理解计算机的编码系统
2016-08-17 16:31
363 查看
我之前的很多关于计算机的疑问,包括启动,编译,程序的执行等疑问,在我对”编码“的理解加深了一步之后,我整个都豁然开朗的感觉。
最开始学C语言或者计算机的时候,都会听到ASCII码。
那么到底怎么理解ASCII码,以及后来的unicode,中国的编码系统GB2312呢?
我们来做实验。
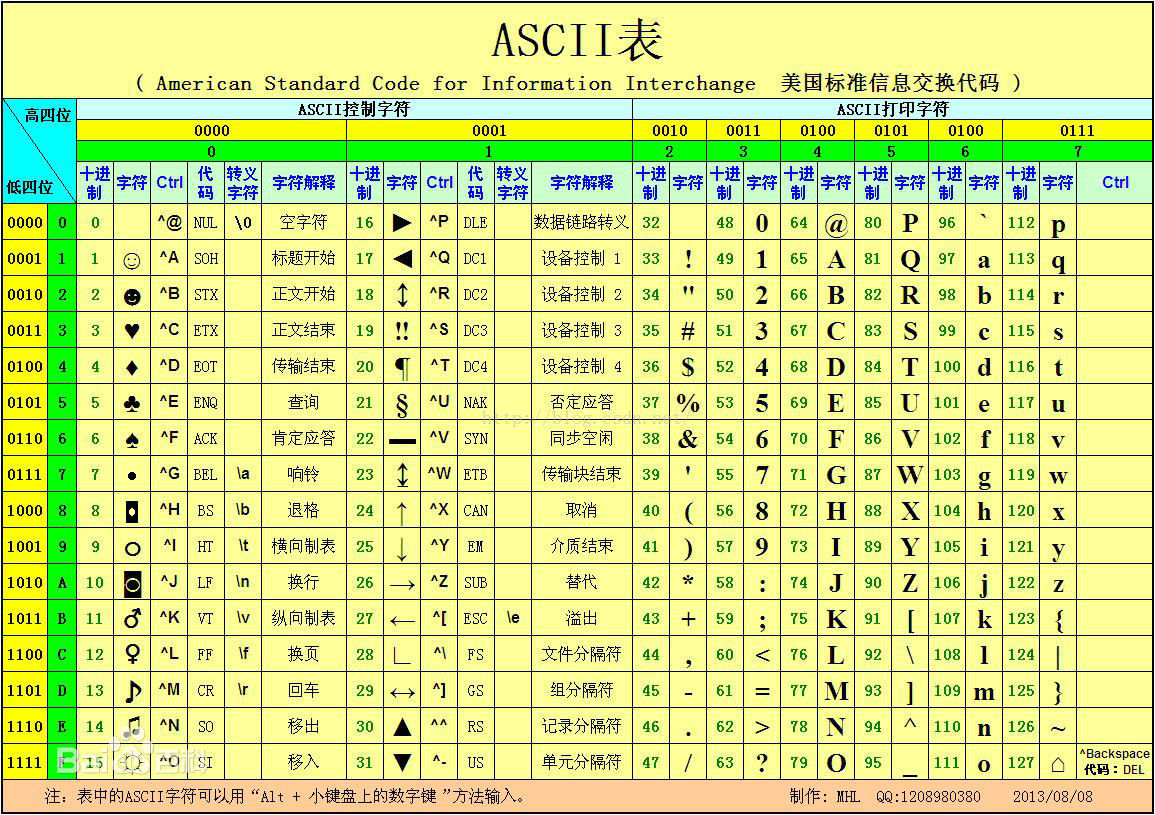
我新建一个文件,在windows下。没有后缀名。用notepad打开
第一以文本查看,“Ab123回车”(回车是指我输入的时候按回车键)
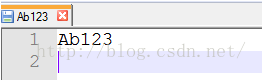
第二以hex,二进制方式查看(hex deitor,)十六进制形式。

以二进制查看的时候,我们可以对照ASCII表来查看,字母A,对应的ASCII表示0100 0001(十六进制表示0x41).下面的字母b,数字123同样可查。
0d,0a一个回车,一个换行。
注意:要理解回车和换行的区别,需要了解早期的打印机与早期的计算机。以为按下回车键,同时又换行又回车。那么其实回车,在最早的电传打印机上,回车仅仅是光标从行末切换到行首。而如果不换行的话,接着打印,会覆盖之前的输出。换行就是移动纸,让纸往上移动一行,不要覆盖之前打印的。
当我们文本编辑时候,按下回车按键,其实在编码里,编入了0d,0a两个编码值。留意下文本的大小,7bytes.
其实没有换行的时候,是5bytes.
这一点在linux下,是不一样的。在linux下vi -b file,再输入:%!xxd
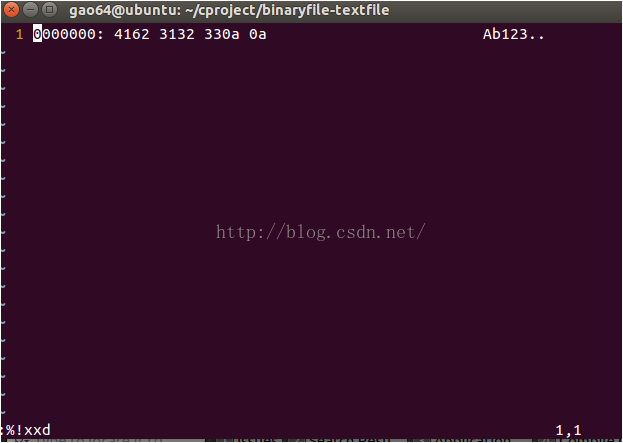
最后加了两个0a.
我这里没有MAC电脑,不然可以贴张图片。苹果电脑操作系统对回车换行的处理也不一样。
苹果操作系统,会是两个0d.
为什么会这样子呢?
电传打印机出现早于计算机,后来在计算机文档上面也有类似”回车,换行“的需求,因为文档不可能没有新的一行。
那时候存储器非常昂贵,早期的计算机科学家觉得应该不应该浪费这两个字符的空间。就出现了分歧。
Dos和windows采用回车+换行CR/LF表示下一行,(0d 0a)
而UNIX/Linux采用换行符LF表示下一行,(0a 0a)
苹果机(MAC OS系统)则采用回车符CR表示下一行.(0d od)
关于这个回车换行的区别,也会给文档在不同平台的显示带来不便。windows下的文档在linux打开会出现很多^M类似的。
在不同平台间使用FTP软件传送文件时, 在ascii文本模式传输模式下, 一些FTP客户端程序会自动对换行格式进行转换. 经过这种传输的文件字节数可能会发生变化. 如果你不想ftp修改原文件, 可以使用bin模式(二进制模式)传输文本.
那二进制文件与ASCII文件的区别是什么呢?第三部分再详细分析
所有字符存储的是以二进制的,那么记事本或者notepad打开这个文档的时候。首先读取文件物理上所对应的二进制比特流,然后按照你所选择的解码方式来解释这个流,然后将解释结果显示出来。那所以当编码格式与解码的格式不一致,不兼容的时候,就会出现乱码的情况。

我们理解了编码与解码就进一步想,计算机出现初期,是没有中文编码的。
如果我以二进制的编码形式编辑二进制文档,再notepad打开,选择GB2312形式解码,那就应该显示中文。

notepad打开
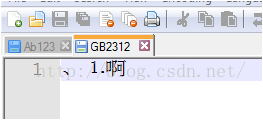
与GB2312表上显示一样。
那反过来,我以hex编辑器自己对照着GB2312文档编辑,那也可以写文章啊,写本小说,没问题,但是基本没有人愿意这么做吧,太累了。
文档编辑器的作用就是我们的输入,文档编辑器自动编码存储,同时打开的时候根据选择的编码系统解码并显示。
查看文档大小,占用空间6bytes .与我们常常听说一个中文字符占用两个bytes.这下我们理解为什么占用2bytes .
当然编码规范很多很多,unicode, utf8等不一而足。
我们理解了编码 是怎么回事,就可以了。
区别在于了逻辑上对于这些0101的解析。
说白了就是,这些010100等代表什么意思。
上面我们以二进制形式打开,编辑,再存储,如果我们不使用文档编辑器打开,那它就是二进制文件。
网上有一个例子,比如一个数字5678,存储在计算机里,以ASCII编码形式,那就是四个字符 5,查找ASCII表,是0x35,二进制数00110101.
依次查出来编码是00110101 00110110 00110111 00111000 。存储在存储器里。占用4个字节。
以二进制形式怎么存储,他们说是00010110 00101110 (两个字节),这个是把5678(五千六百七十八转为二进制形式表示的)。
可以这么理解,但是上面4个字节也是二进制形式的嘛,为什么不是二进制文件?如果不是文本编辑器以ASCII编码格式打开,谁也不知道这个表示的是5678.
所以说,个人认为,没有指定编码规则的二进制文件,讨论是二进制文件还是ASCII文件是无意义的。
在一定的编码规则基础上,这些编码才有意义。
我个人理解,ASCII文本文件是二进制文件下一种,确定了编码规则的文件。
这篇文章对这个问题有比较详细的讨论,链接如下
http://www.nowamagic.net/librarys/veda/detail/658
编程测试了C语言读取二进制文件,与ASCII编码的文件。在最后回车换行的地方有细微的差异。
文档内容就是Ab123\r\n(回车),二进制如图

一个是r 一个是rb(rb是二进制形式)
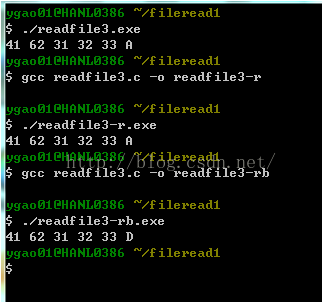
C的文本方读写与二进制读写的差别仅仅体现在回车换行符的处理上。文本方式写时,每遇到一个''n''(0AH换行符),它将其换成''r n''(0D0AH,回车换行),然后再写入文件;
当文本读取时,它每遇到一个''rn''将其反变化为''n'',然后送到读缓冲区。
所以文本形式读取时候(readfile3-r),虽然二进制编码是0d(\r) ,0a(\n),先转为\n,然后输出,所以输出是0A.
而二进制读取时候,a[5]就是0d,输出也是0d.
LINUX下测试。

由于二进制表示时候linux下只有0a,所以两种形式都是0a.
其实要说明的是UNIX和LINUX不像DOS与windows那样区分文本文件与二进制文件。
LINUX把所有文件看成二进制文件。
windows下用另外一个函数打开。
windows下用open函数打开文档,读取。
是以文件形式打开的。linux下使用这个open 函数,输出与使用file open一样。(其实也 不会有差别,因为二进制文件无差别。)

最开始学C语言或者计算机的时候,都会听到ASCII码。
那么到底怎么理解ASCII码,以及后来的unicode,中国的编码系统GB2312呢?
我们来做实验。
以ASCII编码形式的存储,以及记事本的打开文本文件的过程
首先来看ASCII表格,作为对照。来自网上搜索的图片。我新建一个文件,在windows下。没有后缀名。用notepad打开
第一以文本查看,“Ab123回车”(回车是指我输入的时候按回车键)
第二以hex,二进制方式查看(hex deitor,)十六进制形式。
以二进制查看的时候,我们可以对照ASCII表来查看,字母A,对应的ASCII表示0100 0001(十六进制表示0x41).下面的字母b,数字123同样可查。
0d,0a一个回车,一个换行。
注意:要理解回车和换行的区别,需要了解早期的打印机与早期的计算机。以为按下回车键,同时又换行又回车。那么其实回车,在最早的电传打印机上,回车仅仅是光标从行末切换到行首。而如果不换行的话,接着打印,会覆盖之前的输出。换行就是移动纸,让纸往上移动一行,不要覆盖之前打印的。
当我们文本编辑时候,按下回车按键,其实在编码里,编入了0d,0a两个编码值。留意下文本的大小,7bytes.
其实没有换行的时候,是5bytes.
这一点在linux下,是不一样的。在linux下vi -b file,再输入:%!xxd
最后加了两个0a.
我这里没有MAC电脑,不然可以贴张图片。苹果电脑操作系统对回车换行的处理也不一样。
苹果操作系统,会是两个0d.
为什么会这样子呢?
电传打印机出现早于计算机,后来在计算机文档上面也有类似”回车,换行“的需求,因为文档不可能没有新的一行。
那时候存储器非常昂贵,早期的计算机科学家觉得应该不应该浪费这两个字符的空间。就出现了分歧。
Dos和windows采用回车+换行CR/LF表示下一行,(0d 0a)
而UNIX/Linux采用换行符LF表示下一行,(0a 0a)
苹果机(MAC OS系统)则采用回车符CR表示下一行.(0d od)
关于这个回车换行的区别,也会给文档在不同平台的显示带来不便。windows下的文档在linux打开会出现很多^M类似的。
在不同平台间使用FTP软件传送文件时, 在ascii文本模式传输模式下, 一些FTP客户端程序会自动对换行格式进行转换. 经过这种传输的文件字节数可能会发生变化. 如果你不想ftp修改原文件, 可以使用bin模式(二进制模式)传输文本.
那二进制文件与ASCII文件的区别是什么呢?第三部分再详细分析
所有字符存储的是以二进制的,那么记事本或者notepad打开这个文档的时候。首先读取文件物理上所对应的二进制比特流,然后按照你所选择的解码方式来解释这个流,然后将解释结果显示出来。那所以当编码格式与解码的格式不一致,不兼容的时候,就会出现乱码的情况。
中文编码GB2312
首先先找到一个GB2312编码表。我们理解了编码与解码就进一步想,计算机出现初期,是没有中文编码的。
如果我以二进制的编码形式编辑二进制文档,再notepad打开,选择GB2312形式解码,那就应该显示中文。
notepad打开
与GB2312表上显示一样。
那反过来,我以hex编辑器自己对照着GB2312文档编辑,那也可以写文章啊,写本小说,没问题,但是基本没有人愿意这么做吧,太累了。
文档编辑器的作用就是我们的输入,文档编辑器自动编码存储,同时打开的时候根据选择的编码系统解码并显示。
查看文档大小,占用空间6bytes .与我们常常听说一个中文字符占用两个bytes.这下我们理解为什么占用2bytes .
当然编码规范很多很多,unicode, utf8等不一而足。
我们理解了编码 是怎么回事,就可以了。
二进制文件与ASCII文件。
二进制文件与ASCII文件(文本文件)的区别在物理存储上是没有任何区别的,都是二进制。区别在于了逻辑上对于这些0101的解析。
说白了就是,这些010100等代表什么意思。
上面我们以二进制形式打开,编辑,再存储,如果我们不使用文档编辑器打开,那它就是二进制文件。
网上有一个例子,比如一个数字5678,存储在计算机里,以ASCII编码形式,那就是四个字符 5,查找ASCII表,是0x35,二进制数00110101.
依次查出来编码是00110101 00110110 00110111 00111000 。存储在存储器里。占用4个字节。
以二进制形式怎么存储,他们说是00010110 00101110 (两个字节),这个是把5678(五千六百七十八转为二进制形式表示的)。
可以这么理解,但是上面4个字节也是二进制形式的嘛,为什么不是二进制文件?如果不是文本编辑器以ASCII编码格式打开,谁也不知道这个表示的是5678.
所以说,个人认为,没有指定编码规则的二进制文件,讨论是二进制文件还是ASCII文件是无意义的。
在一定的编码规则基础上,这些编码才有意义。
我个人理解,ASCII文本文件是二进制文件下一种,确定了编码规则的文件。
这篇文章对这个问题有比较详细的讨论,链接如下
http://www.nowamagic.net/librarys/veda/detail/658
编程测试了C语言读取二进制文件,与ASCII编码的文件。在最后回车换行的地方有细微的差异。
#include <stdio.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <st
c19f
dlib.h>
int main()
{
int i;
FILE *pf1;
char c,a[6];
//pf1 = fopen("file","r");
pf1 = fopen("file.txt","rb");
for(i=0;i < 6;i++){
fread(&a[i],1,1,pf1);
printf("%0X ",a[i]);
}
fclose(pf1);//关闭文件
}文档内容就是Ab123\r\n(回车),二进制如图
一个是r 一个是rb(rb是二进制形式)
C的文本方读写与二进制读写的差别仅仅体现在回车换行符的处理上。文本方式写时,每遇到一个''n''(0AH换行符),它将其换成''r n''(0D0AH,回车换行),然后再写入文件;
当文本读取时,它每遇到一个''rn''将其反变化为''n'',然后送到读缓冲区。
所以文本形式读取时候(readfile3-r),虽然二进制编码是0d(\r) ,0a(\n),先转为\n,然后输出,所以输出是0A.
而二进制读取时候,a[5]就是0d,输出也是0d.
LINUX下测试。
由于二进制表示时候linux下只有0a,所以两种形式都是0a.
其实要说明的是UNIX和LINUX不像DOS与windows那样区分文本文件与二进制文件。
LINUX把所有文件看成二进制文件。
windows下用另外一个函数打开。
windows下用open函数打开文档,读取。
是以文件形式打开的。linux下使用这个open 函数,输出与使用file open一样。(其实也 不会有差别,因为二进制文件无差别。)

相关文章推荐
- 深入理解计算机系统(3.2)------程序编码以及数据格式
- 深入理解计算机系统(2.4)------整数的表示(无符号编码和补码编码)
- 深入理解计算机系统(2.4)------整数的表示(无符号编码和补码编码)
- 深入理解计算机系统(3.2)------程序编码以及数据格式
- 推荐一本五星好书:深入理解计算机系统(修订版)
- 深入理解计算机系统学习笔记(一)之此书简介
- 网络编程 客户端 服务端 函数 流程 图示 来自深入理解计算机系统一书 P704
- 深入理解计算机系统 - 整型运算
- 读完了csapp(中文名:深入理解计算机系统)
- 深入理解计算机系统(EN).pdf
- 深入理解计算机系统笔记
- 深入理解计算机系统TIPS(四)
- 深入理解计算机系统读书笔记之一个简单汇编程序的调试分析
- 推荐一本好书《深入理解计算机系统 Ccomputer Systems A Programmer's Perspective》
- &lt;&lt;深入理解计算机系统&gt;&gt;家庭作业3.38, 分析全过程
- 老赵书托(3):深入理解计算机系统
- 深入理解计算机系统 3.1linux中的汇编之不同(zz)
- 《深入理解计算机系统(修订版)》
- 深入理解计算机系统-第1天-第1章
- 深入理解计算机系统(修订版)