Java的内存区域以及各种垃圾回收算法和垃圾回收器
2016-09-08 18:40
477 查看
Java的内存区域可以分为
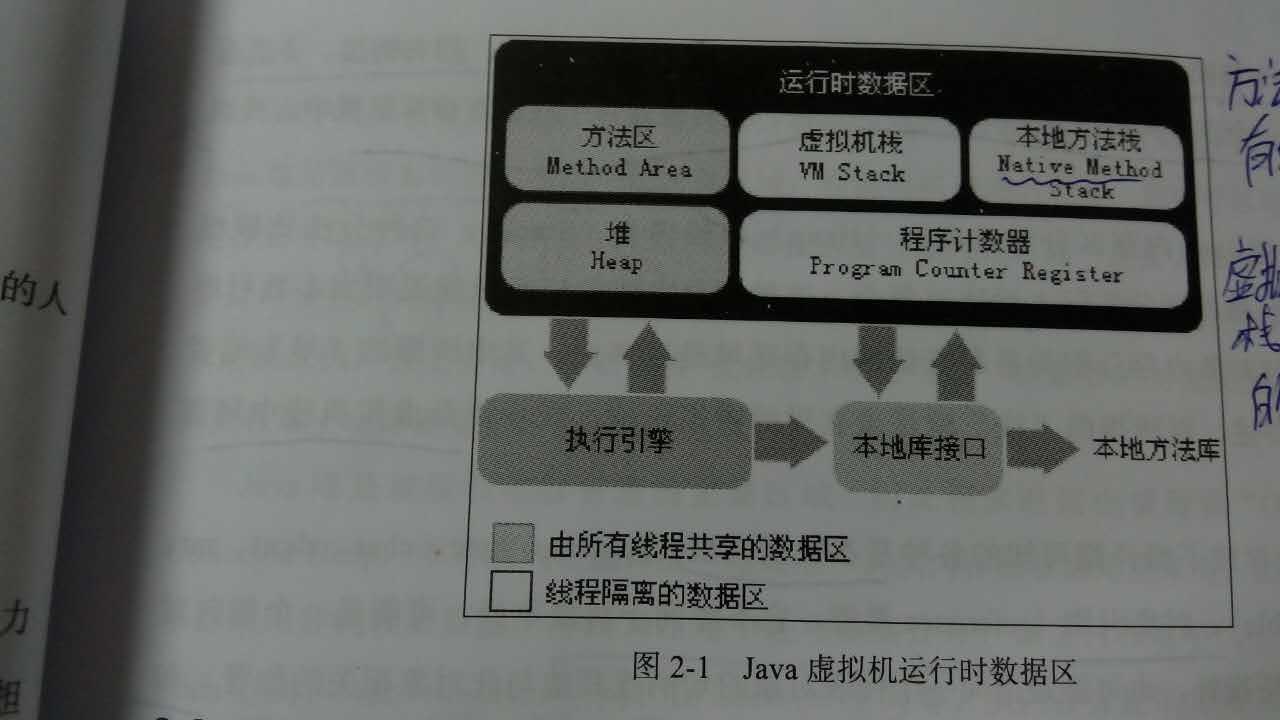
方法区(区别于永生代),堆,JVM栈,本地方法栈,程序计数器。
其中方法区,堆是线程共享的,JVM栈和本地方法栈,程序计数器是线程独有的。
1.程序计数器相当于当前线程执行的字节码的行号指示器。就是线程切换后可以恢复到正确的位置。
2.JVM栈是线程私有的,每个方法调用的时候都会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
局部变量表存放了编译可知的各种基本数据类型、对象引用(引用有两种方式,一种是栈里面指向对象的起初地址,另一种是指向句柄池)和returnAddress类型。
double和long占用两个(slot),其余占用一个。
本地方法栈其实和JVM栈是一样,不过是执行native才会开辟的空间
3.Java堆,所有对象实例和数组都要再堆上分配,GC经常发生的地方,分成新生代和老年代。它是逻辑上连续的,但是物理上是离散的。
4.方法区,方法区是存储类信息,常量,静态变量、还有JIT编译以后代码的区域。
5.运行时常量池是存放类、字段、方法、接口等描述信息,还有就是编译器生成的各种字面量和符号信息。重要的一点是,运行时常量池不一定是编译的时候才能放进去,String.intern()等方法就可以运行的时候把常量放到常量池。
6.直接内存,这部分不是虚拟机运行时数据区的一部分。但是也会经常被使用。
上文我们说了Java的内存区域,我们知道了堆是GC经常发生的地方。那么我们探究一下堆的垃圾回收算法。
1.标记-清除算法
标记所有需要清除的对象,然后统一清除
2.复制算法(新生代使用的垃圾回收算法)
把内存分成两块只用其中的一块,当其中一块内存用完的时候就把内存中存活的对象复制到另一块内存中,然后把已使用过的内存清除掉。
JVM新生代的时候是以8:1:1来分配的,8(Eden):1(survivor):1(survivor)。一次用一个survivor和一个Eden。然后一次GC把存活的对象复制到另一块survivor中。然后存活的对象超过了一个survivor的空间就把这些对象直接放到老年区里面。
3.标记-整理算法
标记整理算法就是把存活的对象移动到一边然后再清除不再存活的对象。
4.分代收集算法
新生代一般用复制算法。老年代一般用标记清除或者标记整理算法
枚举根节点
使用OopMap可以知道GC Roots节点可以达到的引用而不需要这样,GC的时候就不用逐个去检查。
安全点
安全点的意思就是一个要在一个特点的点,在这个特定的点可以维护更新OopMap。有两种中断方式抢先式中断和主动式中断,其中抢先式中断就是JVM强制停止所有线程然后如果发现线程不在safepoint就让线程继续跑,跑到safepoint。
saferegion其实就是一个安全区域,在这个区域里面对象之间的引用不变。
讨论完垃圾回收算法,让我们讨论一下几种垃圾收集器:
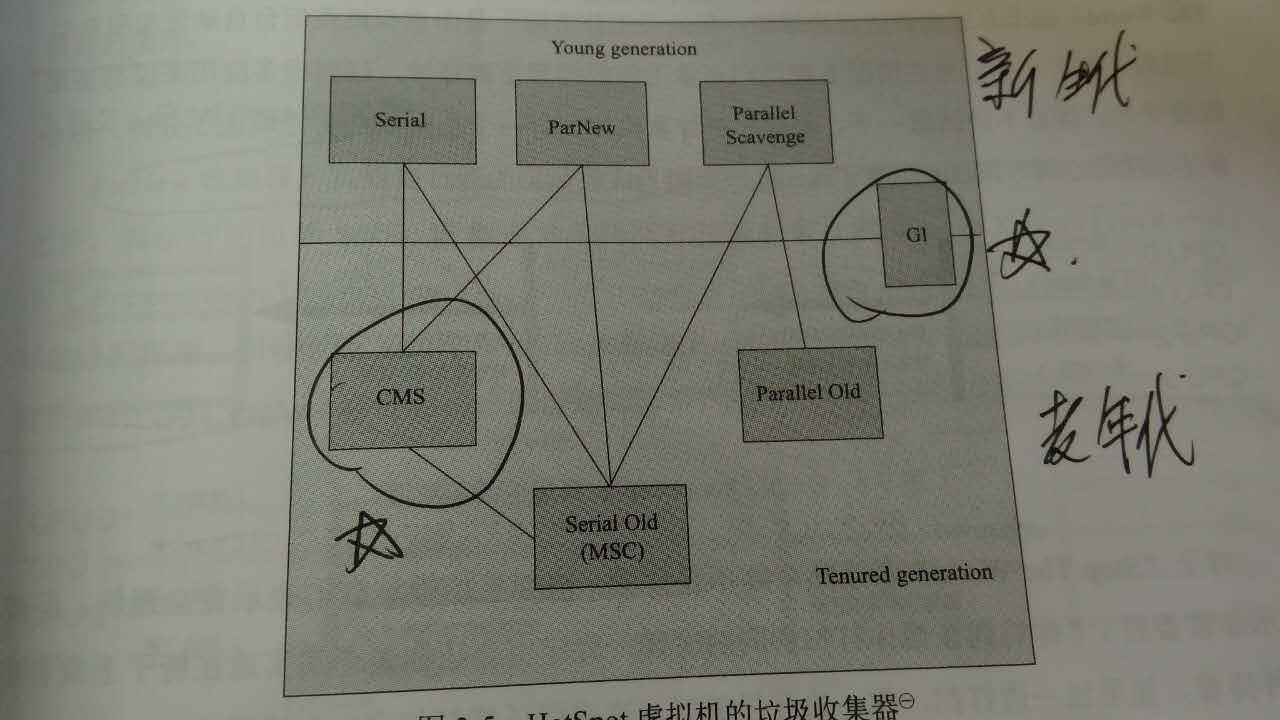
Serial收集器
单线程的垃圾收集器,它进行GC时,必须stop-the-world,新生代用复制算法,是一个新生代GC器
。虽然这个收集器是单线程的但是在client中表现很好,所有client中不失是一个很好的选择。
parNew收集器
其实就是Serial的多线程版本而已,用在服务器端。如果老年代中使用CMS收集器的话,新生代只能用Serial或者parNew。
Parallel Scavenge收集器
关注吞吐量的GC收集器,(吞吐量=(用户代码运行时间/总运行时间))
自适应调节根据系统运行情况和收集性能健康,动态调节参数,让吞吐量达到最大。
Serial Old收集器
Serial的老年代版。使用标记整理算法,可以和Parallel Scavenge一起使用。
Parallel Old收集器
ParNew收集器的老年代版,使用标记整理算法,可以喝Parallel Scavenge一起使用
CMS收集器
这个垃圾回收器是以最短的stop-the-world时间作为目标的区别与以吞吐量追求的parallel Scavenge收集器,分为四个步骤初始标记,并发标记,重新标记,并发清除
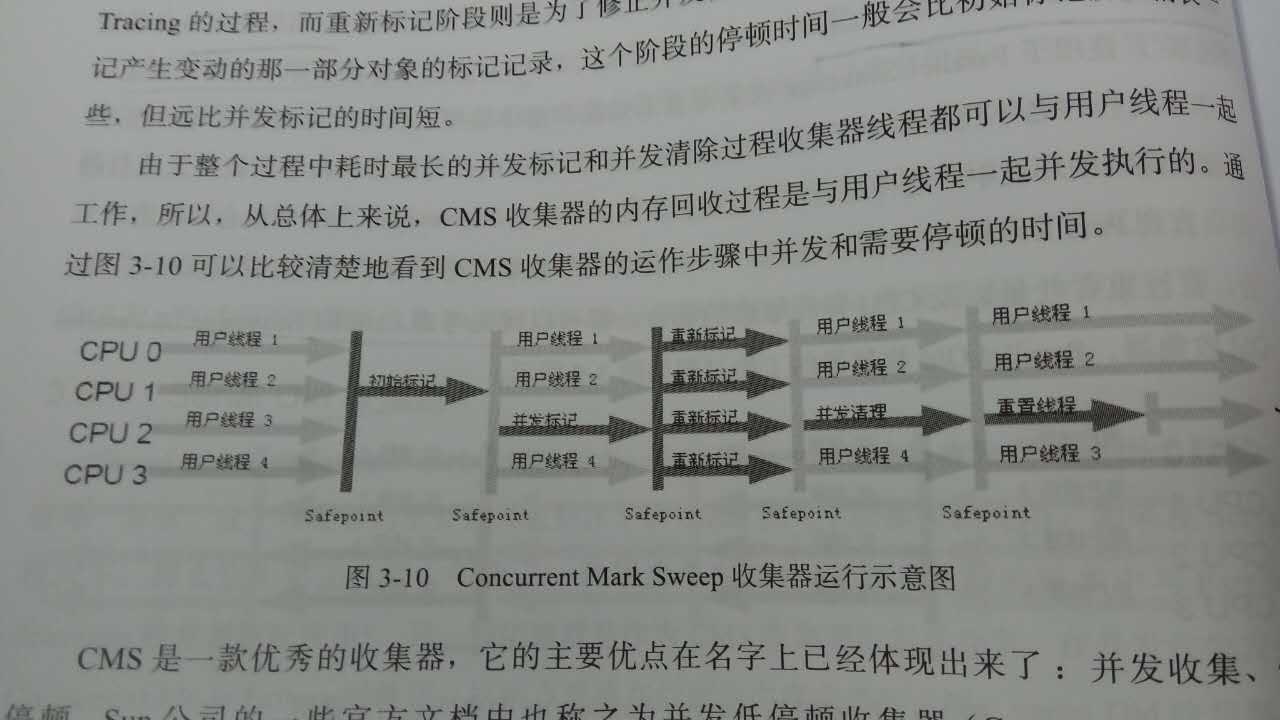
初始标记是收集GC ROOTS能够直接链接到的对象,这个很重要。所以速度很快
并发标记就是并发的扩散标记
重新标记就是修复并发标记的时候用户运行是的引用关系出现不同
并发清除就是清除没有引用到的对象。
CMS是基于标记清除算法的所以容易有内存碎片
而且因为并发清除的时候还可能出现垃圾,必须预留出一定的空间在发生full GC之前
CMS对CPU资源十分敏感
G1收集器
四大特点:
1并行和并发:运用多CPU的优势并发执行缩短stop-to-world
2分代收集:不再像CMS那种一样只管一个代
3空间整合:运用标记复制算法
4可预测的停顿:制定一个时间,垃圾收集不能超过这个时间段
而且G1收集器的老年代和新生代已经不再进行物理上区分而是通过划分很多region,然后每次看看清除哪个region的价值高就清除哪个。
但是这样造成一个问题就是每次进行minor GC的时候都要把年轻代和老年代全部扫描一次很不好,那怎么避免呢,就是在G1收集器中,region之间的对象引用联系通过remember set进行链接就好。
G1收集器的过程如下
初始标记
并发标记
重新标记
筛选删除
其实前两个步骤和CMS是差不多的,但是重新标记的时候要主要她会并发进行,每个线程在并发标记的时候对象引用的改变放在remember set logs里面,然后最后合并到remember set中,最后再根据每个region中哪个更加值得清理就清理哪个。。
还有一个就是想讨论一下新生代和老年代。
他们的定义我就不多说了,很直白,那有没有一种情况就是直接夸过新生代直接进入老年代的呢,有,就是大对象。大的数组那种大对象就会直接进入老年代不会经过新生代
还有一种就是对象“变老”,就是一个对象经过15次GC就会从新生代落到老年代了。
本文参考,周志明的《深入理解Java虚拟机》
方法区(区别于永生代),堆,JVM栈,本地方法栈,程序计数器。
其中方法区,堆是线程共享的,JVM栈和本地方法栈,程序计数器是线程独有的。
1.程序计数器相当于当前线程执行的字节码的行号指示器。就是线程切换后可以恢复到正确的位置。
2.JVM栈是线程私有的,每个方法调用的时候都会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
局部变量表存放了编译可知的各种基本数据类型、对象引用(引用有两种方式,一种是栈里面指向对象的起初地址,另一种是指向句柄池)和returnAddress类型。
double和long占用两个(slot),其余占用一个。
本地方法栈其实和JVM栈是一样,不过是执行native才会开辟的空间
3.Java堆,所有对象实例和数组都要再堆上分配,GC经常发生的地方,分成新生代和老年代。它是逻辑上连续的,但是物理上是离散的。
4.方法区,方法区是存储类信息,常量,静态变量、还有JIT编译以后代码的区域。
5.运行时常量池是存放类、字段、方法、接口等描述信息,还有就是编译器生成的各种字面量和符号信息。重要的一点是,运行时常量池不一定是编译的时候才能放进去,String.intern()等方法就可以运行的时候把常量放到常量池。
6.直接内存,这部分不是虚拟机运行时数据区的一部分。但是也会经常被使用。
上文我们说了Java的内存区域,我们知道了堆是GC经常发生的地方。那么我们探究一下堆的垃圾回收算法。
1.标记-清除算法
标记所有需要清除的对象,然后统一清除
2.复制算法(新生代使用的垃圾回收算法)
把内存分成两块只用其中的一块,当其中一块内存用完的时候就把内存中存活的对象复制到另一块内存中,然后把已使用过的内存清除掉。
JVM新生代的时候是以8:1:1来分配的,8(Eden):1(survivor):1(survivor)。一次用一个survivor和一个Eden。然后一次GC把存活的对象复制到另一块survivor中。然后存活的对象超过了一个survivor的空间就把这些对象直接放到老年区里面。
3.标记-整理算法
标记整理算法就是把存活的对象移动到一边然后再清除不再存活的对象。
4.分代收集算法
新生代一般用复制算法。老年代一般用标记清除或者标记整理算法
枚举根节点
使用OopMap可以知道GC Roots节点可以达到的引用而不需要这样,GC的时候就不用逐个去检查。
安全点
安全点的意思就是一个要在一个特点的点,在这个特定的点可以维护更新OopMap。有两种中断方式抢先式中断和主动式中断,其中抢先式中断就是JVM强制停止所有线程然后如果发现线程不在safepoint就让线程继续跑,跑到safepoint。
saferegion其实就是一个安全区域,在这个区域里面对象之间的引用不变。
讨论完垃圾回收算法,让我们讨论一下几种垃圾收集器:
Serial收集器
单线程的垃圾收集器,它进行GC时,必须stop-the-world,新生代用复制算法,是一个新生代GC器
。虽然这个收集器是单线程的但是在client中表现很好,所有client中不失是一个很好的选择。
parNew收集器
其实就是Serial的多线程版本而已,用在服务器端。如果老年代中使用CMS收集器的话,新生代只能用Serial或者parNew。
Parallel Scavenge收集器
关注吞吐量的GC收集器,(吞吐量=(用户代码运行时间/总运行时间))
自适应调节根据系统运行情况和收集性能健康,动态调节参数,让吞吐量达到最大。
Serial Old收集器
Serial的老年代版。使用标记整理算法,可以和Parallel Scavenge一起使用。
Parallel Old收集器
ParNew收集器的老年代版,使用标记整理算法,可以喝Parallel Scavenge一起使用
CMS收集器
这个垃圾回收器是以最短的stop-the-world时间作为目标的区别与以吞吐量追求的parallel Scavenge收集器,分为四个步骤初始标记,并发标记,重新标记,并发清除
初始标记是收集GC ROOTS能够直接链接到的对象,这个很重要。所以速度很快
并发标记就是并发的扩散标记
重新标记就是修复并发标记的时候用户运行是的引用关系出现不同
并发清除就是清除没有引用到的对象。
CMS是基于标记清除算法的所以容易有内存碎片
而且因为并发清除的时候还可能出现垃圾,必须预留出一定的空间在发生full GC之前
CMS对CPU资源十分敏感
G1收集器
四大特点:
1并行和并发:运用多CPU的优势并发执行缩短stop-to-world
2分代收集:不再像CMS那种一样只管一个代
3空间整合:运用标记复制算法
4可预测的停顿:制定一个时间,垃圾收集不能超过这个时间段
而且G1收集器的老年代和新生代已经不再进行物理上区分而是通过划分很多region,然后每次看看清除哪个region的价值高就清除哪个。
但是这样造成一个问题就是每次进行minor GC的时候都要把年轻代和老年代全部扫描一次很不好,那怎么避免呢,就是在G1收集器中,region之间的对象引用联系通过remember set进行链接就好。
G1收集器的过程如下
初始标记
并发标记
重新标记
筛选删除
其实前两个步骤和CMS是差不多的,但是重新标记的时候要主要她会并发进行,每个线程在并发标记的时候对象引用的改变放在remember set logs里面,然后最后合并到remember set中,最后再根据每个region中哪个更加值得清理就清理哪个。。
还有一个就是想讨论一下新生代和老年代。
他们的定义我就不多说了,很直白,那有没有一种情况就是直接夸过新生代直接进入老年代的呢,有,就是大对象。大的数组那种大对象就会直接进入老年代不会经过新生代
还有一种就是对象“变老”,就是一个对象经过15次GC就会从新生代落到老年代了。
本文参考,周志明的《深入理解Java虚拟机》

相关文章推荐
- Java的垃圾收集算法、垃圾收集器以及内存分配与回收策略
- 【java】---JVM内存模型以及垃圾回收算法
- Java之JVM垃圾回收 内存结构以及垃圾回收算法
- Java之JVM垃圾回收 内存结构以及垃圾回收算法
- Java垃圾回收机制以及内存泄露
- 牛客网Java刷题知识点之垃圾回收算法过程、哪些内存需要回收、被标记需要清除对象的自我救赎、对象将根据存活的时间被分为:年轻代、年老代(Old Generation)、永久代、垃圾回收器的分类
- JVM内存段分配,Java垃圾回收调优,Heap设定,Jvm内存回收算法
- Java内存区域及Java垃圾回收机制概述
- Java 按代回收垃圾以及回收算法
- Jvm内存区以及垃圾回收算法
- JVM的内存区域划分以及垃圾回收机制详解
- JAVA内存区域--垃圾收集算法
- (转)Java 内存区域分配和垃圾回收(GC)机制
- JVM的内存区域划分以及垃圾回收机制详解
- Java中的垃圾回收问题以及在创建对象的时候的内存的分析
- Java基础---JVM内存管理以及垃圾回收机制
- java 垃圾回收机制和各种实现算法
- Java内存区域分配、存储、垃圾回收策略与回收机制(深入JVM虚拟机)
- Java垃圾回收机制以及内存泄露