【并行计算】用MPI进行分布式内存编程(二)
2016-10-09 20:59
531 查看
通过上一篇中,知道了基本的MPI编写并行程序,最后的例子中,让使用0号进程做全局的求和的所有工作,而其他的进程却都不工作,这种方式也许是某种特定情况下的方案,但明显不是最好的方案。举个例子,如果我们让偶数号的进程负责收集求和的工作,情况会怎么样?如下图:

对比之前的图发现,总的工作量与之前的一样,但是发现新方案中0号进程只做了3次接收和3次加法(之前的7次接收和7次加法),如果进程都是同时启动的,那么全局求和时间将是0号进程的接收时间和求和时间,即需要的总时间比原来方案的总时间减少了50%多。如果是进程数=1024的话,则原方案需要0号进程执行1023次接收和求和,而新方案只要0号进程10次接收和求和操作。这样的话就能将原方案的性能提高100倍!!既然改变进程之间的接收和发送方式能提高性能,这就涉及进程集合之间的集合通信了,而这些进程集合之间的通信,MPI都已经苦逼的程序员都封装好了,使得程序员能摆脱有无之境的程序优化,而将精力集中解决程序业务上面。首先还是将之前的求积分函数的例子改造一下:
注意在这段代码中,我们不再使用MPI_Send和MPI_Recv这样的通信函数,而是使用了一个MPI_Reduce函数,通过编译执行

同样能得到结果。各位看官不仅要问,代码中的MPI_Reduce函数是个什么东西呢?如何使用?要回答这些问题,就需要继续往下深入的学习集合通信的概念。
在MPI中,涉及所有的进程的通信函数我们称之为集合通信(collective communication)。而单个进程对单个进程的通信,类似于MPI_Send和MPI_Recv这样的通信函数,我们称之为点对点通信(point-to-point communication)。进程间的通信关系可以用如下图的关系来表示:

(1)1对1;
(2)1对部分
(3)1对全部
(4)部分对1
(5)部分对部分
(6)部分对全部
(7)全部对1
(8)全部对部分
(9)全部对全部
那既然区分了集合通信与点对点通信,它们之间的各自有什么不同呢?集合通信具有以下特点:
(1)、在通信子中的所有进程都必须调用相同的集合通信函数。
(2)、每个进程传递给MPI集合通信函数的参数必须是“相容的”。
(3)、点对点通信函数是通过标签和通信子来匹配的。而通信函数不实用标签,只是通过通信子和调用的顺序来进行匹配。
下表汇总了MPI中的集合通信函数:

数据归约的基本功能是从每个进程收集数据,把这些数据归约成单个值,把归约成的值存储到根进程中。具体例子类似于单科老师(数学老师)收试卷,每个学生都把考试完的数学试卷交给老师,由老师来进行操作(求最大值、求总和等)。如图所示:

MPI_Reduce函数:
在这个函数中,最关键的参数是第5个参数MPI_Op op,它表示MPI归于中的操作符,我们上面的例子就是用的求累加和的归约操作符。具体的归约操作符如下表:
除MPI_Reduce函数之外,数据归约还有如下一些变种函数:
MPI_Allreduce函数
此函数在得到归约结果值之后,将结果值分发给每一个进程,这样的话,并行中的所有进程值都能知道结果值了。类似的求和计算结果的发布图如下:

MPI_Reduce_scatter函数
归约散发。该函数的作用相当于首先进行一次归约操作,然后再对归约结果进行散发操作。
MPI_Scan函数
前缀归约(或扫描归约)。与普通全归约MPI_Allreduce类似,但各进程依次得到部分归约的结果。
在一个集合通信中,如果属于一个进程的数据被发送到通信子中的所有进程,这样的集合通信就叫做广播。如图所示:


MPI_Bcast函数:
通信器comm中进程号为root的进程(称为根进程) 将自己buffer中的内容发送给通信器中所有其他进程。参数buffer、count和datatype的含义与点对点通信函数(如MPI_Send和MPI_Recv)相同。
下面我们编写一个具体的例子:
结果为:

在进行数值计算软件开发的过程中,经常碰到两个向量的加法运算,例如每个向量有1万个分量,如果有10个进程,那么就可以简单的将local_n个向量分量所构成的块分配到每个进程中去,至于怎么分块,这里有一些方法(块划分法、循环划分法、块-循环划分法),这种将数据分块发送给各个进程进行并行计算的方法称之为散射。


MPI_Scatter函数:
散发相同长度数据块。根进程root将自己的sendbuf中的np个连续存放的数据块按进程号的顺序依次分发到comm的各个进程(包括根进程自己) 的recvbuf中,这里np代表comm中的进程数。sendcnt和sendtype 给出sendbuf中每个数据块的大小和类型,recvcnt和recvtype给出recvbuf的大小和类型,其中参数sendbuf、sendcnt 和sendtype仅对根进程有意义。需要特别注意的是,在根进程中,参数sendcnt指分别发送给每个进程的数据长度,而不是发送给所有进程的数据长度之和。因此,当recvtype等于sendtype时,recvcnt应该等于sendcnt。
MPI_Scatterv函数:
散发不同长度的数据块。与MPI_Scatter类似,但允许sendbuf中每个数据块的长度不同并且可以按任意的顺序排放。sendbuf、sendtype、sendcnts和displs仅对根进程有意义。数组sendcnts和displs的元素个数等于comm中的进程数,它们分别给出发送给每个进程的数据长度和位移,均以sendtype为单位。
下面我们来看一个例子:
其结果为:




MPI_Gather函数:
收集相同长度的数据块。以root为根进程,所有进程(包括根进程自己) 将sendbuf中的数据块发送给根进程,根进程将这些数据块按进程号的顺序依次放到recvbuf中。发送和接收的数据类型与长度必须相配,即发送和接收使用的数据类型必须具有相同的类型序列。参数recvbuf,recvcnt 和recvtype仅对根进程有意义。需要特别注意的是,在根进程中,参数recvcnt指分别从每个进程接收的数据长度,而不是从所有进程接收的数据长度之和。因此,当sendtype等于recvtype时,sendcnt应该等于recvcnt。
MPI_Allgather函数:
MPI_Allgather与MPI_Gather类似,区别是所有进程同时将数据收集到recvbuf中,因此称为数据全收集。MPI_Allgather相当于依次以comm中的每个进程为根进程调用普通数据收集函数MPI_Gather,或者以任一进程为根进程调用一次普通收集,紧接着再对收集到的数据进行一次广播。
MPI_Gatherv函数:
收集不同长度的数据块。与MPI_Gather类似,但允许每个进程发送的数据块长度不同,并且根进程可以任意排放数据块在recvbuf中的位置。recvbuf,recvtype,recvcnts和displs仅对根进程有意义。数组recvcnts和displs的元素个数等于进程数,用于指定从每个进程接收的数据块长度和它们在recvbuf中的位移,均以recvtype为单位。
MPI_Allgatherv函数:
不同长度数据块的全收集。参数与MPI_Gatherv类似。它等价于依次以comm中的每个进程为根进程调用MPI_Gatherv,或是以任一进程为根进程调用一次普通收集,紧接着再对收集到的数据进行一次广播。
例子:
结果为:


MPI_Alltoall函数:
相同长度数据块的全收集散发:进程i将sendbuf中的第j块数据发送到进程j的recvbuf中的第i个位置,i, j =0, . . . , np-1 (np代表comm 中的进程数)。sendbuf 和recvbuf 均由np个连续的数据块构成,每个数据块的长度/类型分别为sendcnt/sendtype和recvcnt/recvtype。该操作相当于将数据在进程间进行一次转置。例如,假设一个二维数组按行分块存储在各进程中,则调用该函数可很容易地将它变成按列分块存储在各进程中。
MPI_Alltoallv函数:
不同长度数据块的全收集散发。与MPI_Alltoall类似,但每个数据块的长度可以不等,并且不要求连续存放。各个参数的含义可参考函数MPI_Alltoall,MPI_Scatterv和MPI_Gatherv。
我们使得程序并行化,就是希望解决相同问题的时候,并行程序比串行程序运行的快一些,那如何去评判这个“快”呢?
假如有如下面这样一个矩阵-向量乘法程序

分别用不同的comm_sz运行,其计时结果如下:

从上表中可以看出,对于值很大的n来说,进程数加倍大约能减少一半的运行时间。然而,对于值很小的n,增大comm_sz获得的效果就不是很明显,例如:n=1024的时候,进程数从8增加到16后,运行时间没有出现变化。这种现象的原因是:并行程序还有进程之间通信会有额外的开销。一般定义并行程序的时间为:

当n值较小,p值较大时,公式中的T开销就起主导作用了。这里的T开销一般来之通信。
加速比:用来衡量串行运算和并行运算时间之间的关系,表示串行时间与并行时间的比值。

S(n,p)最理性的结果是p。S(n,p)=p,说明拥有p个进程的并行程序能运行的比串行程序快p倍。这种就成为线性加速比。但这种情况很少。
效率:它其实是“每个进程”的加速比。
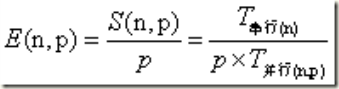
线性加速比相当于并行效率p/p=1,通常都比1小。
并行矩阵-向量乘法的加速比 并行矩阵-向量乘法的效率


最后强调:在p较小,n较大的情况下,有近似线性的效率,相反,在p较大而n较小的情况下,远远达不到线性效率。
至此,MPI的基本知识就这些了,具体就涉及到怎么将串行程序改变算法,改成并行的了。
MPI参考手册:链接:http://pan.baidu.com/s/1o8Op1Qa 密码:vubm

对比之前的图发现,总的工作量与之前的一样,但是发现新方案中0号进程只做了3次接收和3次加法(之前的7次接收和7次加法),如果进程都是同时启动的,那么全局求和时间将是0号进程的接收时间和求和时间,即需要的总时间比原来方案的总时间减少了50%多。如果是进程数=1024的话,则原方案需要0号进程执行1023次接收和求和,而新方案只要0号进程10次接收和求和操作。这样的话就能将原方案的性能提高100倍!!既然改变进程之间的接收和发送方式能提高性能,这就涉及进程集合之间的集合通信了,而这些进程集合之间的通信,MPI都已经苦逼的程序员都封装好了,使得程序员能摆脱有无之境的程序优化,而将精力集中解决程序业务上面。首先还是将之前的求积分函数的例子改造一下:
int main(int argc, char* argv[])
{
int my_rank = 0, comm_sz = 0, n = 1024, local_n = 0;
double a = 0.0, b = 3.0, h = 0, local_a = 0, local_b = 0;
double local_double = 0, total_int = 0;
int source;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
h = (b - a) / n; /* h is the same for all processes */
local_n = n / comm_sz; /* So is the number of trapezoids */
local_a = a + my_rank*local_n*h;
local_b = local_a + local_n*h;
local_double = Trap(local_a, local_b, local_n, h);
MPI_Reduce(&local_double, &total_int, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (my_rank == 0)
{
printf("With n = %d trapezoids, our estimate\n", n);
printf("of the integral from %f to %f = %.15e\n", a, b, total_int);
}
MPI_Finalize();
return 0;
}注意在这段代码中,我们不再使用MPI_Send和MPI_Recv这样的通信函数,而是使用了一个MPI_Reduce函数,通过编译执行

同样能得到结果。各位看官不仅要问,代码中的MPI_Reduce函数是个什么东西呢?如何使用?要回答这些问题,就需要继续往下深入的学习集合通信的概念。
1.集合通讯
在MPI中,涉及所有的进程的通信函数我们称之为集合通信(collective communication)。而单个进程对单个进程的通信,类似于MPI_Send和MPI_Recv这样的通信函数,我们称之为点对点通信(point-to-point communication)。进程间的通信关系可以用如下图的关系来表示:
(1)1对1;
(2)1对部分
(3)1对全部
(4)部分对1
(5)部分对部分
(6)部分对全部
(7)全部对1
(8)全部对部分
(9)全部对全部
那既然区分了集合通信与点对点通信,它们之间的各自有什么不同呢?集合通信具有以下特点:
(1)、在通信子中的所有进程都必须调用相同的集合通信函数。
(2)、每个进程传递给MPI集合通信函数的参数必须是“相容的”。
(3)、点对点通信函数是通过标签和通信子来匹配的。而通信函数不实用标签,只是通过通信子和调用的顺序来进行匹配。
下表汇总了MPI中的集合通信函数:

1.1 归约
数据归约的基本功能是从每个进程收集数据,把这些数据归约成单个值,把归约成的值存储到根进程中。具体例子类似于单科老师(数学老师)收试卷,每个学生都把考试完的数学试卷交给老师,由老师来进行操作(求最大值、求总和等)。如图所示:
MPI_Reduce函数:
int MPI_Reduce (void *sendbuf, void *recvbuf, int count,MPI_Datatype datatype, MPI_Op op, int root,MPI_Comm comm)
在这个函数中,最关键的参数是第5个参数MPI_Op op,它表示MPI归于中的操作符,我们上面的例子就是用的求累加和的归约操作符。具体的归约操作符如下表:
| 运算操作符 | 描述 | 运算操作符 | 描述 |
| MPI_MAX | 最大值 | MPI_LOR | 逻辑或 |
| MPI_MIN | 最小值 | MPI_BOR | 位或 |
| MPI_SUM | 求和 | MPI_LXOR | 逻辑异或 |
| MPI_PROD | 求积 | MPI_BXOR | 位异或 |
| MPI_LAND | 逻辑与 | MPI_MINLOC | 计算一个全局最小值和附到这个最小值上的索引--可以用来决定包含最小值的进程的秩 |
| MPI_BAND | 位与 | MPI_MAXLOC | 计算一个全局最大值和附到这个最大值上的索引--可以用来决定包含最小值的进程的秩 |
MPI_Allreduce函数
int MPI_Allreduce (void *sendbuf, void *recvbuf, int count,MPI_Datatype datatype, MPI_Op op,MPI_Comm comm)
此函数在得到归约结果值之后,将结果值分发给每一个进程,这样的话,并行中的所有进程值都能知道结果值了。类似的求和计算结果的发布图如下:
MPI_Reduce_scatter函数
int MPI_Reduce_scatter (void *sendbuf, void *recvbuf,int *recvcnts,MPI_Datatype datatype, MPI_Op op,MPI_Comm comm)
归约散发。该函数的作用相当于首先进行一次归约操作,然后再对归约结果进行散发操作。
MPI_Scan函数
int MPI_Scan (void *sendbuf, void *recvbuf, int count,MPI_Datatype datatype, MPI_Op op,MPI_Comm comm)
前缀归约(或扫描归约)。与普通全归约MPI_Allreduce类似,但各进程依次得到部分归约的结果。
1.2 数据移动-广播
在一个集合通信中,如果属于一个进程的数据被发送到通信子中的所有进程,这样的集合通信就叫做广播。如图所示:

MPI_Bcast函数:
int MPI_Bcast (void *buffer, int count,MPI_Datatype datatype, int root,MPI_Comm comm)
通信器comm中进程号为root的进程(称为根进程) 将自己buffer中的内容发送给通信器中所有其他进程。参数buffer、count和datatype的含义与点对点通信函数(如MPI_Send和MPI_Recv)相同。
下面我们编写一个具体的例子:
void blog3::TestForMPI_Bcast(int argc, char* argv[])
{
int rankID, totalNumTasks;
MPI_Init(&argc, &argv);
MPI_Barrier(MPI_COMM_WORLD);
double elapsed_time = -MPI_Wtime();
MPI_Comm_rank(MPI_COMM_WORLD, &rankID);
MPI_Comm_size(MPI_COMM_WORLD, &totalNumTasks);
int sendRecvBuf[3] = { 0, 0, 0 };
if (!rankID) {
sendRecvBuf[0] = 3;
sendRecvBuf[1] = 6;
sendRecvBuf[2] = 9;
}
int count = 3;
int root = 0;
MPI_Bcast(sendRecvBuf, count, MPI_INT, root, MPI_COMM_WORLD); //MPI_Bcast can be seen from all processes
printf("my rankID = %d, sendRecvBuf = {%d, %d, %d}\n", rankID, sendRecvBuf[0], sendRecvBuf[1], sendRecvBuf[2]);
elapsed_time += MPI_Wtime();
if (!rankID) {
printf("total elapsed time = %10.6f\n", elapsed_time);
}
MPI_Finalize();
}
int main(int argc, char* argv[])
{
blog3 test;
test.TestForMPI_Bcast(argc, argv);
}结果为:

1.3 数据移动-散射
在进行数值计算软件开发的过程中,经常碰到两个向量的加法运算,例如每个向量有1万个分量,如果有10个进程,那么就可以简单的将local_n个向量分量所构成的块分配到每个进程中去,至于怎么分块,这里有一些方法(块划分法、循环划分法、块-循环划分法),这种将数据分块发送给各个进程进行并行计算的方法称之为散射。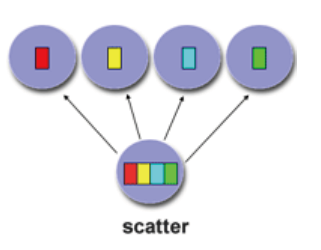

MPI_Scatter函数:
int MPI_Scatter (void *sendbuf, int sendcnt,MPI_Datatype sendtype, void *recvbuf,int recvcnt, MPI_Datatype recvtype,int root, MPI_Comm comm)
散发相同长度数据块。根进程root将自己的sendbuf中的np个连续存放的数据块按进程号的顺序依次分发到comm的各个进程(包括根进程自己) 的recvbuf中,这里np代表comm中的进程数。sendcnt和sendtype 给出sendbuf中每个数据块的大小和类型,recvcnt和recvtype给出recvbuf的大小和类型,其中参数sendbuf、sendcnt 和sendtype仅对根进程有意义。需要特别注意的是,在根进程中,参数sendcnt指分别发送给每个进程的数据长度,而不是发送给所有进程的数据长度之和。因此,当recvtype等于sendtype时,recvcnt应该等于sendcnt。
MPI_Scatterv函数:
int MPI_Scatterv (void *sendbuf, int *sendcnts,int *displs, MPI_Datatype sendtype,void *recvbuf, int recvcnt,MPI_Datatype recvtype, int root,MPI_Comm comm)
散发不同长度的数据块。与MPI_Scatter类似,但允许sendbuf中每个数据块的长度不同并且可以按任意的顺序排放。sendbuf、sendtype、sendcnts和displs仅对根进程有意义。数组sendcnts和displs的元素个数等于comm中的进程数,它们分别给出发送给每个进程的数据长度和位移,均以sendtype为单位。
下面我们来看一个例子:
void blog3::TestForMPI_Scatter(int argc, char* argv[])
{
int totalNumTasks, rankID;
float sendBuf[SIZE][SIZE] = {
{ 1.0, 2.0, 3.0, 4.0 },
{ 5.0, 6.0, 7.0, 8.0 },
{ 9.0, 10.0, 11.0, 12.0 },
{ 13.0, 14.0, 15.0, 16.0 }
};
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rankID);
MPI_Comm_size(MPI_COMM_WORLD, &totalNumTasks);
if (totalNumTasks == SIZE) {
int source = 0;
int sendCount = SIZE;
int recvCount = SIZE;
float recvBuf[SIZE];
//scatter data from source process to all processes in MPI_COMM_WORLD
MPI_Scatter(sendBuf, sendCount, MPI_FLOAT,
recvBuf, recvCount, MPI_FLOAT, source, MPI_COMM_WORLD);
printf("my rankID = %d, receive Results: %f %f %f %f, total = %f\n",
rankID, recvBuf[0], recvBuf[1], recvBuf[2], recvBuf[3],
recvBuf[0] + recvBuf[1] + recvBuf[2] + recvBuf[3]);
}
else if (totalNumTasks == 8) {
int source = 0;
int sendCount = 2;
int recvCount = 2;
float recvBuf[2];
MPI_Scatter(sendBuf, sendCount, MPI_FLOAT,
recvBuf, recvCount, MPI_FLOAT, source, MPI_COMM_WORLD);
printf("my rankID = %d, receive result: %f %f, total = %f\n",
rankID, recvBuf[0], recvBuf[1], recvBuf[0] + recvBuf[1]);
}
else {
printf("Please specify -n %d or -n %d\n", SIZE, 2 * SIZE);
}
MPI_Finalize();
}
int main(int argc, char* argv[])
{
blog3 test;
test.TestForMPI_Scatter(argc, argv);
return 0;
}其结果为:

1.4 数据移动-聚集


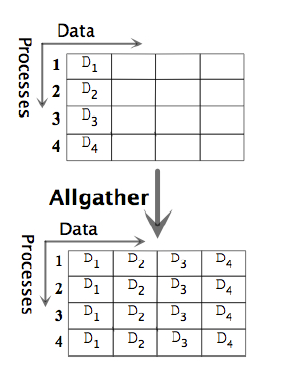
MPI_Gather函数:
int MPI_Gather (void *sendbuf, int sendcnt,MPI_Datatype sendtype, void *recvbuf,int recvcnt, MPI_Datatype recvtype,int root, MPI_Comm comm)
收集相同长度的数据块。以root为根进程,所有进程(包括根进程自己) 将sendbuf中的数据块发送给根进程,根进程将这些数据块按进程号的顺序依次放到recvbuf中。发送和接收的数据类型与长度必须相配,即发送和接收使用的数据类型必须具有相同的类型序列。参数recvbuf,recvcnt 和recvtype仅对根进程有意义。需要特别注意的是,在根进程中,参数recvcnt指分别从每个进程接收的数据长度,而不是从所有进程接收的数据长度之和。因此,当sendtype等于recvtype时,sendcnt应该等于recvcnt。
MPI_Allgather函数:
int MPI_Allgather (void *sendbuf, int sendcnt,MPI_Datatype sendtype, void *recvbuf,int recvcnt, MPI_Datatype recvtype,MPI_Comm comm)
MPI_Allgather与MPI_Gather类似,区别是所有进程同时将数据收集到recvbuf中,因此称为数据全收集。MPI_Allgather相当于依次以comm中的每个进程为根进程调用普通数据收集函数MPI_Gather,或者以任一进程为根进程调用一次普通收集,紧接着再对收集到的数据进行一次广播。
MPI_Gatherv函数:
int MPI_Gatherv (void *sendbuf, int sendcnt,MPI_Datatype sendtype, void *recvbuf,int *recvcnts, int *displs,MPI_Datatype recvtype, int root,MPI_Comm comm)
收集不同长度的数据块。与MPI_Gather类似,但允许每个进程发送的数据块长度不同,并且根进程可以任意排放数据块在recvbuf中的位置。recvbuf,recvtype,recvcnts和displs仅对根进程有意义。数组recvcnts和displs的元素个数等于进程数,用于指定从每个进程接收的数据块长度和它们在recvbuf中的位移,均以recvtype为单位。
MPI_Allgatherv函数:
int MPI_Allgatherv (void *sendbuf, int sendcnt,MPI_Datatype sendtype, void *recvbuf,int *recvcnts, int *displs,MPI_Datatype recvtype, MPI_Comm comm)
不同长度数据块的全收集。参数与MPI_Gatherv类似。它等价于依次以comm中的每个进程为根进程调用MPI_Gatherv,或是以任一进程为根进程调用一次普通收集,紧接着再对收集到的数据进行一次广播。
例子:
void blog3::TestForMPI_Gather(int argc, char* argv[])
{
int rankID, totalNumTasks;
MPI_Init(&argc, &argv);
MPI_Barrier(MPI_COMM_WORLD);
double elapsed_time = -MPI_Wtime();
MPI_Comm_rank(MPI_COMM_WORLD, &rankID);
MPI_Comm_size(MPI_COMM_WORLD, &totalNumTasks);
int* gatherBuf = (int *)malloc(sizeof(int) * totalNumTasks);
if (gatherBuf == NULL) {
printf("malloc error!");
exit(-1);
MPI_Finalize();
}
int sendBuf = rankID; //for each process, its rankID will be sent out
int sendCount = 1;
int recvCount = 1;
int root = 0;
MPI_Gather(&sendBuf, sendCount, MPI_INT, gatherBuf, recvCount, MPI_INT, root, MPI_COMM_WORLD);
elapsed_time += MPI_Wtime();
if (!rankID) {
int i;
for (i = 0; i < totalNumTasks; i++) {
printf("gatherBuf[%d] = %d, ", i, gatherBuf[i]);
}
putchar('\n');
printf("total elapsed time = %10.6f\n", elapsed_time);
}
MPI_Finalize();
}
int main(int argc, char* argv[])
{
blog3 test;
test.TestForMPI_Gather(argc, argv);
return 0;
}结果为:

1.5 数据移动-其它

MPI_Alltoall函数:
int MPI_Alltoall (void *sendbuf, int sendcnt,MPI_Datatype sendtype, void *recvbuf,int recvcnt, MPI_Datatype recvtype,MPI_Comm comm)
相同长度数据块的全收集散发:进程i将sendbuf中的第j块数据发送到进程j的recvbuf中的第i个位置,i, j =0, . . . , np-1 (np代表comm 中的进程数)。sendbuf 和recvbuf 均由np个连续的数据块构成,每个数据块的长度/类型分别为sendcnt/sendtype和recvcnt/recvtype。该操作相当于将数据在进程间进行一次转置。例如,假设一个二维数组按行分块存储在各进程中,则调用该函数可很容易地将它变成按列分块存储在各进程中。
MPI_Alltoallv函数:
int MPI_Alltoallv (void *sendbuf, int *sendcnts,int *sdispls, MPI_Datatype sendtype,void *recvbuf, int *recvcnts,int *rdispls, MPI_Datatype recvtype,MPI_Comm comm)
不同长度数据块的全收集散发。与MPI_Alltoall类似,但每个数据块的长度可以不等,并且不要求连续存放。各个参数的含义可参考函数MPI_Alltoall,MPI_Scatterv和MPI_Gatherv。
2.MPI程序的性能评估
我们使得程序并行化,就是希望解决相同问题的时候,并行程序比串行程序运行的快一些,那如何去评判这个“快”呢?假如有如下面这样一个矩阵-向量乘法程序
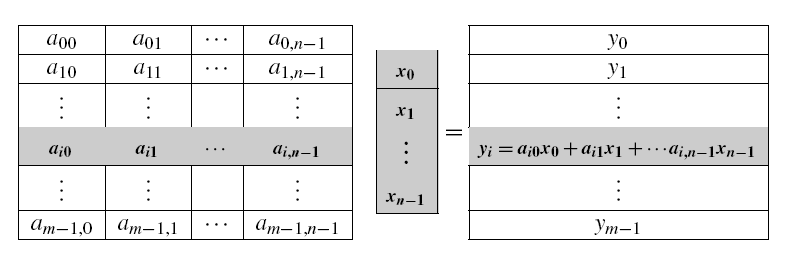
分别用不同的comm_sz运行,其计时结果如下:

从上表中可以看出,对于值很大的n来说,进程数加倍大约能减少一半的运行时间。然而,对于值很小的n,增大comm_sz获得的效果就不是很明显,例如:n=1024的时候,进程数从8增加到16后,运行时间没有出现变化。这种现象的原因是:并行程序还有进程之间通信会有额外的开销。一般定义并行程序的时间为:

当n值较小,p值较大时,公式中的T开销就起主导作用了。这里的T开销一般来之通信。
加速比:用来衡量串行运算和并行运算时间之间的关系,表示串行时间与并行时间的比值。

S(n,p)最理性的结果是p。S(n,p)=p,说明拥有p个进程的并行程序能运行的比串行程序快p倍。这种就成为线性加速比。但这种情况很少。
效率:它其实是“每个进程”的加速比。

线性加速比相当于并行效率p/p=1,通常都比1小。
并行矩阵-向量乘法的加速比 并行矩阵-向量乘法的效率


最后强调:在p较小,n较大的情况下,有近似线性的效率,相反,在p较大而n较小的情况下,远远达不到线性效率。
至此,MPI的基本知识就这些了,具体就涉及到怎么将串行程序改变算法,改成并行的了。
MPI参考手册:链接:http://pan.baidu.com/s/1o8Op1Qa 密码:vubm

相关文章推荐
- 【并行计算】用MPI进行分布式内存编程(一)
- 用MPI进行分布式内存编程(二)MPI_allreduce MPI_scatt MPI_bcast.....
- 漫谈并发编程:用MPI进行分布式内存编程(入门篇)
- 用 Hadoop 进行分布式并行编程, 第 1 部分
- 用 Hadoop 进行分布式并行编程, 第 3 部分
- 用 Hadoop 进行分布式并行编程, 第 2 部分
- 用 Hadoop 进行分布式并行编程, 第 1 部分
- 并行计算的内存模型和编程模型
- 用 Hadoop 进行分布式并行编程, 第 1 部分
- 用 Hadoop 进行分布式并行编程, 第 2 部分
- MPI实现fft的迭代算法 源于并行计算——结构。算法。编程中伪码
- 用 Hadoop 进行分布式并行编程, 第 3 部分
- 用 Hadoop 进行分布式并行编程, 第 1 部分
- 【转】用 Hadoop 进行分布式并行编程, 第 2 部分
- 用 Hadoop 进行分布式并行编程, 第 2 部分
- 用 Hadoop 进行分布式并行编程, 第 3 部分
- 用 Hadoop 进行分布式并行编程, 第 2 部分
- 【转】用Hadoop 进行分布式并行编程, 第 1 部分
- 用 Hadoop 进行分布式并行编程, 第 1 部分
- 用 Hadoop 进行分布式并行编程, 第 1 部分