Java如何解析某个目录下xml文件,将XML文件转换为报表数据源?
2016-10-13 16:39
405 查看
在Java开发的报表工具FineReport中,假如在目录下保存了几个XML文件,希望把XML文件转换为报表数据源,同时希望展示动态xml数据源的效果,这时可通过参数的方式,动态获取xml字段中的值再作为报表数据源。
最终用于制作报表的数据源形式如下:
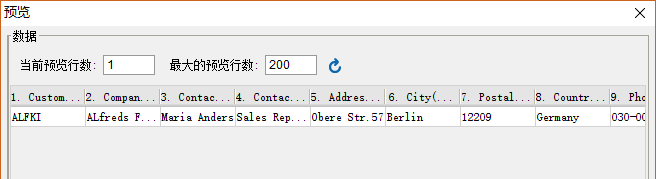
对于这样的情况我们如何来实现呢?FineReport中可以通过自定义程序数据集来对xml字段数据进行解析,最终返回所希望的数据表。实现步骤如下:
1、定义XMLColumnNameType4Demo封装类
首先定义参数name及type,供其他类直接调用,安全性比较高,详细代码如下:
2、定义XMLParseDemoDataModel.java类文件
定义XMLParseDemoDataModel.java类继承AbstractDataModel接口,实现getColumnCount、getColumnName、getRowCount、getValueAt四个方法,详细代码如下:
3、定义程序数据集XMLDemoTableData
通过参数filename,动态显示xml文件内容,首先xml文件需要放到某个目录下,如下代码是放到D盘,并且定义需要解析的数据列,这边定义的数据列名称,根xml内字段名称是一一对用的。详细代码如下:
4、编译程序数据源
分别编译XMLColumnNameType4Demo.java、XMLParseDemoDataModel.java、XMLDemoTableData.java三个类文件,将生成的class文件放于%FR_HOME%\WebReport\WEB-INF\classes\com\fr\data下。
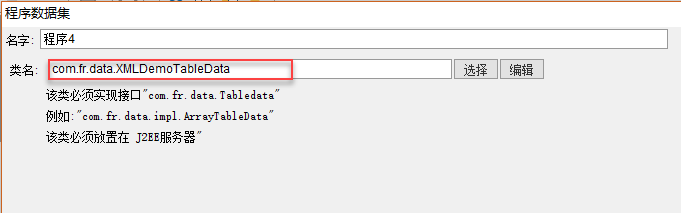
5 配置程序数据源
新建报表,模板数据集>程序数据集,选择我们定义好的程序数据集XMLDemoTableData.class文件,名字可以自定义,如程序1。
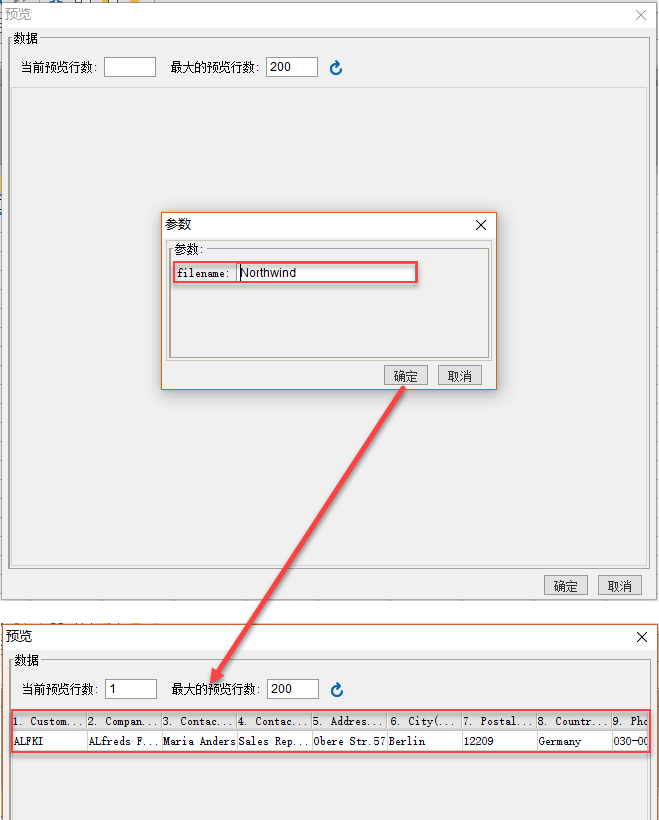
6、使用程序数据源
在模板数据集窗口,点击预览按钮,弹出参数对话框,输入要显示的xml文件名称,点击确定则可以把Northwind.xml文件里面的数据读取出来转换报表数据源了,如下图:
Northwind.xml记录数据格式如下: <?xmlversion="1.0" encoding="UTF-8"?> <Northwind> <Customers> <CustomerID>ALFKI</CustomerID> <CompanyName>ALfredsFutterkiste</CompanyName> <ContactName>MariaAnders</ContactName> <ContactTitle>SalesRepresentative</ContactTitle> <Address>ObereStr.57</Address> <City>Berlin</City> <PostalCode>12209</PostalCode> <Country>Germany</Country> <Phone>030-0074321</Phone> <Fax>030-0076545</Fax> </Customers> </Northwind>
最终用于制作报表的数据源形式如下:
对于这样的情况我们如何来实现呢?FineReport中可以通过自定义程序数据集来对xml字段数据进行解析,最终返回所希望的数据表。实现步骤如下:
1、定义XMLColumnNameType4Demo封装类
首先定义参数name及type,供其他类直接调用,安全性比较高,详细代码如下:
packagecom.fr.data;
publicclass XMLColumnNameType4Demo {
private int type = -1;
private String name = null;
public XMLColumnNameType4Demo(String name,int type) {
this.name = name;
this.type = type;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getType() {
return type;
}
public void setType(int type) {
this.type = type;
}
}2、定义XMLParseDemoDataModel.java类文件
定义XMLParseDemoDataModel.java类继承AbstractDataModel接口,实现getColumnCount、getColumnName、getRowCount、getValueAt四个方法,详细代码如下:
packagecom.fr.data;
importjava.io.File;
importjava.util.ArrayList;
importjava.util.List;
importjavax.xml.parsers.SAXParser;
importjavax.xml.parsers.SAXParserFactory;
importorg.xml.sax.Attributes;
importorg.xml.sax.SAXException;
importorg.xml.sax.helpers.DefaultHandler;
importcom.fr.base.FRContext;
importcom.fr.data.AbstractDataModel;
importcom.fr.general.ComparatorUtils;
importcom.fr.general.data.TableDataException;
/**
* XMLParseDemoDataModel
*
* DataModel是获取数据的接口
*
* 这里通过init方法一次性取数后,构造一个二维表对象来实现DataModel的各个取数方法
*/
publicclass XMLParseDemoDataModel extends AbstractDataModel {
// 数据类型标识
public static final int COLUMN_TYPE_STRING= 0;
public static final int COLUMN_TYPE_INTEGER= 1;
public static final int COLUMN_TYPE_BOOLEAN= 2;
// 缓存取出来的数据
protected List row_list = null;
// 数据对应的节点路径
private String[] xPath;
// 节点路径下包含的需要取数的节点
private XMLColumnNameType4Demo[]columns;
private String filePath;
public XMLParseDemoDataModel(Stringfilename, String[] xPath,
XMLColumnNameType4Demo[] columns){
this.filePath = filename;
this.xPath = xPath;
this.columns = columns;
}
/**
* 取出列的数量
*/
public int getColumnCount() throwsTableDataException {
return columns.length;
}
/**
* 取出相应的列的名称
*/
public String getColumnName(intcolumnIndex) throws TableDataException {
if (columnIndex < 0 || columnIndex>= columns.length)
return null;
String columnName =columns[columnIndex] == null ? null
:columns[columnIndex].getName();
return columnName;
}
/**
* 取出得到的结果集的总的行数
*/
public int getRowCount() throwsTableDataException {
this.init();
return row_list.size();
}
/**
* 取出相应位置的值
*/
public Object getValueAt(int rowIndex, intcolumnIndex)
throws TableDataException {
this.init();
if (rowIndex < 0 || rowIndex >=row_list.size() || columnIndex < 0
|| columnIndex >=columns.length)
return null;
return ((Object[])row_list.get(rowIndex))[columnIndex];
}
/**
* 释放一些资源,取数结束后,调用此方法来释放资源
*/
public void release() throws Exception{
if (this.row_list != null) {
this.row_list.clear();
this.row_list = null;
}
}
/**************************************************** */
/** ***********以上是实现DataModel的方法*************** */
/**************************************************** */
/**************************************************** */
/** ************以下为解析XML文件的方法*****************/
/**************************************************** */
// 一次性将数据取出来
protected void init() throwsTableDataException {
if (this.row_list != null)
return;
this.row_list = new ArrayList();
try {
// 使用SAX解析XML文件,使用方法请参见JAVA SAX解析
SAXParserFactory f =SAXParserFactory.newInstance();
SAXParser parser =f.newSAXParser();
parser.parse(newFile(XMLParseDemoDataModel.this.filePath),
new DemoHandler());
} catch (Exception e) {
e.printStackTrace();
FRContext.getLogger().error(e.getMessage(), e);
}
}
/**
* 基本原理就是解析器在遍历文件时发现节点开始标记时,调用startElement方法读取节点内部内容时,调用characters方法
* 发现节点结束标记时,调用endElement
*/
private class DemoHandler extendsDefaultHandler {
private List levelList = newArrayList(); // 记录当前节点的路径
private Object[] values; // 缓存一条记录
private int recordIndex = -1; // 当前记录所对应的列的序号,-1表示不需要记录
public void startElement(String uri,String localName, String qName,
Attributes attributes) throwsSAXException {
// 记录下
levelList.add(qName);
if (isRecordWrapTag()) {
// 开始一条新数据的记录
values = newObject[XMLParseDemoDataModel.this.columns.length];
} else if (needReadRecord()) {
// 看看其对应的列序号,下面的characters之后执行时,根据这个列序号来设置值存放的位置。
recordIndex =getColumnIndex(qName);
}
}
public void characters(char[] ch, intstart, int length)
throws SAXException {
if (recordIndex > -1) {
// 读取值
String text = new String(ch,start, length);
XMLColumnNameType4Demo type =XMLParseDemoDataModel.this.columns[recordIndex];
Object value = null;
if (type.getType() ==COLUMN_TYPE_STRING) {
value = text;
}
if (type.getType() ==COLUMN_TYPE_INTEGER) {
value = newInteger(text);
} else if (type.getType() ==COLUMN_TYPE_BOOLEAN) {
value = newBoolean(text);
}
values[recordIndex] = value;
}
}
public void endElement(String uri,String localName, String qName)
throws SAXException {
try {
if (isRecordWrapTag()) {
// 一条记录结束,就add进list中
XMLParseDemoDataModel.this.row_list.add(values);
values = null;
} else if (needReadRecord()){
recordIndex = -1;
}
} finally {
levelList.remove(levelList.size() - 1);
}
}
// 正好匹配路径,确定是记录外部的Tag
private boolean isRecordWrapTag(){
if (levelList.size() ==XMLParseDemoDataModel.this.xPath.length
&& compareXPath()){
return true;
}
return false;
}
// 需要记录一条记录
private boolean needReadRecord() {
if (levelList.size() ==(XMLParseDemoDataModel.this.xPath.length + 1)
&& compareXPath()){
return true;
}
return false;
}
// 是否匹配设定的XPath路径
private boolean compareXPath() {
String[] xPath =XMLParseDemoDataModel.this.xPath;
for (int i = 0; i <xPath.length; i++) {
if(!ComparatorUtils.equals(xPath[i], levelList.get(i))) {
return false;
}
}
return true;
}
// 获取该字段的序号
private int getColumnIndex(StringcolumnName) {
XMLColumnNameType4Demo[] nts =XMLParseDemoDataModel.this.columns;
for (int i = 0; i < nts.length;i++) {
if(ComparatorUtils.equals(nts[i].getName(), columnName)) {
return i;
}
}
return -1;
}
}
}3、定义程序数据集XMLDemoTableData
通过参数filename,动态显示xml文件内容,首先xml文件需要放到某个目录下,如下代码是放到D盘,并且定义需要解析的数据列,这边定义的数据列名称,根xml内字段名称是一一对用的。详细代码如下:
packagecom.fr.data;
importjava.io.BufferedInputStream;
importjava.io.ByteArrayInputStream;
importjava.io.File;
importjava.io.FileInputStream;
importjava.io.FileNotFoundException;
importjava.io.FileReader;
importjava.io.InputStream;
importjava.io.Reader;
importjava.util.*;
importjavax.xml.stream.XMLEventReader;
importjavax.xml.stream.XMLInputFactory;
importjavax.xml.stream.XMLStreamException;
importjavax.xml.stream.events.XMLEvent;
importcom.fr.base.Parameter;
importcom.fr.data.AbstractParameterTableData;
importcom.fr.general.data.DataModel;
importcom.fr.script.Calculator;
importcom.fr.stable.ParameterProvider;
importcom.fr.stable.StringUtils;
/**
* XMLDemoTableData
*
* 这是一个按参数来解析不同地址XML文件的demo
*
* AbstractParameterTableData 包装了有参数数据集的基本实现
*/
publicclass XMLDemoTableData extends AbstractParameterTableData {
// 构造函数
public XMLDemoTableData() {
// 定义需要的参数,这里定义一个参数,参数名为filename,给其一个默认值"Northwind.xml"
this.parameters = newParameter[1];
this.parameters[0] = newParameter("filename", "Northwind");
}
/**
* 返回获取数据的执行对象
* 系统取数时,调用此方法来返回一个获取数据的执行对象
* 注意!当数据集需要根据不同参数来多次取数时,此方法在一个计算过程中会被多次调用。
*/
@SuppressWarnings("unchecked")
public DataModel createDataModel(Calculatorcalculator) {
// 获取传进来的参数
ParameterProvider[] params =super.processParameters(calculator);
// 根据传进来的参数,等到文件的路径
String filename = null;
for (int i = 0; i < params.length;i++) {
if (params[i] == null)continue;
if("filename".equals(params[i].getName())) {
filename =(String)params[i].getValue();
}
}
String filePath;
if (StringUtils.isBlank(filename)){
filePath ="D://DefaultFile.xml";
} else {
filePath = "D://" +filename + ".xml";
}
// 定义需要解析的数据列,机器
// XMLColumnNameType4Demo[] columns = newXMLColumnNameType4Demo[7];
// columns[0] = newXMLColumnNameType4Demo("CustomerID",XMLParseDemoDataModel.COLUMN_TYPE_STRING);
// columns[1] = newXMLColumnNameType4Demo("CompanyName",XMLParseDemoDataModel.COLUMN_TYPE_STRING);
// columns[2] = newXMLColumnNameType4Demo("ContactName",XMLParseDemoDataModel.COLUMN_TYPE_STRING);
// columns[3] = newXMLColumnNameType4Demo("ContactTitle",XMLParseDemoDataModel.COLUMN_TYPE_STRING);
// columns[4] = newXMLColumnNameType4Demo("Address",XMLParseDemoDataModel.COLUMN_TYPE_STRING);
// columns[5] = newXMLColumnNameType4Demo("City",XMLParseDemoDataModel.COLUMN_TYPE_STRING);
// columns[6] = new XMLColumnNameType4Demo("Phone",XMLParseDemoDataModel.COLUMN_TYPE_STRING);
List list=new ArrayList();
XMLInputFactory inputFactory =XMLInputFactory.newInstance();
InputStream in;
try {
in = new BufferedInputStream(newFileInputStream(new File(filePath)));
XMLEventReader reader =inputFactory.createXMLEventReader(in);
readCol(reader,list);
in.close();
} catch (Exception e) {
// TODO Auto-generated catchblock
e.printStackTrace();
}
XMLColumnNameType4Demo[]columns=(XMLColumnNameType4Demo[])list.toArray(newXMLColumnNameType4Demo[0]);
// 定义解析的数据在xml文件结构中的位置
String[] xpath = new String[2];
xpath[0] = "Northwind";
xpath[1] = "Customers";
/*
* 说明
* 提供的样例xml文件的格式是:
* <Notrhwind>
* <Customers>
* <CustomerID>ALFKI</CustomerID>
* <CompanyName>AlfredsFutterkiste</CompanyName>
* <ContactName>MariaAnders</ContactName>
* <ContactTitle>SalesRepresentative</ContactTitle>
* <Address>Obere Str. 57</Address>
* <City>Berlin</City>
* <PostalCode>12209</PostalCode>
* <Country>Germany</Country>
* <Phone>030-0074321</Phone>
* <Fax>030-0076545</Fax>
* </Customers>
* </Northwind>
*
* 上面定义的意义就是
* /Northwind/Customers路径所表示的一个Customers节点为一条数据,它包含的节点中的CustomerID...等等是需要获取的列值
*/
// 构造一个实际去取值的执行对象
return new XMLParseDemoDataModel(filePath,xpath, columns);
}
private int deep=0;
private static final int COL_DEEP=3;
private boolean flag=false;
private void readCol(XMLEventReader reader,List list)
throws XMLStreamException {
while (reader.hasNext()) {
XMLEvent event =reader.nextEvent();
if (event.isStartElement()) {
//deep是控制层数的,只把xml中对应的层的加入到列名中
deep++;
//表示已经进入到了列名那一层
if(deep==COL_DEEP){
flag=true;
}
//如果在高层,并且已经进入到了col层,则退出
if(deep<COL_DEEP&&flag){
return;
}
if(deep!=COL_DEEP){
continue;
}
// println("name: " +event.asStartElement().getName());
XMLColumnNameType4Democolumn=new XMLColumnNameType4Demo(event.asStartElement().getName().toString(),XMLParseDemoDataModel.COLUMN_TYPE_STRING);
list.add(column);
readCol(reader,list);
} else if (event.isCharacters()){
//对数据值不做处理
} else if (event.isEndElement()){
deep--;
return;
}
}
}
private void readCol0(XMLEventReader reader)
throws XMLStreamException {
while (reader.hasNext()) {
XMLEvent event = reader.nextEvent();
if (event.isStartElement()) {
//deep是控制层数的,只把xml中对应的层的加入到列名中
deep++;
//表示已经进入到了列名那一层
if(deep==COL_DEEP){
flag=true;
}
//如果在高层,并且已经进入到了col层,则退出
if(deep<COL_DEEP&&flag){
return;
}
if(deep!=COL_DEEP){
continue;
}
System.out.println("name:" + event.asStartElement().getName());
readCol0(reader);
} else if (event.isCharacters()){
//对数据值不做处理
} else if (event.isEndElement()){
deep--;
return;
}
}
}
public static void main(String[]args){
XMLInputFactory inputFactory =XMLInputFactory.newInstance();
// in = new FileReader(newFile(filePath));
// XMLEventReader reader = inputFactory.createXMLEventReader(in);
// readCol(reader,list);
BufferedInputStream in;
try {
in = new BufferedInputStream(newFileInputStream(new File("D:/tmp/f.xml")));
byte[] ba=new byte[3];
in.read(ba,0,3);
// System.out.println(in)
XMLEventReader reader =inputFactory.createXMLEventReader(in);
newXMLDemoTableData().readCol0(reader);
} catch (Exception e) {
// TODO Auto-generated catchblock
e.printStackTrace();
}
}
}
注:如果xml文件的格式上问题描述处所展示的xml格式不一致,则需要修改类中的deep变量,把列名所在的节点层数改成相对应的数值。
注:XMLDemoTableData里面的filename并不是文件名,而是xml里面某个标签名。4、编译程序数据源
分别编译XMLColumnNameType4Demo.java、XMLParseDemoDataModel.java、XMLDemoTableData.java三个类文件,将生成的class文件放于%FR_HOME%\WebReport\WEB-INF\classes\com\fr\data下。
5 配置程序数据源
新建报表,模板数据集>程序数据集,选择我们定义好的程序数据集XMLDemoTableData.class文件,名字可以自定义,如程序1。
6、使用程序数据源
在模板数据集窗口,点击预览按钮,弹出参数对话框,输入要显示的xml文件名称,点击确定则可以把Northwind.xml文件里面的数据读取出来转换报表数据源了,如下图:

相关文章推荐
- Java如何解析某个目录下xml文件,将XML文件转换为报表数据源?
- JAXB解析xml文件转换为Java对象
- java如何解析xml文件(上)
- 如何通过java代码解析xml文件
- 如何解析assets目录下的xml文件,,并展示
- Maven学习笔记二eclipse如何使用 Maven、Maven目录pom.xml文件的解析、maven 和maven项目之间的关系
- Java中如何解析XML文件
- 如何使用Java解析xml文件
- 在java项目中如何利用Dom4j解析XML文件获取数据
- SAX 解析XML文件:将XML转换成Java对象
- 主题:Java报表工具技巧:如何在报表软件Style Report中配置Oracle 10g数据源
- Java是如何解析xml文件的(DOM)
- 在VB .net环境下,如何读取XML文件源代码及解析
- [翻译]如何使用webservice作为数据源去生成Microsoft Reporting Services 2005的报表
- java对xml全面解析,增,删,改,以及将java对象重新编组为xml文件
- JAVA 程序中如何拷贝一个目录下的文件及子目录到另一个目录,如何获取系统环境变量等...
- [翻译]如何使用webservice作为数据源去生成Microsoft Reporting Services 2005的报表
- 如何在JasperReports中使用XML文件作为数据源?
- Java实现DOM文档操作和XML文件互相转换
- 如何向水晶报表数据源中的存储过程传参数……