【论文笔记】A Convolutional Neural Network Cascade for Face Detection
2016-10-16 08:32
971 查看
论文:A
Convolutional Neural Network Cascade for Face Detection.pdf
实现:https://github.com/anson0910/CNN_face_detection
该论文发表于2015年CVPR上,作者提出了一种级连的CNN网络结构用于人脸识别,论文的主要贡献有以下四点:
提出了一种级连的CNN网络结构用于高速的人脸检测。
设计了一种边界校订网络用于更好的定位人脸位置。
提出了一种多分辨率的CNN网络结构,有着比单网络结构更强的识别能力,和一个微小的额外开销。
在FDDB上达到了当时最高的分数。
其实论文的主体框架依然是基于V-J的瀑布流思想,不同以往的是级连了CNN网络(由于论文阅读量有限,不知是否已有前人做出了此类贡献),整个网络的处理流程如下图所示:
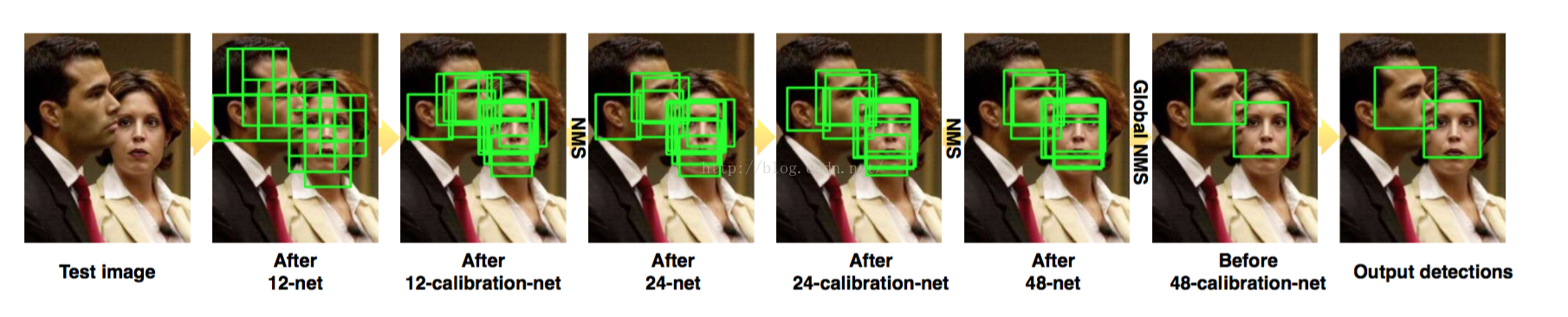
可以看出,整个处理流程里包含了六个网络和三次NMS,六个网络按顺序分别是12-net,12-calibration-net,24-net,24-calibration-net,48-net,48-calibration-net。
包含三个二分类网络用于分类其是否为人脸,另外三个calibration网络用于矫正人脸框边界。
其中12-net,24-net和48-net的网络结构如下图所示:
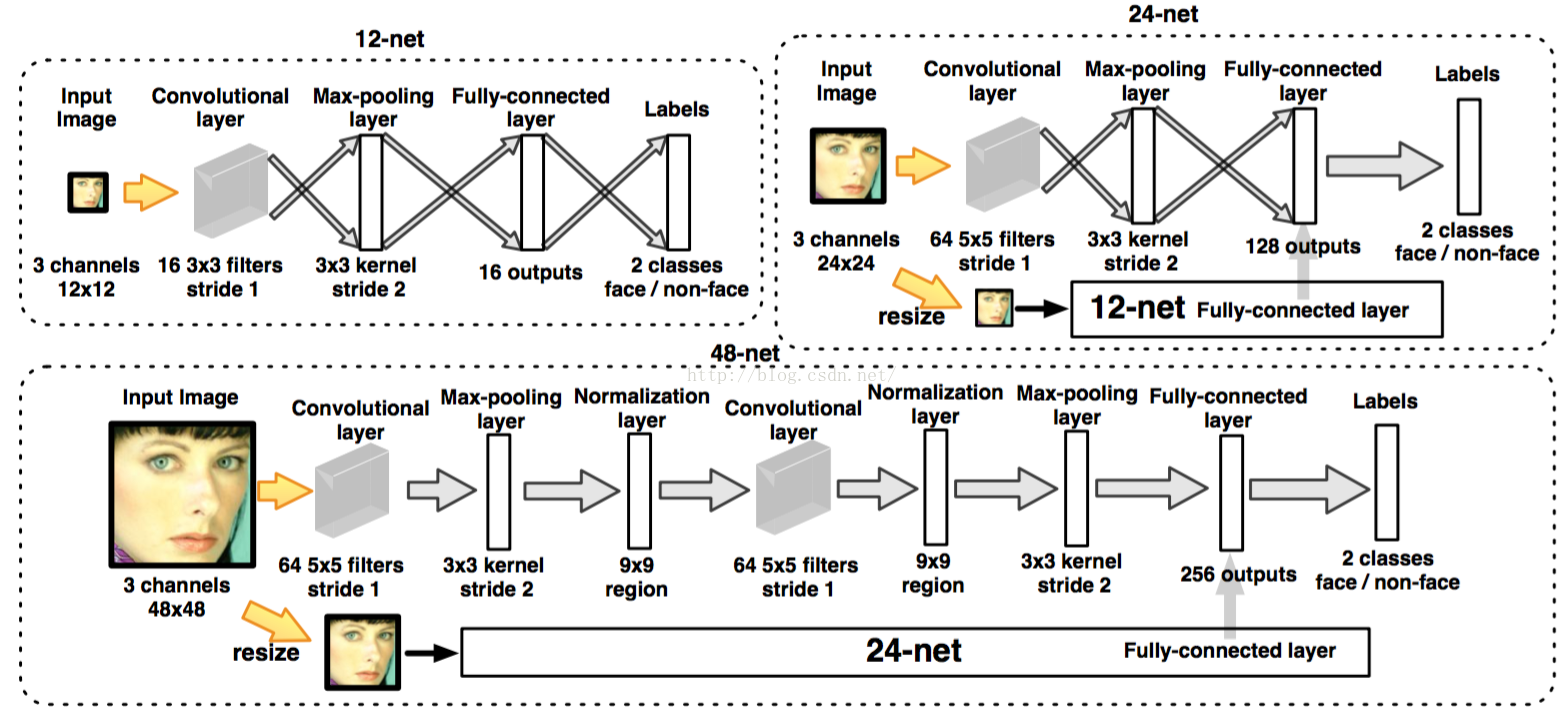
这三个网络的结构大致相同,不同之处在于其读入的图片分辨率和网络的复杂度,其是逐级递增的,了解V-J框架不难理解其实现原理,前面的简单网络拒绝绝大部分非人脸区域,将难以分辨的交由下一级更复杂的网络以获得更准确的结果,这里着重讲其多分辨率的图片读入方式。
要想在CNN结构下实现V-J瀑布级连结构,就要保证瀑布的前端足够简单并有较高的召回率且能够拒绝大部分非人脸区域,将图片缩放可以满足需求,比例为12/F,24/F,48/F,F为检测人脸的最小尺寸,这样对于一张800*600的图片,检测尺寸为40*40的人脸,窗口移动步伐为4个像素,那么会产生((800*12/40-12)/4+1)*((600*12/40-12)/4+1)=2494个窗口。不仅使得窗口数量变少而且窗口的缩放也使前期的CNN结构更加简单,实现了级连的思想。
另外在24-net和48-net的全连接层还会连接该图像缩放后在前一层网络的全连接输出,这么做的目的是为了检测更小的人脸,虽然会带来额外开销,但总体来说,该开销可忽略不计,但是其可以较明显的提高识别率。
12-calibration-net,24-calibration-net,48-calibration-net的结构如下图所示:
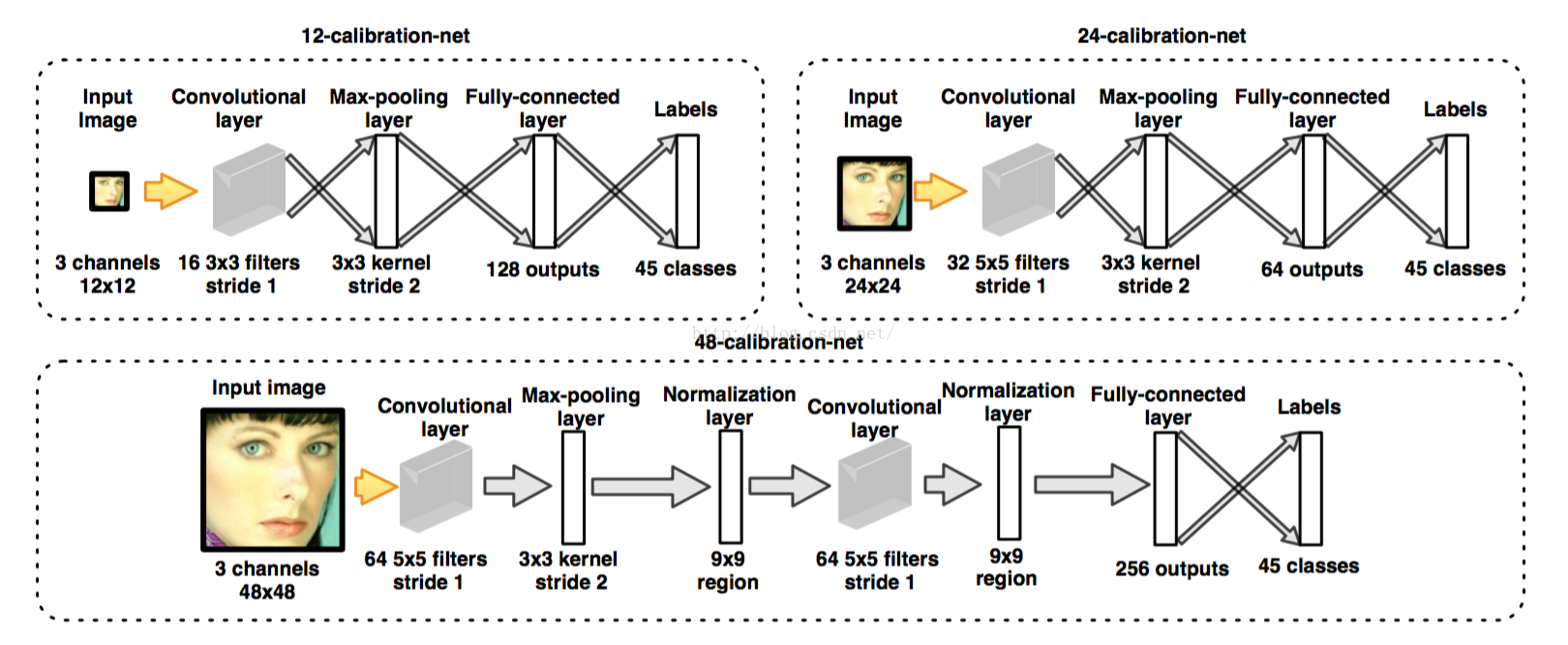
这三个网络用于矫正人脸检测框的边界,往往得分最高的边界框并非最佳结果,经过校准后其能更好的定位人脸,其矫正原理其实很简单,就是对原图做45次变换,然后每个变换后的边界框都有一个得分,对于得分高于某个设定的阈值时,将其累加进原边界,最后结果取平均,就是最佳边界框,关于45次变换,有如下得来:

xn,yn是其坐标移动比例,sn是其尺寸缩放比例
变换方式如下:
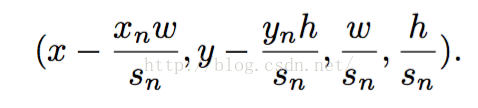
笔者说R-CNN并不适合于人脸检测,从论文中效果来看,不管是思想还是其实现,这种方法的确比R-CNN简便不少。
该论文最具开创性的两点:
一是其多分辨率的网络级连方法,这让我领略了V-J框架在CNN上效果优异的一次演绎。
在pico里图片一直保持着相同的尺寸,不同的是每一层树的数量不断增加,层数不断增多,从而保证复杂度的增高,其实也可以尝试这种多分辨率的策略,在前几层,读的图片可以分辨率低一些,这样,就可以少检测一些窗口,从而提升效率,但是不同于CNN,这么做也许会导致前面几层的召回率和准确率大大降低而得不偿失。
二是其边界校订网络,相比于R-CNN,该网络可称之为大巧不工的典范。
其实在pico中,也有类似边界校订网络这种离散式的加权平均校订方式,但是它只在最后一步做NMS时才做处理,那么如果将该方法加入每个层之后,或许可以在不影响其准确率的前提下显著减少下一层所需处理的样本,获得效率上的进一步提升。
Convolutional Neural Network Cascade for Face Detection.pdf
实现:https://github.com/anson0910/CNN_face_detection
该论文发表于2015年CVPR上,作者提出了一种级连的CNN网络结构用于人脸识别,论文的主要贡献有以下四点:
提出了一种级连的CNN网络结构用于高速的人脸检测。
设计了一种边界校订网络用于更好的定位人脸位置。
提出了一种多分辨率的CNN网络结构,有着比单网络结构更强的识别能力,和一个微小的额外开销。
在FDDB上达到了当时最高的分数。
其实论文的主体框架依然是基于V-J的瀑布流思想,不同以往的是级连了CNN网络(由于论文阅读量有限,不知是否已有前人做出了此类贡献),整个网络的处理流程如下图所示:
可以看出,整个处理流程里包含了六个网络和三次NMS,六个网络按顺序分别是12-net,12-calibration-net,24-net,24-calibration-net,48-net,48-calibration-net。
包含三个二分类网络用于分类其是否为人脸,另外三个calibration网络用于矫正人脸框边界。
其中12-net,24-net和48-net的网络结构如下图所示:
这三个网络的结构大致相同,不同之处在于其读入的图片分辨率和网络的复杂度,其是逐级递增的,了解V-J框架不难理解其实现原理,前面的简单网络拒绝绝大部分非人脸区域,将难以分辨的交由下一级更复杂的网络以获得更准确的结果,这里着重讲其多分辨率的图片读入方式。
要想在CNN结构下实现V-J瀑布级连结构,就要保证瀑布的前端足够简单并有较高的召回率且能够拒绝大部分非人脸区域,将图片缩放可以满足需求,比例为12/F,24/F,48/F,F为检测人脸的最小尺寸,这样对于一张800*600的图片,检测尺寸为40*40的人脸,窗口移动步伐为4个像素,那么会产生((800*12/40-12)/4+1)*((600*12/40-12)/4+1)=2494个窗口。不仅使得窗口数量变少而且窗口的缩放也使前期的CNN结构更加简单,实现了级连的思想。
另外在24-net和48-net的全连接层还会连接该图像缩放后在前一层网络的全连接输出,这么做的目的是为了检测更小的人脸,虽然会带来额外开销,但总体来说,该开销可忽略不计,但是其可以较明显的提高识别率。
12-calibration-net,24-calibration-net,48-calibration-net的结构如下图所示:
这三个网络用于矫正人脸检测框的边界,往往得分最高的边界框并非最佳结果,经过校准后其能更好的定位人脸,其矫正原理其实很简单,就是对原图做45次变换,然后每个变换后的边界框都有一个得分,对于得分高于某个设定的阈值时,将其累加进原边界,最后结果取平均,就是最佳边界框,关于45次变换,有如下得来:
xn,yn是其坐标移动比例,sn是其尺寸缩放比例
变换方式如下:
笔者说R-CNN并不适合于人脸检测,从论文中效果来看,不管是思想还是其实现,这种方法的确比R-CNN简便不少。
最后说说该论文对我的启发:
该论文最具开创性的两点:一是其多分辨率的网络级连方法,这让我领略了V-J框架在CNN上效果优异的一次演绎。
在pico里图片一直保持着相同的尺寸,不同的是每一层树的数量不断增加,层数不断增多,从而保证复杂度的增高,其实也可以尝试这种多分辨率的策略,在前几层,读的图片可以分辨率低一些,这样,就可以少检测一些窗口,从而提升效率,但是不同于CNN,这么做也许会导致前面几层的召回率和准确率大大降低而得不偿失。
二是其边界校订网络,相比于R-CNN,该网络可称之为大巧不工的典范。
其实在pico中,也有类似边界校订网络这种离散式的加权平均校订方式,但是它只在最后一步做NMS时才做处理,那么如果将该方法加入每个层之后,或许可以在不影响其准确率的前提下显著减少下一层所需处理的样本,获得效率上的进一步提升。

相关文章推荐
- 论文《A Convolutional Neural Network Cascade for Face Detection》笔记
- 论文《A Convolutional Neural Network Cascade for Face Detection》笔记
- 论文《A Convolutional Neural Network Cascade for Face Detection》笔记
- 级联人脸检测--A Convolutional Neural Network Cascade for Face Detection
- 《A Convolutional Neural Network Cascade for Face Detection》
- 论文笔记 MSCNN:A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- [文献阅读]A Convolutional Neural Network Cascade for Face Detection
- A Convolutional Neural Network Cascade for Face Detection
- 《A Convolutional Neural Network Cascade for Face Detection》
- 多尺度R-CNN论文笔记(5): A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- Deep Convolutional Network Cascade for Facial Point Detection阅读笔记
- Single-Shot Refinement Neural Network for Object Detection-论文笔记
- Deep Convolutional Network Cascade for Facial Point Detection阅读笔记
- MSCNN 论文解析(A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- Multi-Task Convolutional Neural Network for Face Recognition阅读笔记
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
- A Convolutional Neural Network Cascade for Face Detect
- 人脸识别方向论文笔记(3)-- Sparsifying Neural Network Connections for Face Recognition
- Deep Convolutional Network Cascade for Facial Point Detection阅读笔记
- [论文解读] MSCNN: A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection