
层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第
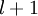
层节点)残差的加权平均值计算
,这些节点以
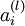
作为输入。看到这里,首先有疑问的是残差是什么,怎么样得到残差?残差其实是对z的偏导数。对于一个神经元,它和上一层的很多神经元相连接,这些神经元的输出经过一个加权,然后相加的结果就是Z,也就是说这z是神经元的真正输入,残差表示的就是最终的代价函数对网络中的一个个神经元输入的偏导。残差体现的是对于代价的贡献的敏感程度,对于一个大的残差,稍微给点输入,就不行了,导致最后的loss很大。z又是关于权重w的函数,所以,按照链式法则可以传递到w对代价函数的贡献敏感度上。
下面将给出反向传导算法的细节:
进行前馈传导计算,利用前向传导公式,得到
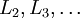
直到输出层
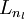
的激活值。
对于第
层(输出层)的每个输出单元
,我们根据以下公式计算残差:
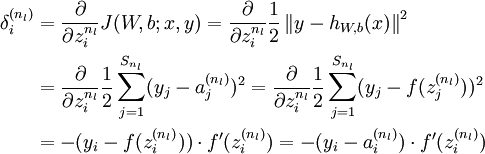
注:最终的目的还是求解
和
,这里转换了求解变量,最后根据偏导公式:

来计算结果,对于b同样求得,见后面介绍。
对
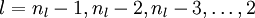
的各个层,第
层的第
个节点的残差计算方法如下:
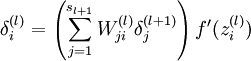
{译者注:
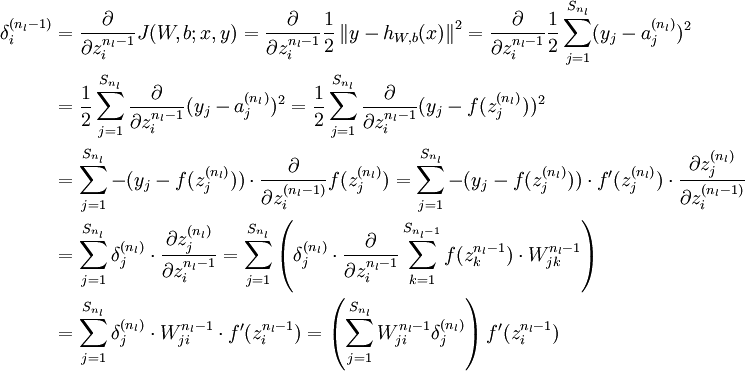
将上式中的
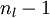
与
的关系替换为
与
的关系,就可以得到:
以上逐次从后向前求导的过程即为“反向传导”的本意所在。 ]
计算我们需要的偏导数,计算方法如下:根据公式
,其中Z
= Wa+b,得到:
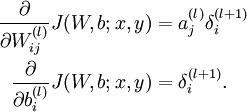
如果选择
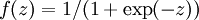
,也就是sigmoid函数,那么它的导数就是
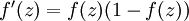
;如果选择tanh函数,那它的导数就是
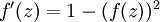
。
那么,反向传播算法可表示为以下几个步骤:
进行前馈传导计算,利用前向传导公式,得到
直到输出层
的激活值。
对输出层(第
层),计算:
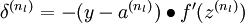
对于
的各层,计算:
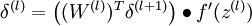
计算最终需要的偏导数值:
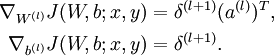
5.最后不断更新:
更新的终止条件有:1):权重的更新低于某个阈值;2):预测的错误率低于某个阈值;3):达到一定的循环次数,退出循环

如图,这是示例的神经网络模型和具体的一些值,其中权重w的值时随机初始化的(不相等即可)。
根据公式
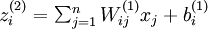
和
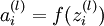
算出相应的激活值为;Ij
= Zi,Oj = ai

注:这里选择
,也就是sigmoid函数,那么它的导数就是
。
下面开始用反向传导算法,更新W和b的值:这里的Errj = δ。先算出每一层的偏差:

根据公式
这里选择的步长(α)为:0.9。最后更新算出所有的权重W和b的值:

下面是训练集和测试集:
结果为:
([0, 0], array([ 0.0171341]))
([0, 1], array([ 0.99848996]))
([1, 0], array([ 0.99852684]))
([1, 1], array([ 0.04127888]))
可以设置阈值,比如当测试值>0.5是结果为1,否则为0。这样测试集结果与训练集相同,即全部正确
Algorithm)的具体推导,以及神经网络有关的简单示例和相关Python代码。
一 反向传导算法的推导过程
以人脑中的神经网络为启发,历史上出现过很多不同的版本,其中 最著名的版本的算法是1980年的backpropagation。backpropagation被使用在多层向前神经网络上。假设我们有一个固定样本集
,它包含
个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例
,其代价函数为:
其中y是真实标签值,h是预测值。(注:这里相关变量取名是根据神经网络概述及其模型中的变量而来)给定一个包含
个样例的数据集,我们可以定义整体代价函数为:
以上公式中的第一项
是一个均方差项。第二项是一个正则化项,其目的是减小权重的幅度,防止过拟合。
梯度下降法中每一次迭代都按照如下公式对参数
和
进行更新:
其中
是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
首先来讲一下如何使用反向传播算法来计算
和
,这两项是单个样例
的代价函数
的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数
的偏导数:
反向传播算法的思路如下:给定一个样例
,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括
的输出值。之后,针对第
层的每一个节点
,我们计算出其偏差
,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为
(第
层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第
层节点)残差的加权平均值计算
,这些节点以
作为输入。看到这里,首先有疑问的是残差是什么,怎么样得到残差?残差其实是对z的偏导数。对于一个神经元,它和上一层的很多神经元相连接,这些神经元的输出经过一个加权,然后相加的结果就是Z,也就是说这z是神经元的真正输入,残差表示的就是最终的代价函数对网络中的一个个神经元输入的偏导。残差体现的是对于代价的贡献的敏感程度,对于一个大的残差,稍微给点输入,就不行了,导致最后的loss很大。z又是关于权重w的函数,所以,按照链式法则可以传递到w对代价函数的贡献敏感度上。
下面将给出反向传导算法的细节:
进行前馈传导计算,利用前向传导公式,得到
直到输出层
的激活值。
对于第
层(输出层)的每个输出单元
,我们根据以下公式计算残差:
注:最终的目的还是求解
和
,这里转换了求解变量,最后根据偏导公式:
来计算结果,对于b同样求得,见后面介绍。
对
的各个层,第
层的第
个节点的残差计算方法如下:
{译者注:
将上式中的
与
的关系替换为
与
的关系,就可以得到:
以上逐次从后向前求导的过程即为“反向传导”的本意所在。 ]
计算我们需要的偏导数,计算方法如下:根据公式
,其中Z
= Wa+b,得到:
如果选择
,也就是sigmoid函数,那么它的导数就是
;如果选择tanh函数,那它的导数就是
。
那么,反向传播算法可表示为以下几个步骤:
进行前馈传导计算,利用前向传导公式,得到
直到输出层
的激活值。
对输出层(第
层),计算:
对于
的各层,计算:
计算最终需要的偏导数值:
5.最后不断更新:
更新的终止条件有:1):权重的更新低于某个阈值;2):预测的错误率低于某个阈值;3):达到一定的循环次数,退出循环
二 简单示例
如图,这是示例的神经网络模型和具体的一些值,其中权重w的值时随机初始化的(不相等即可)。
根据公式
和
算出相应的激活值为;Ij
= Zi,Oj = ai
注:这里选择
,也就是sigmoid函数,那么它的导数就是
。
下面开始用反向传导算法,更新W和b的值:这里的Errj = δ。先算出每一层的偏差:
根据公式
这里选择的步长(α)为:0.9。最后更新算出所有的权重W和b的值:
三 Python示例代码
<pre name="code" class="python">import numpy as np #下面定义所使用的激活函数及其相应的导数的函数 #这里使用了正切函数和logistic函数 def tanh(x): return np.tanh(x) def tanh_deriv(x): return 1.0-np.tanh(x)*np.tanh(x) def logistic(x): return 1/(1+np.exp(-x)) def logistic_deriv(x): return logistic(x)*(1-logistic(x)) class NeuralNetwork:#定义一个类 def __init__(self, layers, activation='tanh'): if activation == 'logistic': self.activation = logistic self.activation_deriv = logistic_deriv elif activation == 'tanh': self.activation = tanh self.activation_deriv = tanh_deriv #对权重初始化。对每一层的权重都要初始化 self.weights = [] for i in range(1,len(layers)-1): #对每一层的权重都要初始化初始值范围在-0.25~0.25之间,然后保存在weight中 self.weights.append((2*np.random.random((layers[i-1]+1,layers[i]+1))-1)*0.25) self.weights.append((2*np.random.random((layers[i]+1,layers[i+1]))-1)*0.25) def fit(self, X, y, learning_rate=0.2, epochs=10000):#默认学习率即步长为0.2,循环最多的次数为1000 X = np.atleast_2d(X)#判断输入训练集是否为二维 temp = np.ones([X.shape[0],X.shape[1]+1])#列加1是因为最后一列要存入标签分类,这里标签都为1 temp[:,0:-1] = X X = temp y = np.array(y)#训练真实值 for k in range(epochs):#循环 i = np.random.randint(X.shape[0])#随机选取训练集中的一个 a = [X[i]] #计算激活值 for l in range(len(self.weights)): a.append(self.activation(np.dot(a[l], self.weights[l]))) error = y[i] - a[-1]#计算偏差 deltas = [error*self.activation_deriv(a[-1])]#输出层误差 #下面计算隐藏层 for l in range(len(a)-2,0,-1): deltas.append(deltas[-1].dot(self.weights[l].T)*self.activation_deriv(a[l])) deltas.reverse() #下面开始更新权重和偏向 for i in range(len(self.weights)): layer = np.atleast_2d(a[i]) delta = np.atleast_2d(deltas[i]) self.weights[i] += learning_rate * layer.T.dot(delta) #预测函数 def predict(self, x): x = np.array(x) temp = np.ones(x.shape[0]+1) temp[0:-1] = x a = temp for l in range(0, len(self.weights)): a = self.activation(np.dot(a, self.weights[l])) for i in range(a): if a[i]>0.5: a[i] = 1 else: a[i] = 0 return a
下面是训练集和测试集:
import numpy as np nn = NeuralNetwork([2,2,1],'tanh') X = np.array([[0,0],[0,1],[1,0],[1,1]]) y = np.array([0,1,1,0]) nn.fit(X, y) for i in [[0,0],[0,1],[1,0],[1,1]]: print(i, nn.predict(i))
结果为:
([0, 0], array([ 0.0171341]))
([0, 1], array([ 0.99848996]))
([1, 0], array([ 0.99852684]))
([1, 1], array([ 0.04127888]))
可以设置阈值,比如当测试值>0.5是结果为1,否则为0。这样测试集结果与训练集相同,即全部正确

相关文章推荐
- TensorFlow入门,基本介绍,基本概念,计算图,pip安装,helloworld示例,实现简单的神经网络
- 机器学习与神经网络(三):自适应线性神经元的介绍和Python代码实现
- 机器学习与神经网络(四):BP神经网络的介绍和Python代码实现
- 机器学习与神经网络(二):感知器的介绍和Python代码实现
- Seq2Seq非常好的代码(机器翻译、对话生成等):漫谈四种神经网络序列解码模型【附示例代码】
- 神经网络简单代码示例
- 纯用NumPy实现神经网络的示例代码
- 深度学习神经网络从欠拟合到拟合的调整方法及示例代码
- tcp网络包“粘包”的介绍和解决方案代码示例
- 漫谈四种神经网络序列解码模型【附示例代码】 glimpse attention
- HttpContext介绍及其用法示例代码
- 神经网络介绍―利用反向传播算法的模式学习
- jQuery LigerUI 插件介绍及使用之ligerDrag和ligerResizable示例代码打包
- jQuery LigerUI 插件介绍及使用之ligerDrag和ligerResizable示例代码打包
- BizTalk ESB Toolkit : 核心组件介绍及代码示例 (原创翻译)
- matlab通用神经网络代码
- DOM4J介绍与代码示例(二)
- DOM4J介绍与代码示例(一)
- 微软一站式示例代码库Mei Liang对话Channel 9 著名主持人Robert Green - 介绍一站式示例代码浏览器
- ACE代码示例:实现计算机网络授时的小程序