Cypher查询语言--Neo4j中的SQL(5)
2016-08-31 17:45
239 查看
聚合(Aggregation)
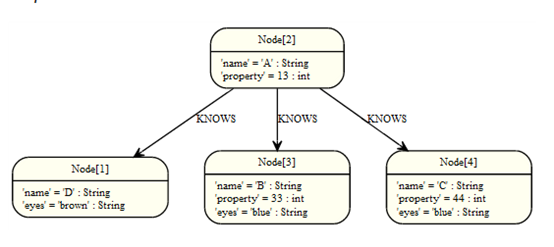
为集合计算数据,Cypher提供聚类功能,与SQL的group by类似。在return语句中发现的任何聚类函数,所有没有聚类函数的列将作为聚合key使用。图:
计数
计数(count)使用来计算行数。Count有两种使用方法。Count(*)计算匹配的行的行数,count(<标识符>)计算标识符中非空值数。计算节点数
计算链接到一个节点的节点数,可以使用count(*)。查询:
START n=node(2)
MATCH (n)-->(x)
RETURN n, count(*)
返回开始节点和相关节点节点数。
结果:

分组计算关系类型
计算分组了得关系类型,返回关系类型并使用count(*)计算。查询:
START n=node(2)
MATCH (n)-[r]->()
RETURN type(r), count(*)
返回关系类型和其分组数。
结果:

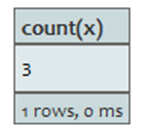
计算实体数
相比使用count(*),可能计算标识符更实在。查询:
START n=node(2)
MATCH (n)-->(x)
RETURN count(x)
返回链接到开始节点上的节点数
结果:
计算非空可以值数
查询:START n=node(2,3,4,1)
RETURN count(n.property?)
结果:

求和(sum)
Sum集合简单计算数值类型的值。Null值将自动去掉。如下:查询:
START n=node(2,3,4)
RETURN sum(n.property)
计算所有节点属性值之和。
结果:

平均值(avg)
Avg计算数量列的平均值查询:
START n=node(2,3,4)
RETURN avg(n.property)
结果:

最大值(max)
Max查找数字列中的最大值。查询:
START n=node(2,3,4)
RETURN max(n.property)
结果:

最小值(min)
Min使用数字属性作为输入,并返回在列中最小的值。查询:
START n=node(2,3,4)
RETURN min(n.property)
结果:

聚类(COLLECT)
Collect将所有值收集到一个集合list中。查询:
START n=node(2,3,4)
RETURN collect(n.property)
返回一个带有所有属性值的简单列。
结果:

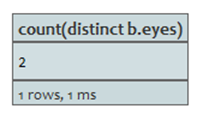
相异(DISTINCT)
聚合函数中使用distinct来去掉值中重复的数据。查询:
START a=node(2)
MATCH a-->b
RETURN count(distinct b.eyes)
结果:

相关文章推荐
- Cypher查询语言--Neo4j中的SQL(4)
- Cypher查询语言--Neo4j中的SQL(1)
- Cypher查询语言--Neo4j中的SQL(1)
- Cypher查询语言--Neo4j中的SQL(6)
- Cypher查询语言--Neo4j中的SQL(5)
- Cypher查询语言--Neo4j中的SQL(3)
- Cypher查询语言--Neo4j中的SQL
- Cypher查询语言--Neo4j中的SQL
- Cypher查询语言--Neo4j中的SQL(3)
- Cypher查询语言--Neo4j中的SQL(2)
- Cypher查询语言--Neo4j中的SQL(2)
- Cypher查询语言--Neo4j中的SQL
- Cypher查询语言--Neo4j中的SQL(4)
- Neo4j Cypher查询语言详解
- Neo4j入门(1) --- Cypher查询语言
- Neo4j-Cypher查询语言-函数
- Cypher查询语言--Neo4j 综合(四)
- Cypher查询语言--Neo4j 之高级篇 (六)
- Cypher查询语言--Neo4j 入门 (一)
- Cypher查询语言--Neo4j-MATCH(二)