Shell 正则表达式
2016-09-07 19:32
120 查看
什么是正则表达式
正则表达式是用于描述字符排列和匹配模式的一种语法规则。它主要用于字符串的模式分割、匹配、查找以及替换操作。
概念看看就行,为了保证博文的完整性,记录下,其实没太大用….
正则表达式的分类
1.基本的正则表达式(Basic Regular Expression 又叫Basic RegEx 简称BREs)2.扩展的正则表达式(Extended Regular Expression 又叫Extended RegEx 简称EREs)
3.Perl的正则表达式(Perl Regular Expression 又叫Perl RegEx 简称PREs)
基本组成部分
正则表达式的基本组成部分。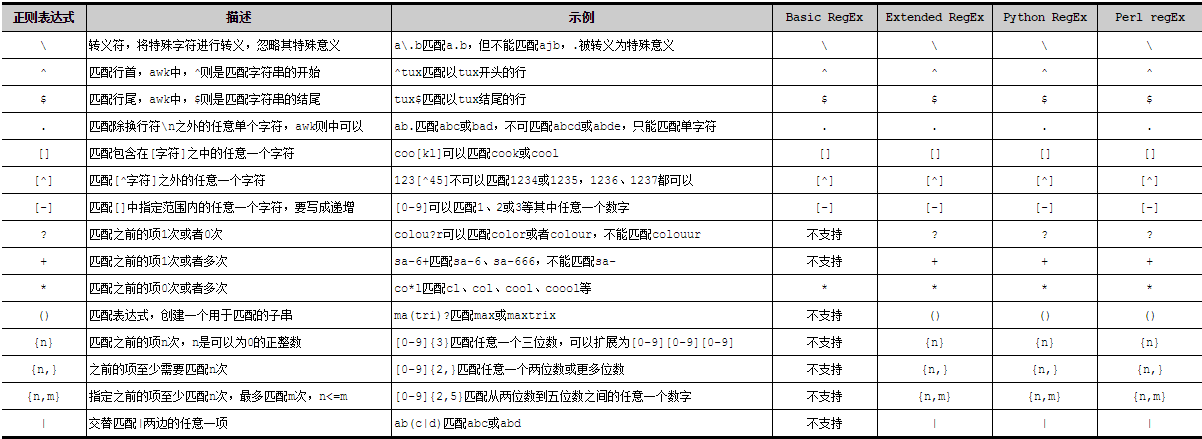
POSIX字符类
POSIX字符类是一个形如[:…:]的特殊元序列(meta sequence),他可以用于匹配特定的字符范围。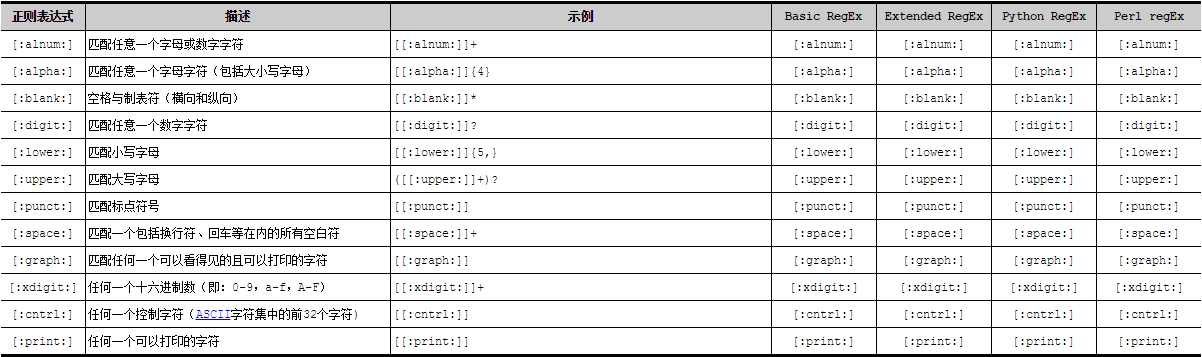
元字符
元字符(meta character)是一种Perl风格的正则表达式,只有一部分文本处理工具支持它,并不是所有的文本处理工具都支持。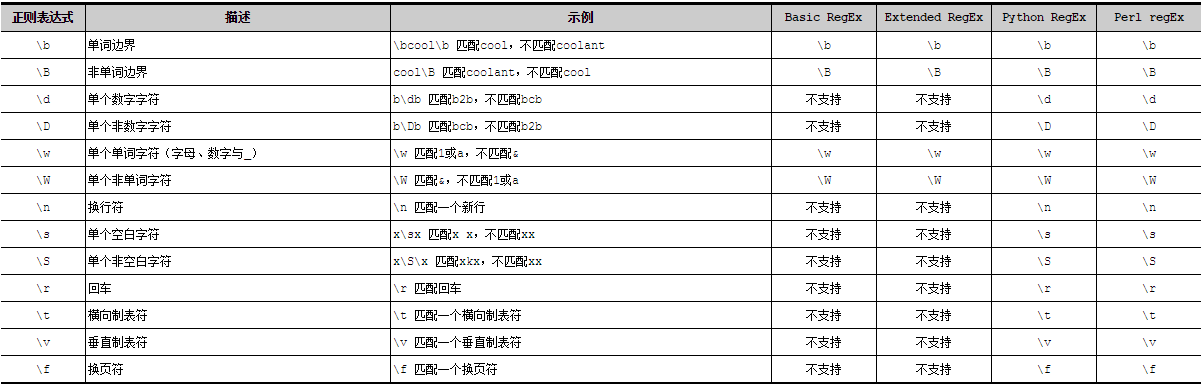
正则表达式与通配符
正则表达式
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep,awk,sed等命令可以支持正则表达式。通配符用来匹配符号条件的文件名,通配符是完全匹配。
ls,find,cp这些命令不支持正则表达式,所以只能使用shell自己的通配符来进行匹配。
通配符
* 代表匹配任意内容? 代表匹配任意一个内容
[] 代表中括号中一个字符
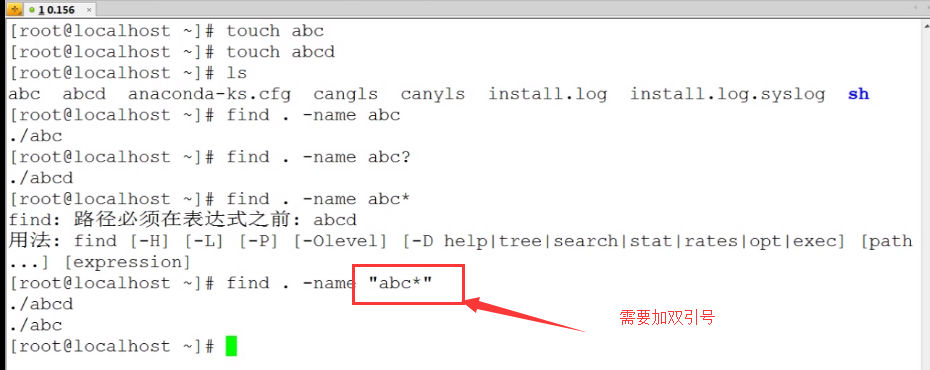
基础正则表达式概述
常见元字符
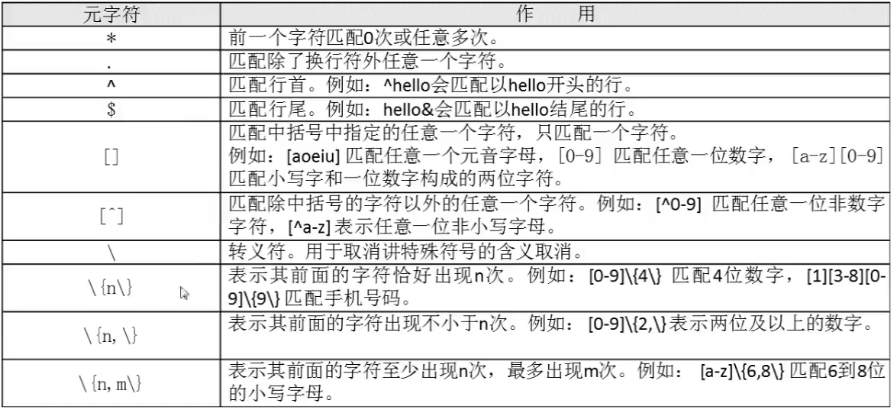
*前一个字符匹配0次或任意多次
. 匹配除了换行符外任意一个字符
^匹配行首 例如
^hello会匹配以hello开头的行
$匹配行尾 例如
hello$会匹配以hello结尾的行
[] 匹配中括号中指定的任意一个字符,只匹配一个字符。[0-9]匹配任意一位数字
[^]匹配除中括号的字符以外的任意一个字符。 例如
[^0-9]匹配任意一位非数字字符
[^a-z]表示任意一位非小写字母
\ 转义符 用于取消将特殊符号的含义取消
\{n\} 表示其前面的字符恰好出现N次 例如 [0-9]{4} 匹配4位数字[1][3-8][0-9]\{9\} 匹配手机号码\{n,\} 表示其前面的字符出现不小于n次。 例如 [0-9]{2,} 表示两位及以上的数字\{n,m\} 表示其前面的字符至少出现n次,最多出现m次。例如 [a-z]{6,8} 匹配6到8位的小写字母
元字符 *


元字符 .

符号: .
grep "s..d" test.txt 表示匹配s和d之间含有2个任意字符(除换行符)行,有多少个点就多少个字符 grep "s.*d" test.txt 表示匹配s和d之间含有任意内容的行
元字符 ^

符号^代表匹配行首,符号$代表匹配行尾
grep "^s" test.txt 匹配以s开头的行 grep "b$" test.txt 匹配以b结尾的行 grep "^$" test.txt 匹配空白行 grep -n 在结果中增加行号
元字符 []

符号[ ]的作用与通配符中的[ ]一致
grep "[0-9]" test.txt 匹配包含有数字的全部行 注意:^用在[ ]内代表取反 grep "[^0-9]" test.txt 匹配包含字母的全部行 匹配所有字母: [a-zA-z]
元字符 [^]

"^"匹配行首,"$"匹配行尾 "^M" 匹配以大写“M”开头的行 "n$" 匹配以小写“n”结尾的行 "^$" 会匹配空白行
元字符 \

元字符 \{n\}


"\{n\}"表示其前面的字符恰好出现n次元字符 \{n,\}

"\{n,\}"表示其前面的字符出现n次以上"^[0-9]\{3\}[a-z]"以数字开头,且三个以上字母的行元字符 \{n,m\}

正则表达式案例
grep日期 yyyy-mm-dd
grep日期 yyyy-mm-dd : [0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}grep IP地址
grep IP地址:
ifconfig|grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}"
inet 192.168.0.104 netmask 255.255.255.0 broadcast 192.168.0.255

相关文章推荐
- shell 正则表达式基础
- Shell下的正则表达式及实例
- shell正则表达式
- Shell中的正则表达式及字符串处理汇总:
- Shell正则表达式学习笔记
- Linux基础:shell中正则表达式grep,egrep的基础用法
- 匹配一个正则表达式的Shell
- shell 下正则表达式的匹配
- 详解Linux--shell脚本之正则表达式
- Shell中的if结合正则表达式使用
- Linux--shell脚本之正则表达式
- shell基础学习之正则表达式
- Shell正则表达式之grep、sed、awk实操笔记
- Linux_shell_正则表达式
- shell中正则表达式
- Linux学习笔记:Shell基础正则表达式
- SHELL-expect、正则表达式和sed的使用
- shell学习(正则表达式)
- shell正则表达式整理
- shell之正则表达式