[Spark2.0]Spark SQL, DataFrames 和Datasets指南
2016-08-16 00:00
585 查看
综述
Spark SQL是Spark提供的针对结构化数据处理的模块。不同于基本的Spark RDD API,SparkSQL提供的接口提供了更多的关于数据和计算执行的信息。在内部,SparkSQL使用这些额外信息完成额外的优化。这里有几种方式可以和SparkSQL相互操作,包括SQL和DatasetAPI。计算结果的时候使用相同的执行
本页中所有示例使用到的样例的数据都包含在Spark发布中,而且都能在spark-shell,pyspark或者sparkR中运行。
SQL
Spark SQL的一种用法是执行SQL查询。Spark SQL也可以用于从已安装的Hive中读取数据。更多的关于此特性的配置,请参考HiveTables。当从内部其他编程语言执行SQL,结果将以Dataset/DataFrame形式返回。你也可以通过command-line或者JDBC/ODBC与SQL接口进行交互。
Datasets和DataFrames
Dataset是分布式数据集合。Dataset是Spark1.6新增的接口,用以提供RDDs(强类型,有使用强大的lambda函数的能力)的优点和SparkSQL的经优化的执行引擎的优点。Dataset可以从JVM对象进行构造并通过转换函数(如map,flatmap,filter等)进行操作。DatasetAPI支持Scala和Java。Python不支持Dataset
API。但因为Python本身的动态性,DatasetAPI的许多优点都已经可用(比如,你可以通过名字很自然的访问一行的某一个字段,如row.columnName),R的情况与此类似。
DataFrame是Dataset组织成命名列的形式。它在概念上相当于关系型数据库中的表,或者R/Python中的数据帧,但是在底层进行了更多的优化。DataFrames可以从多种数据源创建,例如:结构化数据文件、Hive中的表、外部数据库或者已存在的RDDs。DataFrame
API支持Scala、Java、Python和R。在Scala和Java中DataFrame其实是Dataset的RowS的形式的表示。在Scala
API中,DataFrame仅仅是Dataset[Row]的别名。但在Java中,使用者需要使用Dataset<Row>来表示一个DataFrame。
在本文档中,我们会经常将Scala/Java Dataset的RowS作为DataFrame的参考。
开始使用
起始点:SparkSession
在Spark中所有功能的切入点是SparkSession类。直接使用SparkSession.builder()就可以创建一个基本的SaprkSession:
可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala"找到完整的代码。
SparkSession是Spark2.0开始提供的内建了对Hive特性的支持,包括使用HiveQL写查询语句、调用Hive
UDFs、从Hive表读取数据的能力。你不需要事先部署Hive就能使用这些特性。
创建DataFrame
使用SparkSession,应用可以从已存在的RDD、Hive表或者Spark数据源创建DataFrame。下面的示例从一个JSON文件创建一个DataFrame:
可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala"找到完整的代码。
无类型的Dataset操作(aka
DataFrame Operations)
DataFrame在Scala、Java、Python和R中为结构化数据操作提供了一个特定领域语言支持。就像网文提到的,在Spark2.0中,在Scala和Java的API中,DataFrame仅仅是Dataset的RowS表示。与Scala/Java中的强类型的“带类型转换操作”相比,这些操作也可以看做“无类型转换操作”。
这里我们提供了一些使用Dataset进行结构化数据处理的基本示例:

可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala"找到完整的代码。
可以在Dataset上执行的操作的类型的完整列表可以参考API文档。
除了简单的列引用和表达式外,Dataset同时有丰富的函数库,包括字符串操作、日期算法、常用数学操作等。完整的列表可参考DataFrame
Function Reference。
编程执行SQL查询语句
Sparksession中的sql函数使得应用可以编程式执行SQL查询语句并且已DataFrame形式返回: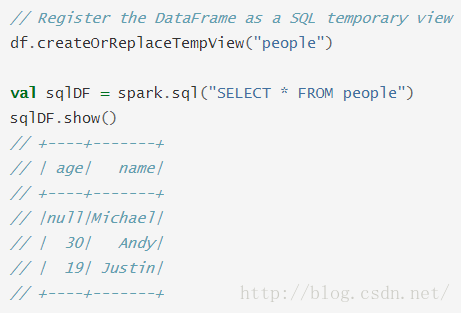
可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala"找到完整的代码。
创建Dataset
Dataset与RDD很像,不同的是它并不使用Java序列化或者Kryo,而是使用特殊的编码器来为网络间的处理或传输的对象进行序列化。对转换一个对象为字节的过程来说编码器和标准系列化器都是可靠的,编码器的代码是自动生成并且使用了一种格式,这种格式允许Spark在不需要将字节解码成对象的情况下执行很多操作,如filtering、sorting和hashing等。
可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala"找到完整的代码。
与RDD互操作
Spark SQL支持两种将已存在的RDD转化为Dataset的方法。第一种方法使用反射推断包含特定类型对象的RDD的结构。这种基于反射的方法代码更加简洁,并且当你在写Spark程序的时候已经知道RDD的结构的情况下效果很好。第二种创建Dataset的方法是通过编程接口建立一个结构,然后将它应用于一个存在的RDD。虽然这种方法更加繁琐,但它允许你在运行之前不知道其中的列和对应的类型的情况下构建Dataset。
使用反射推断结构
Spark SQL的Scala接口支持自动的将一个包含case class的RDD转换为DataFrame。这个caseclass定义了表结构。Caseclass的参数名是通过反射机制读取,然后变成列名。Caseclass可以嵌套或者包含像Seq或Array之类的复杂类型。这个RDD可以隐式的转换为一个DataFrame,然后被注册为一张表。这个表可以随后被SQL的statement使用。

可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala"in
the Spark repo. 找到完整的代码。
以编程方式指定模式
当case class不能被事先定义(比如记录的结构被编码为字符串,或者对不同的用户,文本数据集被不同的解析并进行字段投影),DataFrame可以通过以下3个步骤实现编程创建:从原始RDD创建RowS形式的RDD
以StructType创建匹配步骤1中RowS形式的RDD的模式
通过SparkSession提供的createDataFrame方法将模式应用于RowS形式的RDD
例如:
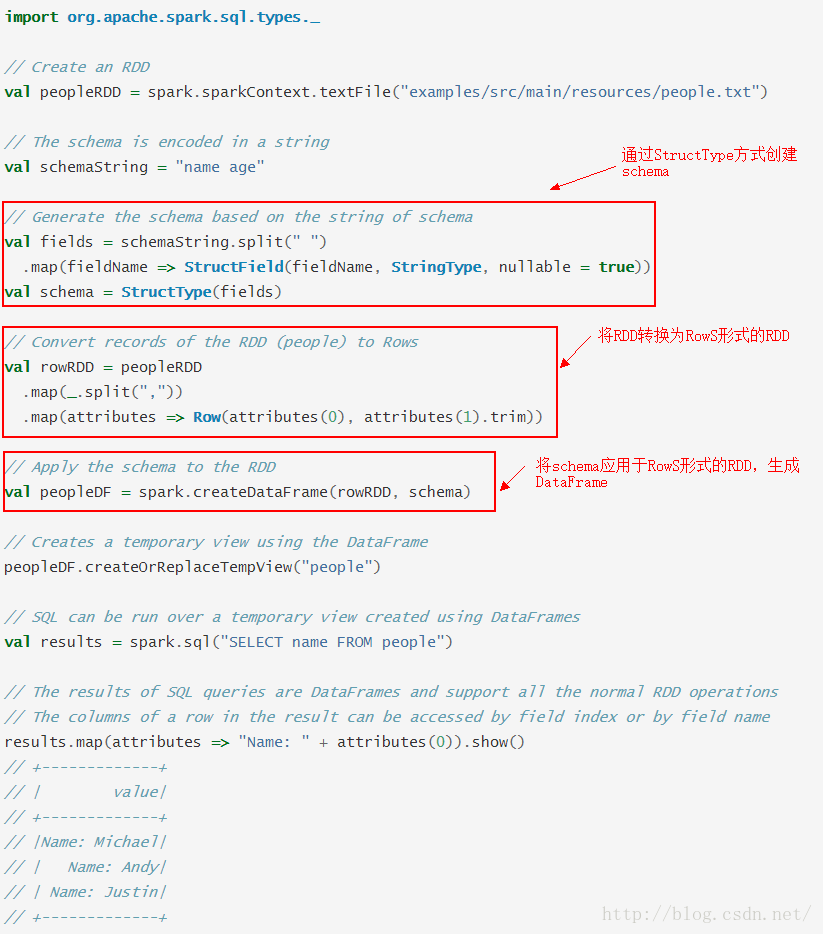
可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala"找到完整的代码。
数据源
Spark SQL通过DataFrame接口,可以支持对多种数据源的操作。DataFrame可以使用关系转换来进行操作,而且可以用来创建临时视图。将DataFrame注册为临时视图可以允许你在数据上运行SQL查询语句。本节讲解使用SparkDataSource加载数据和保存数据的通用方法,然后
详细讲述内部支持的数据源可用的特定操作。
通用Load/Save函数
最简单的,默认的数据源(parquet,除非使用spark.sql.sources.default进行了配置)将被用于所有的操作。
可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala"找到完整的代码。
手动指定选项
你可以手动指定数据源以及数据源附带的额外选项。数据源被他们的完全限定名来指定(如,org.apache.spark.sql.parquet),但对于内部支持的数据源,你可以使用短名(json,parquet,jdbc)。DataFrame可以使用这种语法从任何可以转换为其他类型的数据源加载数据。
可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala"找到完整的代码。
在文件上直接执行SQL
除了使用读取API加载一个文件到SATAFrame然后查询它的方式,你同样可以通过SQL直接查询文件。
可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala"找到完整的代码。
保存模式
保存操作可选SaveMode,它指定了如何处理现有的数据。需要重视的一点是这些保存模式没有使用任何的锁,并且不具有原子性。此外,当执行Overwrite时,数据将先被删除,然后写出新数据。| Scala/Java | 其他语言 | 含义 |
| SaveMode.ErrorIfEcists(默认) | “error”(默认) | 保存DataFrame到数据源时,如果数据已经存在,将抛出一个异常。 |
| SaveMode.Append | “append” | 保存DataFrame到数据源时,如果数据/表存在时,DataFrame的内容将追加到已存在的数据后。 当 |
| SaveMode.Overwrite | “overwrite” | Overwrite模式意味着当保存一个DataFrame到数据源时,如果数据/表已经存在,存在的数据将会被DataFrame的内容覆盖。 |
| SaveMode.Ignore | “ignore” | Ignore模式意味着当保存一个DataFrame到数据源时,如果数据已经存在,保存操作将不会保存DataFrame的内容,并且不会改变原数据。这与SQL中的CREATE TABLE IF NOT EXISTS相似。 |
保存到持久化表
也可以通过saveAsTable命令将DataFrame作为持久化表保存到Hive元数据库中。注意使用此特性时不需要事先部署Hive。Spark将为你创建一个默认的本地Hive元数据库(使用Derby)。不同于createOrReplaceTempView命令,saveAsTable将具体化DataFrame的内容并且在Hive元数据库中创建一个指向数据的指针。在你保持你的连接是到相同的元数据库时,当你的Spark程序重启后持久化表依然会存在。通过在SparkSession上使用表名调用table命令,可以创建用于持久化表的DataFrame。默认的saveAsTable将会创建一个“托管表”,意味着数据的位置酱油元数据库控制。托管表也有他们自己的数据,当对应的表被删除时这些数据会一并删除。
Parquet文件
Parquet是一种被很多其他数据处理系统支持的列式文件。SparkSQL提供了可以自动保存原始数据模式的对Parquet文件读取和写入的操作。当写入一个Parquet文件时,因为兼容性原因,所有的列都会自动转换为nullable(可为空的)。
编程式加载数据
使用上面例子的数据:
可以从Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala"找到完整的代码。
分区发现
表分区是Hive等系统中常用的优化方法。在一个分区表中,数据常常存放在不同的目录中,根据分区列的值的不同,编码了每个分区目录不同的路径。目前parquet数据源已经可以自动的发现和推断分区信息。例如,我们可以用下面的目录结构存储所有我们以前经常使用的数据到分区表,只需要额外的添加两个列gender和country作为分区列:
使用SparkSession.read.parquet或者SparkSession.read.load加载path/to/table后,Spark
SQL能够自动的从路径中提取分区信息。返回的DataFrame的模式结构是:

注意分区列的数据类型是自动推断的。目前支持数值型数据和字符串型数据。有时候用户并不想自动推断分区列的数据类型,这种情况下,可以通过配置spark.sql.sources.partitionColumnTypeInference.enabled这个参数来配置自动类型推断,默认情况下是true。当关闭类型推断后,分区列的类型将为字符串型。
从Spark1.6.0开始,在默认情况下,只在给定的路径下进行分区发现。在上述的例子中,如果用户将path/to/table/gender=male传给SparkSession.read.parquet或者SparkSession.read.load,gender将会被认为是分区列。如果用户需要指定分区发现开始的基础路径,可以将basePath设置到数据源选项。例如,当path/to/table/gender=male是数据的路径,并且用户设置basePath为path/to/table,gender将作为分区列。
模式(schema)合并
与ProtocolBuffer,Avro,和Thrift类似,Parquet同样支持schema的演变。用户可以以一个简单点的schema开始,然后在需要时逐渐的添加更多列到schema。使用这种方法,用户将最终得到由不同的但是相互兼容的schema构成的多个Parquet文件。Parquet数据源目前可以自动的检测这种情况并且合并这些文件的schema。由于合并schema是相对代价较大的操作,而且在大多数情况下并不需要这样,从1.5.0开始我们默认将它关闭,你可以通过以下方法使它生效:
在读取Parquet文件时(就像下面的例子)设置数据源操作mergeSchema为true
设置全局SQL选项spark.sql.parquet.mergeSchema为true

可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala"找到完整的代码
Hive原数据
当读写Hive元存储Parquet表时,为了更好的性能,SparkSQL将试图使用它自己支持的Parquet代替HiveSerDe。这种行为可以通过spark.sql.hive.convertMetastoreParquet进行配置,默认已经开启。
Hive/Parquet schema调节
从表的schema处理的角度来看,Hive和Parquet有两点关键的不同之处。Hive是类型敏感的,而Parquet并不是
Hive中所有列都是非空的,而Parquet中非空是很重要的特性。
因为这个原因,当我们需要将Hive元存储转换为Spark SQL Parquet表中的Parquet表时,我们需要调节Hive元存储的schema和Parquet的schema。调节规则如下:
不管是否可为空值,两种schema中具有相同名字的字段必须具有相同的数据类型。这种调节字段应该有与Parquet一方相同的数据类型,因此可为空值的特性很重要。
调节的schema准确的包含在Hive元存储schema中定义的字段。
任何只在Parquet schema中出现的字段都会在调节schema中被丢弃
任何只出现在Hive元存储schema中的字段都会在调节schema中被添加为可为空的字段
元数据更新
为了更好的性能,Spark SQL会缓存Parquet元数据。当Hive元存储Parquet表转换操作可用时,这些被转换的表的元数据同样被缓存。如果这些表被Hive或者外部工具更新,你需要手动更新元数据以保持其一致性。
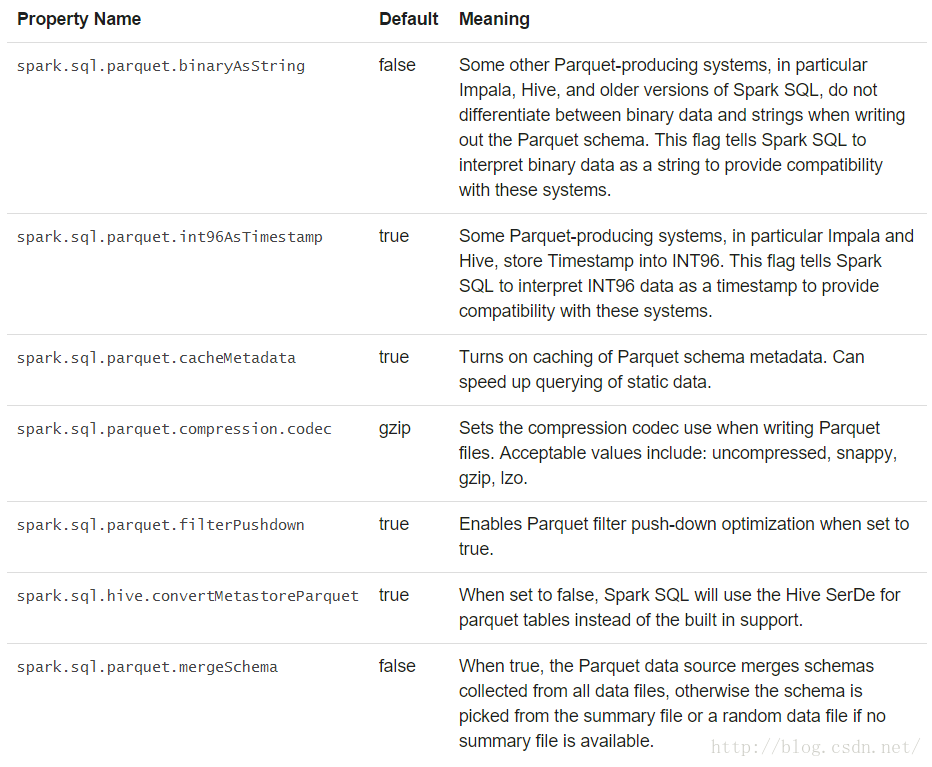
配置
Parquet的配置可以使用SparkSession中的setConf方法进行,或者使用SQL执行SETkey=value命令。
JSON数据集
Spark SQL可以自动推断JSON数据集的schema并且加载为Dataset[Row]。可以对String类型的RDD或者JSON文件使用SparkSession.read.json()来实现这种转换。注意这里的JSON文件不是通常意义的JSON文件。每一行必须包含分离的,完整有效的JSON对象。因此,不支持常用的多行式JSON文件。
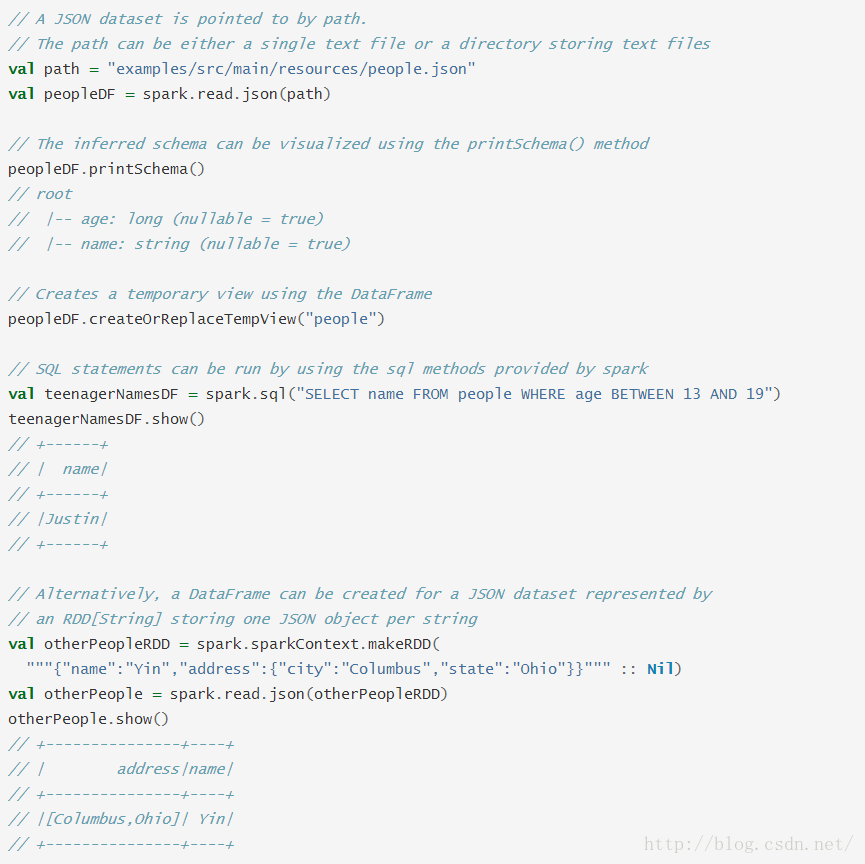
注意,RDD[String]中每一个元素必须是一个字符串形式的JSON对象。
可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala"找到完整的代码。
Hive表
Spark SQL同样支持从Apache Hive中读写数据。但是,自从Hive有大量依赖之后,这些依赖就不包括在Spark发布版中了。如果Hive的依赖可以在环境变量中找到,Spark将自动加载它们。注意这些Hive依赖项同样必须在每个worker节点上存在,因为他们需要访问Hive序列化和反序列化库以便可以访问Hive中存储的数据。配置可以在conf/目录中的hive-site.xml,
core-site.xml(安全配置),和hdfs-site.xml(HDFS配置)这几个文件中进行配置。
当在Hive上工作时,必须实例化SparkSession对Hive的支持,包括对持久化Hive元存储的连通性,对Hive序列化反序列化,Hive用户自定义函数的支持。当没有在hive-site.xml配置是,context会自动在当前目录创建metastore_db并且创建一个被spark.sql.warehouse.dir配置的目录,默认在spark应用启动的当前目录的spark-warehouse。注意从Spark2.0.0开始hive-site.xml中的hive.metastore.warehouse.dir参数被弃用。作为替代,使用spark.sql.warehouse.dir来指定仓库中数据库的位置。你可能需要授权写权限给启动spark应用的用户。


可以在Spark仓库的"examples/src/main/scala/org/apache/spark/examples/sql/hive/SparkHiveExample.scala"找到完整的代码。
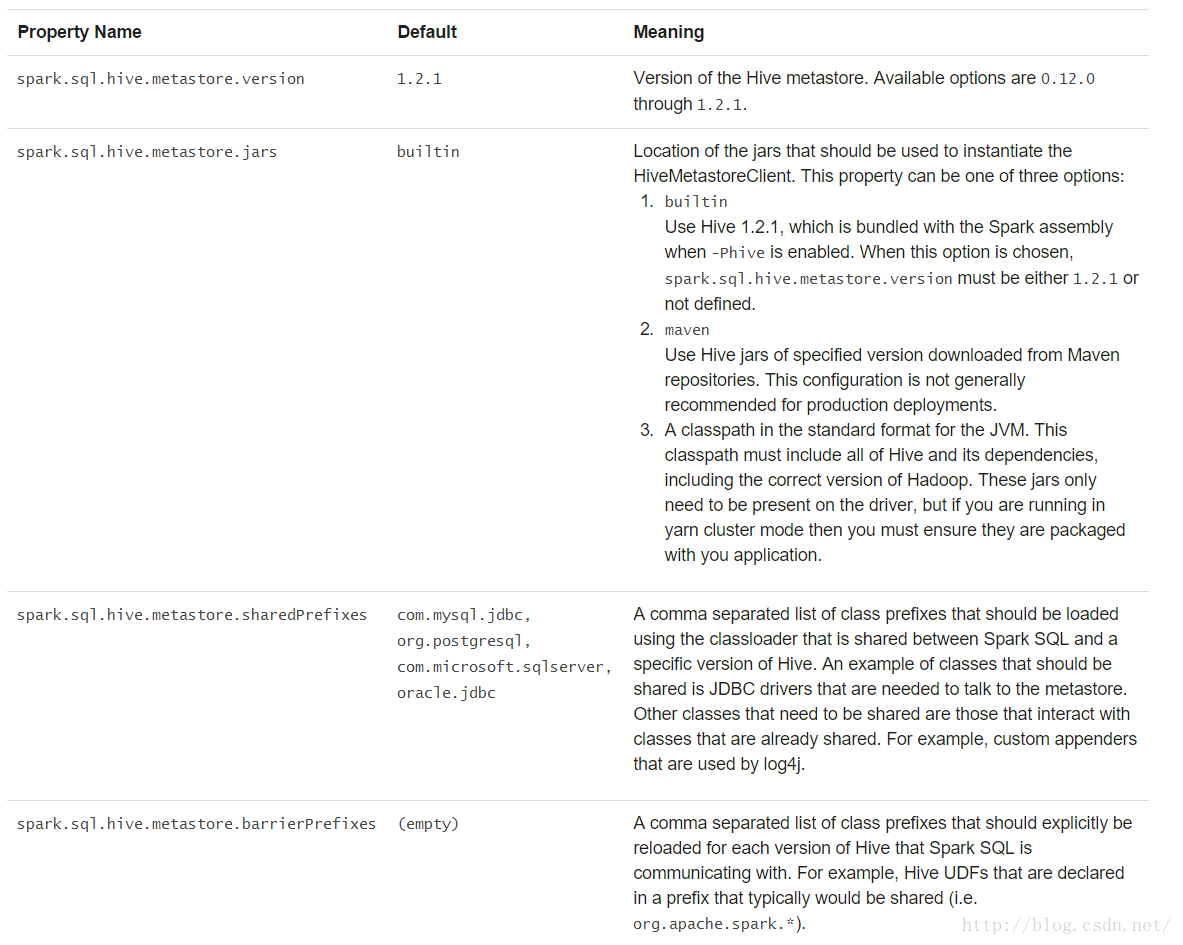
不同版本的Hive元存储的交互
Spark SQL对Hive支持的最重要的特点之一是与Hive元存储的交互,这使得SparkSQL可以访问Hive表的元数据。从Spark1.4.0开始,可以使用一个SparkSQL的二进制构建来查询不同版本的Hive元存储。Spark SQL在内部编译Hive1.2.1并且使用这些classes用于内部执行(序列化反序列化,UDFs,UDAFs等)
可以使用下面的选项来配置用于检索元数据的Hive的版本:
其他数据库的JDBC
Spark SQL同样包括可以使用JDBC从去他数据库读取数据的数据源。此功能优先使用JdbcRDD.这是因为返回的结果作为一个DataFrame并且可以轻松地使用SparkSQL处理或者与其他数据源进行连接。使用Java或者Python可以更容易的使用JDBC数据源因为它们不需要用户提供ClassTag。(注意这与Spark
SQLJDBC服务器可以允许其他应用使用Spark SQL执行查询语句不同)
在开始之前你需要将你指定的数据库的JDBC driver包含在Spark的环境变量中。例如,为了从Spark
Shell连接到postgres,你需要执行以下命令:
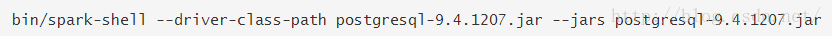
远程数据库的表可以被加载为DataFrame或者使用Data
Sources API加载为Spark SQL临时表。支持以下选项:


排错
JDBC driver类必须在客户端和所有执行器上对原始类加载器可见。这是因为Java的DriverManager类在用户打开连接时,要进行安全检查,检查其中的结果已经忽略了所有的对原始类加载器不可见的部分。一个方便的方法是更改所有worker节点的compute_classpath.sh使其包含你的driver的JAR包一些数据库,比如H2,要求将所有的名字转换为大写,你需要在Spark
SQL中使用大写。
性能调优
对一些工作负载,可以通过将数据缓存在内存中,在某些经验项上进行调优来提高性能。缓存数据到内存
Spark SQL可以通过调用 spark.cacheTable("tableName")或者dataFrame.cache()来将表以列式形式缓存在内存中。然后Spark SQL可以只扫描需要的列并且可以自动调节压缩以最小内存使用率和GC压力。你可以调用spark.uncacheTable("tableName")来将表从内存中删除。可以在SparkSession上使用setConf方法来配置内存缓存,或者使用SQL执行SET
key=value命令。

其他配置选项
下面的选项同样可以用于查询语句执行时的性能调优。在以后的发布版本中可能会弃用这些选项,更多的将优化改为自动执行。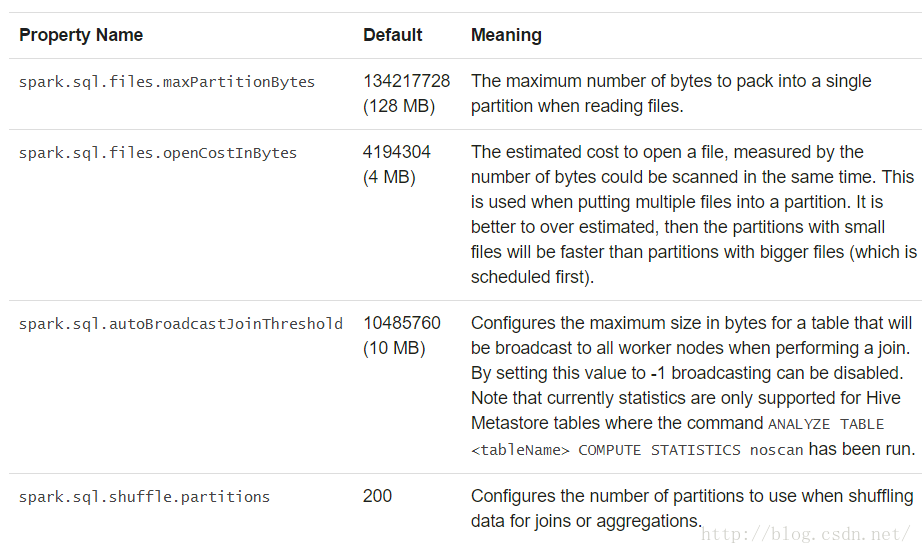
分布式SQL引擎
Spark SQL同样可以使用JDBC/ODBC或者命令行接口来作为一个分布式查询引擎。在这种模式中,终端用户或者应用可以通过执行SQL查询语句直接与SparkSQL进行交互,不需要写任何代码。
运行Thrift JDBC/ODBC服务
Thrift JDBC/ODBC服务实现了与Hive1.2.1的一致性。你可以使用任意来自Spark或者Hive1.2.1的beelinescript来测试JDBC服务。
在Spark目录中运行以下命令来启动JDBC/ODBC服务:

这个脚本接受所有bin/spark-submit的命令行选项,再加上可以执行Hive属性的
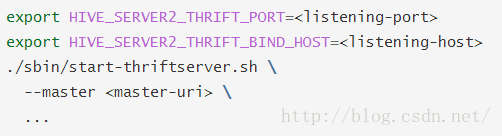
--hiveconf选项。你可以运行./sbin/start-thriftserver.sh--help来显示所有可用的选项的完整列表。默认情况下,此服务在localhost:10000进行监听。你可以通过配置环境变量来改变此运行状态,比如:
或者系统属性:

现在你可以使用beeline来测试Thrift
JDBC/ODBC服务:

在beeline中使用以下命令来连接到JDBC/ODBC:

beeline将会询问用户名和密码。在非安全模式,可以简单地在你的机器上输入用户名和空白的密码。在安全模式下,请遵照beeline
documentation中给出的说明。
Hive的配置是在conf/目录下的
hive-site.xml,core-site.xml和hdfs-site.xml文件中进行配置的。
你也可以使用来自Hive的beeline
script。
Thrift JDBC服务同样支持在HTTP传输上发送 thrift RPC消息。在系统属性或者在conf/目录中的hive-site.xml文件中进行以下设置来将模式设为HTTP模式:

在http模式中使用beeline连接到JDBC/ODBC来进行测试:

运行Spark SQL命令行界面
Spark SQL CLI是一个在本地模式下运行Hive元存储服务和执行从命令行输入的查询语句的便捷的工具。注意SparkSQL CLI和ThriftJDBC服务不能通信。
你可以在Spark目录中运行以下命令来开始Spark SQL CLI:
Hive的配置是在conf/目录下的hive-site.xml, core-site.xml和hdfs-site.xml文件中进行配置的。你可以运行./sbin/start-thriftserver.sh--help来显示所有可用的选项的完整列表。

相关文章推荐
- 【Spark 2.0官方文档】Spark SQL、DataFrames以及Datasets指南
- Spark SQL, DataFrames and Datasets(Spark-2.1.1)指南
- 《Spark 官方文档》Spark SQL, DataFrames 以及 Datasets 编程指南
- Spark SQL, DataFrames 和 Datasets 指南
- Spark -9:Spark SQL, DataFrames and Datasets 编程指南
- 《Spark 官方文档》Spark SQL, DataFrames 以及 Datasets 编程指南
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
- Spark SQL,DataFrames and DataSets Guide官方文档翻译
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
- Spark SQL, DataFrames and Datasets Guide
- Apache Spark 2.0中使用DataFrames和SQL
- 学习spark:五、Spark SQL, DataFrames and Datasets Guide
- Spark SQL, DataFrames and Datasets Guide
- 【Spark】Spark SQL, DataFrames and Datasets Guide(翻译文,持续更新)
- 在Apache Spark 2.0中使用 DataFrames 和 SQL
- Spark SQL,DataFrames and Datasets Guide
- pyspark-Spark SQL, DataFrames and Datasets Guide
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
- spark2.2官方教程笔记-Spark SQL, DataFrames and Datasets向导