redis 学习笔记(6)-cluster集群搭建
2016-10-08 18:32
756 查看
上次写redis的学习笔记还是2014年,一转眼已经快2年过去了,在段时间里,redis最大的变化之一就是cluster功能的正式发布,以前要搞redis集群,得借助一致性hash来自己搞sharding,现在方便多了,直接上cluster功能就行了,而且还支持节点动态添加、HA、节点增减后缓存重新分布(resharding)。
下面是参考官方教程cluster-tutorial 在mac机上搭建cluster的过程:
一、下载最新版redis 编译
目前最新版是3.0.7,下载地址:http://www.redis.io/download
编译很简单,一个make命令即可,不清楚的同学,可参考我之前的笔记: redis
学习笔记(1)-编译、启动、停止
二、建6个目录
注:与大多数分布式中间件一样,redis的cluster也是依赖选举算法来保证集群的高可用,所以类似ZK一样,一般是奇数个节点(可以允许N/2以下的节点失效),再考虑到每个节点做Master-Slave互为备份,所以一个redis cluster集群最少也得6个节点。
然后把步骤1里编译好的redis,复制到这6个目录下。
三、配置文件
把上面这段保存成redis-cluster.conf,放到每个目录的redis目录中,注意修改port端口,即7000目录下的port为7000,7001目录下的port为7001...
cluster-node-timeout 是集群中各节点相互通讯时,允许"失联"的最大毫秒数,上面的配置为5秒,如果超过5秒某个节点没向其它节点汇报成功,认为该节点挂了。
四、依次启动各个redis
在每个目录redis的src子目录下,输入:
这样7000~7005这6个节点就启动了。
五、安装redis的ruby模块
解释:虽然步骤4把6个redis server启动成功了,但是彼此之间是完全独立的,需要借助其它工具将其加入cluster,而这个工具就是redis提供的一个名为redis-trib.rb的ruby脚本(个人估计redis的作者比较偏爱ruby),mac自带了ruby2.0环境,但是没有redis模块,所以要安装这玩意儿,否则接下来的创建cluster将失败。
六、创建cluster
仍然保持在某个目录的src子目录下,运行上面这段shell脚本,cluster就创建成功了,replicas 1的意思,就是每个节点创建1个副本(即:slave),所以最终的结果,就是后面的127.0.0.1:7000~127.0.0.1:7005中,会有3个会指定成master,而其它3个会指定成slave。
注:利用redis-trib创建cluster的操作,只需要一次即可,假设系统关机,把所有6个节点全关闭后,下次重启后,即自动进入cluster模式,不用再次redis-trib.rb create。
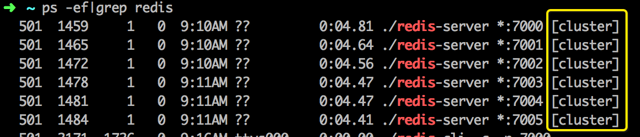
此时,如何用ps查看redis进程,会看到每个进程后附带了cluster的字样
如果想知道,哪些端口的节点是master,哪些端口的节点是slave,可以用下面的命令:
输出结果如下:
从上面的输出,可以看出7000、7004、7005是slave,而7001、7003、7002是master(如果大家人为做过一些failover的测试,比如把某个节点手动停掉,再恢复,输出的结果可能与上面不太一样),除了check参数,还有一个常用的参数info
输出结果如下:
它会把所有的master信息输出,包括这个master上有几个缓存key,有几个slave,所有master上的keys合计,以及平均每个slot上有多少key,想了解更多redis-trib脚本的其它参数,可以用
输出如下:
上面已经多次出现了slot这个词,略为解释一下:
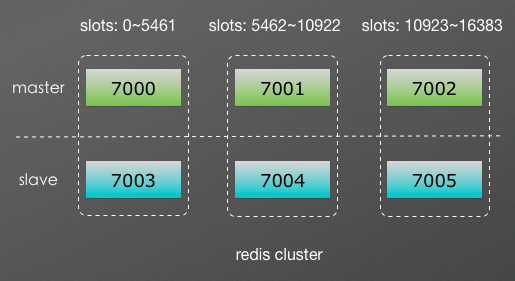
如上图,redis-cluster把整个集群的存储空间划分为16384个slot(译为:插槽?),当6个节点分为3主3从时,相当于整个cluster中有3组HA的节点,3个master会平均分摊所有slot,每次向cluster中的key做操作时(比如:读取/写入缓存),redis会对key值做CRC32算法处理,得到一个数值,然后再对16384取模,通过余数判断该缓存项应该落在哪个slot上,确定了slot,也就确定了保存在哪个master节点上,当cluster扩容或删除节点时,只需要将slot重新分配即可(即:把部分slot从一些节点移动到其它节点)。
七、redis-cli客户端操作
注意加参数-c,表示进入cluster模式,随便添加一个缓存试试:
注意第2行的输出,表示user1这个缓存通过计算后,落在8106这个slot上,最终定位在7001这个端口对应的节点上(解释:因为7000是slave,7001才是master,只有master才能写入),如果是在7001上重复上面的操作时,不会出现第2行(解释:7001是master,所以不存在redirect的过程)
八、FailOver测试
先用redis-trib.rb 查看下当前的主、从情况
从输出上看7000是7003(38910c5baafea02c5303505acfd9bd331c608cfc)的slave,现在我们人工把7003的redis进程给kill掉,然后观察7000的终端输出:
注意5,6,11这几行,第5行表明由于7003宕机,cluster状态已经切换到fail状态,第6行表示发起选举,第11行表示7000端口对应的节点当选为new master。
九、cluster 扩容
业务规模变大后,集群扩容是早晚的事情,下面演示如何再添加2个节点,先把7000复制二份,变成7006,7007,然后进入7006/7007目录redis的src子目录下
由于7000我们刚才启动过,里面有已经有一些数据了,所以要把数据文件,日志文件,以及cluster的nodes.conf文件删除,变成一个空的redis独立节点,否则无法加入cluster。
然后修改redis-cluster.conf
要修改的地方有二处,1是第一行的端口,改成与7006/7007匹配的端口,2是最后2行,这是7000运行后,自动添加的,把最后二行删除。
做完这些后,启动7006,7007这二个redis节点,此时这2个新节点与cluster没有任何关系,可以用下面的命令将7006做为master添加到cluster中。
注:第1个参数为新节点的"IP:端口",第2个参数为集群中的任一有效的节点。
顺利的话,输出如下:
可以再用check确认下状态:
12-14行说明7006已经是cluster的新master了,继续,用下面的命令把7007当成slave加入:
这里多出了二个参数:--slave 表示准备将新节点当成slave加入,--master-id xxxxx 则是指定要当谁的slave,后面的xxx部分,即为前面check的输出结果中,7006的ID,完事之后,可以再次确认状态:
观察6-8行、15-17行,说明7007已经是7006的slave。
十、reshard 重新划分slot
增加新的节点之后,问题就来了,16384个slot已经被其它3组节点分完了,新节点没有slot,没办法存放缓存,所以需要将slot重新分布。
用下面的命令可以重新分配slot
reshard后面的IP:port,只要是在cluster中的有效节点即可。
注:第一个交互询问,填写多少slot移动时,要好好想想,如果填成16384,则将所有slot都移动到一个固定节点上,会导致更加不均衡!建议每次移动500~1000,这样对线上的影响比较小。
另外在填写source node时,除了all之外,还可以直接填写源节点的id,即:
reshard可以多次操作,直到达到期望的分布为止(注:个人觉得redis的reshard这里有点麻烦,要移动多少slot需要人工计算,如果能提供一个参数之类,让16384个slot自动平均分配就好了),调整完成后,可以再看看分布情况:
十一、删除节点del-node
既然有扩容,就会有反向需求,某些节点不再需要时,可以用del-node删除,比如刚才我一阵乱倒腾后,发现7006已经有4个slave了,而其它master一个slave都没有,这明显不合理。
删除节点命令:
del-node后面的ip:port只要是cluster中有效节点即可,最后一个参数为目标节点的id,注意:只有slave节点和空的master节点可以删除,如果master非空,先用reshard把上面的slot移动到其它node后再删除,如果有一组master-slave节点,将master上所有slot移到其它节点,然后将master删除,剩下的slave会另寻他主,变成其它master的slave。
另外:删除节点的含义,不仅仅是从cluster中将这个节点移除,还会直接将目标节点的redis服务停止。
参考文章:
http://www.redis.io/topics/cluster-tutorial
下面是参考官方教程cluster-tutorial 在mac机上搭建cluster的过程:
一、下载最新版redis 编译
目前最新版是3.0.7,下载地址:http://www.redis.io/download
编译很简单,一个make命令即可,不清楚的同学,可参考我之前的笔记: redis
学习笔记(1)-编译、启动、停止
二、建6个目录
然后把步骤1里编译好的redis,复制到这6个目录下。
三、配置文件
cluster-node-timeout 是集群中各节点相互通讯时,允许"失联"的最大毫秒数,上面的配置为5秒,如果超过5秒某个节点没向其它节点汇报成功,认为该节点挂了。
四、依次启动各个redis
在每个目录redis的src子目录下,输入:
五、安装redis的ruby模块
六、创建cluster
注:利用redis-trib创建cluster的操作,只需要一次即可,假设系统关机,把所有6个节点全关闭后,下次重启后,即自动进入cluster模式,不用再次redis-trib.rb create。
此时,如何用ps查看redis进程,会看到每个进程后附带了cluster的字样
如果想知道,哪些端口的节点是master,哪些端口的节点是slave,可以用下面的命令:
如上图,redis-cluster把整个集群的存储空间划分为16384个slot(译为:插槽?),当6个节点分为3主3从时,相当于整个cluster中有3组HA的节点,3个master会平均分摊所有slot,每次向cluster中的key做操作时(比如:读取/写入缓存),redis会对key值做CRC32算法处理,得到一个数值,然后再对16384取模,通过余数判断该缓存项应该落在哪个slot上,确定了slot,也就确定了保存在哪个master节点上,当cluster扩容或删除节点时,只需要将slot重新分配即可(即:把部分slot从一些节点移动到其它节点)。
七、redis-cli客户端操作
先用redis-trib.rb 查看下当前的主、从情况
九、cluster 扩容
业务规模变大后,集群扩容是早晚的事情,下面演示如何再添加2个节点,先把7000复制二份,变成7006,7007,然后进入7006/7007目录redis的src子目录下
然后修改redis-cluster.conf
做完这些后,启动7006,7007这二个redis节点,此时这2个新节点与cluster没有任何关系,可以用下面的命令将7006做为master添加到cluster中。
顺利的话,输出如下:
十、reshard 重新划分slot
增加新的节点之后,问题就来了,16384个slot已经被其它3组节点分完了,新节点没有slot,没办法存放缓存,所以需要将slot重新分布。
另外在填写source node时,除了all之外,还可以直接填写源节点的id,即:
既然有扩容,就会有反向需求,某些节点不再需要时,可以用del-node删除,比如刚才我一阵乱倒腾后,发现7006已经有4个slave了,而其它master一个slave都没有,这明显不合理。
删除节点命令:
另外:删除节点的含义,不仅仅是从cluster中将这个节点移除,还会直接将目标节点的redis服务停止。
参考文章:
http://www.redis.io/topics/cluster-tutorial

相关文章推荐
- Redis学习笔记六——搭建redis集群(非分布式真正的cluster)
- redis 学习笔记(6)-cluster集群搭建
- redis学习笔记(二)JedisCluster + redis 3.2.5集群
- Redis 学习笔记(十五)Redis Cluster 集群扩容与收缩
- redis 学习笔记之集群搭建
- Redis 学习笔记4: Redis 3.2.1 集群搭建
- redis 学习笔记之集群搭建
- redis 学习笔记之集群搭建
- Redis 学习笔记(十五)Redis Cluster 集群扩容与收缩
- Redis 学习笔记(十五)Redis Cluster 集群扩容与收缩
- redis 学习笔记之集群搭建
- redis 学习笔记之集群搭建
- redis 学习笔记之集群搭建
- Redis 学习笔记4: Redis 3.2.1 集群搭建
- Redis 学习笔记4: Redis 3.2.1 集群搭建
- Redis 学习笔记(十四)Redis Cluster介绍与搭建
- Redis 学习笔记4: Redis 3.2.1 集群搭建
- Redis 学习笔记(十四)Redis Cluster介绍与搭建
- Kubernetes--学习笔记-4-Kubernetes 集群搭建过程中常用命令
- 7.mysql学习笔记:mysql集群的搭建(一)