Openvswitch原理与代码分析(5): 内核中的流表flow table操作
2016-09-19 22:22
585 查看
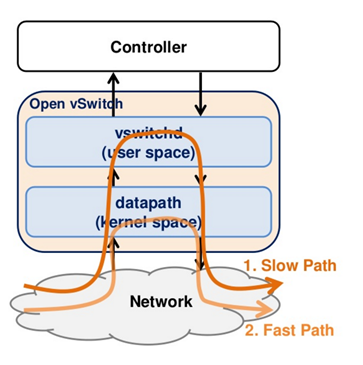
当一个数据包到达网卡的时候,首先要经过内核Openvswitch.ko,流表Flow Table在内核中有一份,通过key查找内核中的flow table,即可以得到action,然后执行action之后,直接发送这个包,只有在内核无法查找到流表项的时候,才会到用户态查找用户态的流表。仅仅查找内核中flow table的情况被称为fast path.
实现函数为int ovs_flow_key_extract(const struct ip_tunnel_info *tun_info, struct sk_buff *skb, struct sw_flow_key *key)
在这个函数中,首先提取的是物理层的信息,主要是从哪个网口进入的。
然后调用函数static int key_extract(struct sk_buff *skb, struct sw_flow_key *key)提取其他的key
提取MAC层
提取网络层
提取传输层
调用struct sw_flow *ovs_flow_tbl_lookup_stats(struct flow_table *tbl, const struct sw_flow_key *key, u32 skb_hash, u32 *n_mask_hit)进行查找。
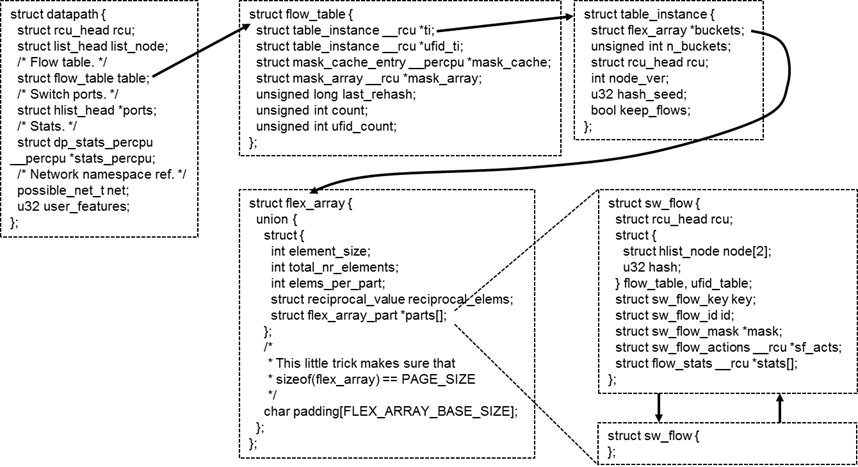
在内核中,flow table的数据结构如上图所示。
每个虚拟交换机对应一个datapath,每个datapath有一个flow table,每个flow table分成N个桶,根据key进行哈希,不同的key分布在不同的桶里面。
每个桶的大小是一个内存页的大小,在内存页的头部保存了保存了多少个元素,每个元素的大小。每个元素都是sw_flow,里面有key,也有action。
ovs_flow_tbl_lookup_stats会调用static struct sw_flow *flow_lookup(struct flow_table *tbl, struct table_instance *ti, const struct mask_array *ma, const struct sw_flow_key *key, u32 *n_mask_hit, u32 *index)
会调用masked_flow_lookup如下
其中flow_hash计算哈希值,find_bucket根据哈希值查找桶,然后就是一个循环,逐个比较key是否相等,相等则返回flow。
调用int ovs_execute_actions(struct datapath *dp, struct sk_buff *skb, const struct sw_flow_actions *acts,struct sw_flow_key *key)
调用static int do_execute_actions(struct datapath *dp, struct sk_buff *skb, struct sw_flow_key *key, const struct nlattr *attr, int len)
在这个函数中,通过case语句,不同的action进行不同的操作。
如果可以直接输出,则调用static void do_output(struct datapath *dp, struct sk_buff *skb, int out_port, struct sw_flow_key *key)他调用void ovs_vport_send(struct vport *vport, struct sk_buff *skb)进行发送。
第一步:从数据包中提取出key
实现函数为int ovs_flow_key_extract(const struct ip_tunnel_info *tun_info, struct sk_buff *skb, struct sw_flow_key *key)
在这个函数中,首先提取的是物理层的信息,主要是从哪个网口进入的。
| key->phy.priority = skb->priority; key->phy.in_port = OVS_CB(skb)->input_vport->port_no; key->phy.skb_mark = skb->mark; ovs_ct_fill_key(skb, key); key->ovs_flow_hash = 0; key->recirc_id = 0; |
然后调用函数static int key_extract(struct sk_buff *skb, struct sw_flow_key *key)提取其他的key
提取MAC层
| /* Link layer. We are guaranteed to have at least the 14 byte Ethernet * header in the linear data area. */ eth = eth_hdr(skb); ether_addr_copy(key->eth.src, eth->h_source); ether_addr_copy(key->eth.dst, eth->h_dest); __skb_pull(skb, 2 * ETH_ALEN); /* We are going to push all headers that we pull, so no need to * update skb->csum here. */ key->eth.tci = 0; if (skb_vlan_tag_present(skb)) key->eth.tci = htons(vlan_get_tci(skb)); else if (eth->h_proto == htons(ETH_P_8021Q)) if (unlikely(parse_vlan(skb, key))) return -ENOMEM; key->eth.type = parse_ethertype(skb); |
提取网络层
| struct iphdr *nh; __be16 offset; error = check_iphdr(skb); if (unlikely(error)) { memset(&key->ip, 0, sizeof(key->ip)); memset(&key->ipv4, 0, sizeof(key->ipv4)); if (error == -EINVAL) { skb->transport_header = skb->network_header; error = 0; } return error; } nh = ip_hdr(skb); key->ipv4.addr.src = nh->saddr; key->ipv4.addr.dst = nh->daddr; key->ip.proto = nh->protocol; key->ip.tos = nh->tos; key->ip.ttl = nh->ttl; offset = nh->frag_off & htons(IP_OFFSET); if (offset) { key->ip.frag = OVS_FRAG_TYPE_LATER; return 0; } if (nh->frag_off & htons(IP_MF) || skb_shinfo(skb)->gso_type & SKB_GSO_UDP) key->ip.frag = OVS_FRAG_TYPE_FIRST; else key->ip.frag = OVS_FRAG_TYPE_NONE; |
提取传输层
| /* Transport layer. */ if (key->ip.proto == IPPROTO_TCP) { if (tcphdr_ok(skb)) { struct tcphdr *tcp = tcp_hdr(skb); key->tp.src = tcp->source; key->tp.dst = tcp->dest; key->tp.flags = TCP_FLAGS_BE16(tcp); } else { memset(&key->tp, 0, sizeof(key->tp)); } } else if (key->ip.proto == IPPROTO_UDP) { if (udphdr_ok(skb)) { struct udphdr *udp = udp_hdr(skb); key->tp.src = udp->source; key->tp.dst = udp->dest; } else { memset(&key->tp, 0, sizeof(key->tp)); } } else if (key->ip.proto == IPPROTO_SCTP) { if (sctphdr_ok(skb)) { struct sctphdr *sctp = sctp_hdr(skb); key->tp.src = sctp->source; key->tp.dst = sctp->dest; } else { memset(&key->tp, 0, sizeof(key->tp)); } } else if (key->ip.proto == IPPROTO_ICMP) { if (icmphdr_ok(skb)) { struct icmphdr *icmp = icmp_hdr(skb); /* The ICMP type and code fields use the 16-bit * transport port fields, so we need to store * them in 16-bit network byte order. */ key->tp.src = htons(icmp->type); key->tp.dst = htons(icmp->code); } else { memset(&key->tp, 0, sizeof(key->tp)); } } |
第二步:根据key查找flow table
调用struct sw_flow *ovs_flow_tbl_lookup_stats(struct flow_table *tbl, const struct sw_flow_key *key, u32 skb_hash, u32 *n_mask_hit)进行查找。
在内核中,flow table的数据结构如上图所示。
每个虚拟交换机对应一个datapath,每个datapath有一个flow table,每个flow table分成N个桶,根据key进行哈希,不同的key分布在不同的桶里面。
每个桶的大小是一个内存页的大小,在内存页的头部保存了保存了多少个元素,每个元素的大小。每个元素都是sw_flow,里面有key,也有action。
ovs_flow_tbl_lookup_stats会调用static struct sw_flow *flow_lookup(struct flow_table *tbl, struct table_instance *ti, const struct mask_array *ma, const struct sw_flow_key *key, u32 *n_mask_hit, u32 *index)
会调用masked_flow_lookup如下
| static struct sw_flow *masked_flow_lookup(struct table_instance *ti, const struct sw_flow_key *unmasked, const struct sw_flow_mask *mask, u32 *n_mask_hit) { struct sw_flow *flow; struct hlist_head *head; u32 hash; struct sw_flow_key masked_key; ovs_flow_mask_key(&masked_key, unmasked, false, mask); hash = flow_hash(&masked_key, &mask->range); head = find_bucket(ti, hash); (*n_mask_hit)++; hlist_for_each_entry_rcu(flow, head, flow_table.node[ti->node_ver]) { if (flow->mask == mask && flow->flow_table.hash == hash && flow_cmp_masked_key(flow, &masked_key, &mask->range)) return flow; } return NULL; } |
其中flow_hash计算哈希值,find_bucket根据哈希值查找桶,然后就是一个循环,逐个比较key是否相等,相等则返回flow。
第三步:执行action
调用int ovs_execute_actions(struct datapath *dp, struct sk_buff *skb, const struct sw_flow_actions *acts,struct sw_flow_key *key)
调用static int do_execute_actions(struct datapath *dp, struct sk_buff *skb, struct sw_flow_key *key, const struct nlattr *attr, int len)
在这个函数中,通过case语句,不同的action进行不同的操作。
| static int do_execute_actions(struct datapath *dp, struct sk_buff *skb, struct sw_flow_key *key, const struct nlattr *attr, int len) { /* Every output action needs a separate clone of 'skb', but the common * case is just a single output action, so that doing a clone and * then freeing the original skbuff is wasteful. So the following code * is slightly obscure just to avoid that. */ int prev_port = -1; const struct nlattr *a; int rem; for (a = attr, rem = len; rem > 0; a = nla_next(a, &rem)) { int err = 0; if (unlikely(prev_port != -1)) { struct sk_buff *out_skb = skb_clone(skb, GFP_ATOMIC); if (out_skb) do_output(dp, out_skb, prev_port, key); prev_port = -1; } switch (nla_type(a)) { case OVS_ACTION_ATTR_OUTPUT: prev_port = nla_get_u32(a); break; case OVS_ACTION_ATTR_USERSPACE: output_userspace(dp, skb, key, a, attr, len); break; case OVS_ACTION_ATTR_HASH: execute_hash(skb, key, a); break; case OVS_ACTION_ATTR_PUSH_MPLS: err = push_mpls(skb, key, nla_data(a)); break; case OVS_ACTION_ATTR_POP_MPLS: err = pop_mpls(skb, key, nla_get_be16(a)); break; case OVS_ACTION_ATTR_PUSH_VLAN: err = push_vlan(skb, key, nla_data(a)); break; case OVS_ACTION_ATTR_POP_VLAN: err = pop_vlan(skb, key); break; case OVS_ACTION_ATTR_RECIRC: err = execute_recirc(dp, skb, key, a, rem); if (nla_is_last(a, rem)) { /* If this is the last action, the skb has * been consumed or freed. * Return immediately. */ return err; } break; case OVS_ACTION_ATTR_SET: err = execute_set_action(skb, key, nla_data(a)); break; case OVS_ACTION_ATTR_SET_MASKED: case OVS_ACTION_ATTR_SET_TO_MASKED: err = execute_masked_set_action(skb, key, nla_data(a)); break; case OVS_ACTION_ATTR_SAMPLE: err = sample(dp, skb, key, a, attr, len); break; case OVS_ACTION_ATTR_CT: if (!is_flow_key_valid(key)) { err = ovs_flow_key_update(skb, key); if (err) return err; } err = ovs_ct_execute(ovs_dp_get_net(dp), skb, key, nla_data(a)); /* Hide stolen IP fragments from user space. */ if (err) return err == -EINPROGRESS ? 0 : err; break; } if (unlikely(err)) { kfree_skb(skb); return err; } } if (prev_port != -1) do_output(dp, skb, prev_port, key); else consume_skb(skb); return 0; } |
如果可以直接输出,则调用static void do_output(struct datapath *dp, struct sk_buff *skb, int out_port, struct sw_flow_key *key)他调用void ovs_vport_send(struct vport *vport, struct sk_buff *skb)进行发送。

相关文章推荐
- Openvswitch原理与代码分析(3): openvswitch内核模块的加载
- Openvswitch原理与代码分析(5): 内核中的流表flow table操作
- Openvswitch原理与代码分析(3): openvswitch内核模块的加载
- Openvswitch原理与代码分析(6):用户态流表flow table的操作
- Nand ECC校验和纠错原理及2.6.27内核ECC代码分析
- CVE-2014-0038内核漏洞原理与本地提权利用代码实现分析 作者:seteuid0
- Openvswitch原理与代码分析(4): 修改Openvswitch代码添加自定义action
- Linux kernel 3.10内核源码分析--slab原理及相关代码
- Openvswitch原理与代码分析(6):用户态流表flow table的操作
- Openvswitch原理与代码分析(2): ovs-vswitchd的启动
- Openvswitch原理与代码分析(7): 添加一条流表flow
- Openvswitch原理与代码分析(1):总体架构
- Openvswitch原理与代码分析(1):总体架构
- Openvswitch原理与代码分析(2):用户态流表flow table的操作
- Nand ECC校验和纠错原理及2.6.27内核ECC代码分析
- Nand ECC校验和纠错原理及2.6.27内核ECC代码分析<转帖>
- Openvswitch原理与代码分析(4):网络包的处理过程
- Openvswitch原理与代码分析(3): 添加一条流表flow
- Openvswitch原理与代码分析(8): 修改Openvswitch代码添加自定义action
- Openvswitch原理与代码分析(7): 添加一条流表flow