JAVA爬虫挖取CSDN博客文章
2016-08-14 17:01
639 查看
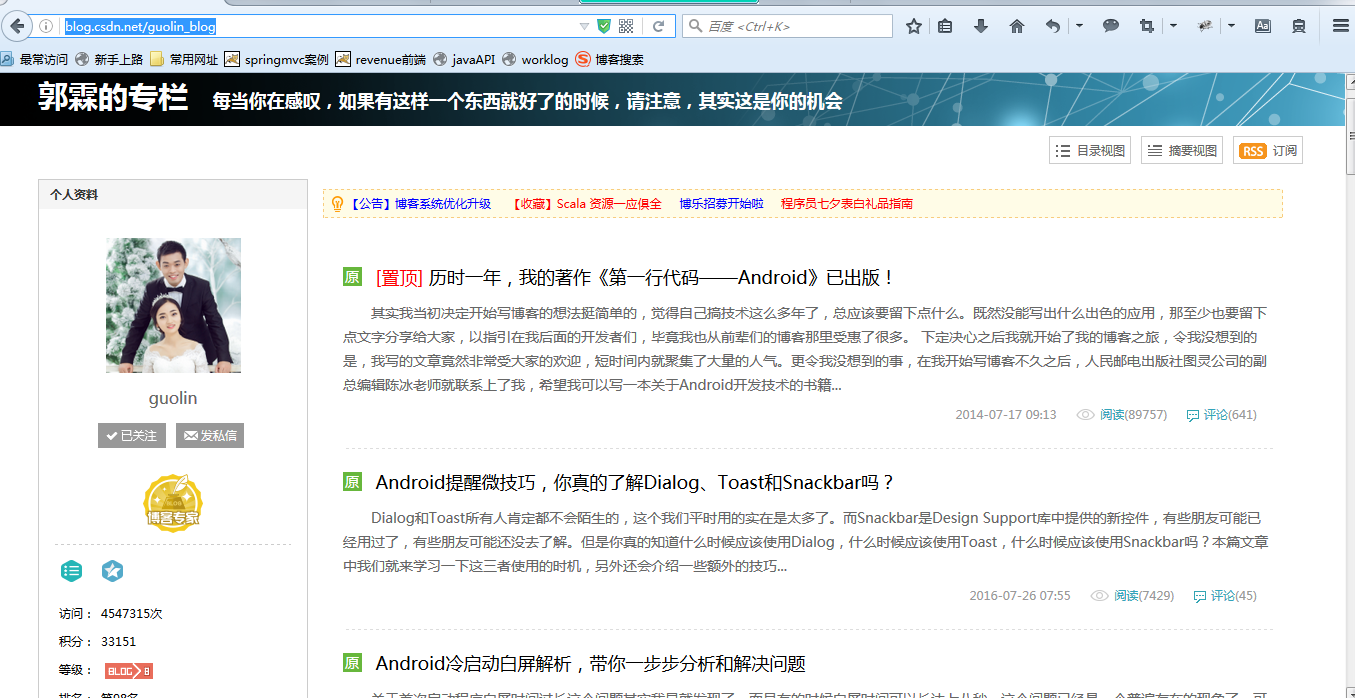
开门见山,看看这个教程的主要任务,就去csdn博客,挖取技术文章,我以《第一行代码–安卓》的作者为例,将他在csdn发表的额博客信息都挖取出来。因为郭神是我在大学期间比较崇拜的对象之一。他的csdn首页如下:http://blog.csdn.net/guolin_blog,首页如图:
你需要掌握的技术有:java se,正则表达式,js dom编程思想,jsoup,此外还需要http协议的一些知识。其中其他技术点可能你以前就掌握了,只差一个jsoup了,这个哥们是干嘛使的呢?我用一句话来说,就是Java程序获取html之后,向js,jquery一样来解析dom节点的,很多语法与js/jquery十分的相似,比如getElementById,getElemementsByClass等等语法与js相似极了,此外jsoup还有select选择器功能。所以,这里只要稍微掌握jsoup语法就可以像js操作dom一样的用Java来操作请求到的html网页了。jsoup的官方教程地址:http://www.open-open.com/jsoup/。
开始之前,你应该有一定的工具的,不如已经有一款熟练的ide来调试和查看变量,有一个web调试工具,如火狐的firebug之类的,总之,就是有一个java web程序员日常开发和调试使用的工具就差不多了。
第一步:新建一个maven项目。这个maven项目可以是一个java se项目,选择jar包就行了。重点是引入jsoup所需要的jar包。pom.xml配置如下:
第二步:新建一个带有main方法的类,当然你也可以不带main方法,不过我只是写一个java se小程序而已。(如果是配置了http代理的,按照这一步:配置http代理,这点很重要,不然请求不到html网页的,我们都知道,我们的浏览器都配置了代理了的,不然根本无法请求到html网页,不信你可以把IE浏览器的代理取消,去浏览百度一下看看)。设置http代理的代码如下:
上面ip是代理的ip地址,端口8080是代理的端口,参考的地方就是自己去IE浏览器的配置查看。
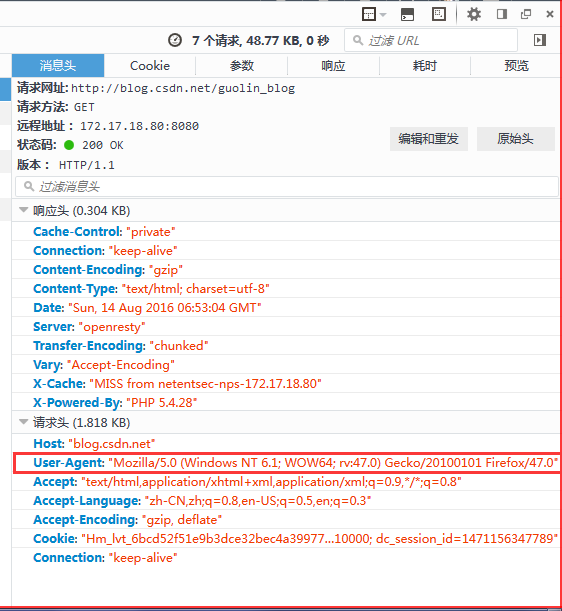
第三步:好了,如果是一般的网站,直接可以发送post或者get请求了,但是csdn还需要在http头发送几个信息,反正之前我没有发送这些头部信息,是请求不到的。用firebug分析数据,如图:
第三步:到这里,可以得到一个Connection了,接着就可以获取一个html文档了。

如图,html的内容已经加载进来了。
第四步:用jsoup获取所得到的dom节点,有必须时,还需要用到正则表达式,不过本篇博客不会用到正则。其他任务可能会用到,总之,java爬虫应该经常用到正则表达式的。
我用firebug看到所有的文章,都是显示在
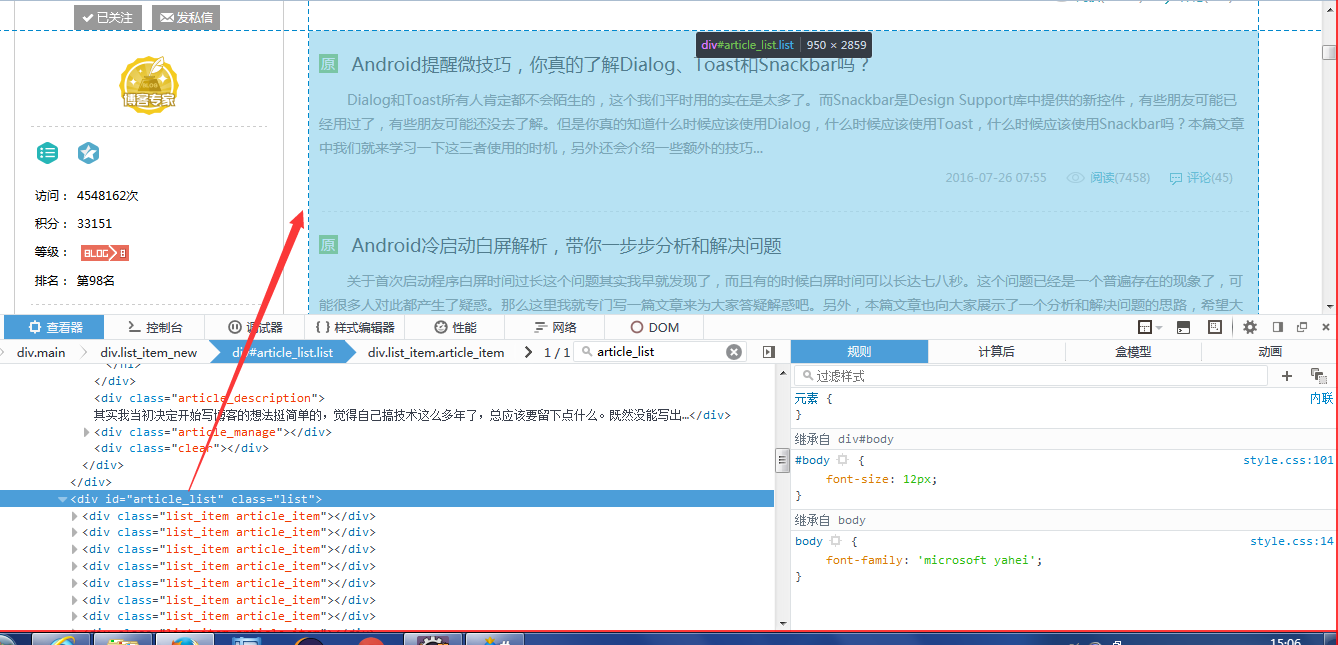
每篇文章占据的div,完整的html元素如下:
仔细分析一下,这个div中涵盖了文章的简介,阅读次数,连接地址等等,总之,这个div才是重头戏要获取的数据都在这呢。

现在可以将当前页数的文章挖掘出来了,但是郭神的技术文章不止一页啊。就是传说中的,还要进行分页挖掘,首先我们来看看我们的Java是如何做分页的。虚算法如下:
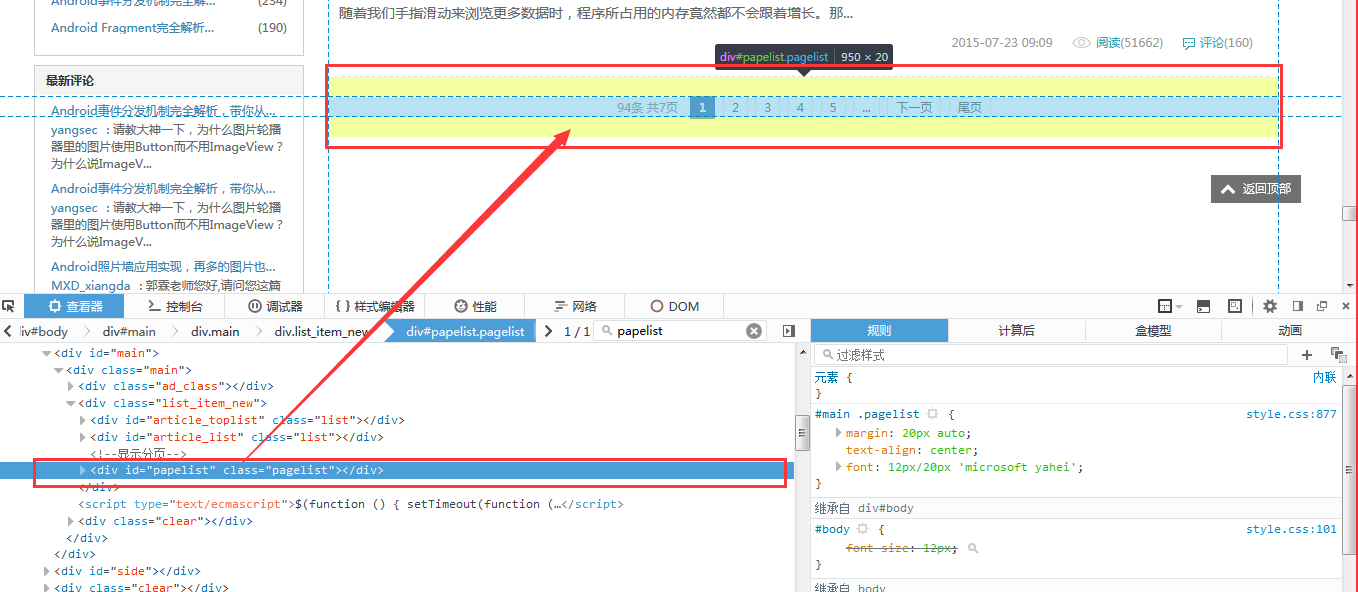
那么,我们先来获取总记录数,总页数,每页有多少技术文章吧!好在csdn的信息都放在地下的div里面了呢,来来来,我们用firebug看一看。
代码如下:
至此,就可以将郭霖的csdn技术博客都可以获取了。此时你只需要将得到的信息都封装好,在需要的时候调用就行了。
完整代码如下:
在控制台已经输出想要的信息,这里截取一段吧,
你需要掌握的技术有:java se,正则表达式,js dom编程思想,jsoup,此外还需要http协议的一些知识。其中其他技术点可能你以前就掌握了,只差一个jsoup了,这个哥们是干嘛使的呢?我用一句话来说,就是Java程序获取html之后,向js,jquery一样来解析dom节点的,很多语法与js/jquery十分的相似,比如getElementById,getElemementsByClass等等语法与js相似极了,此外jsoup还有select选择器功能。所以,这里只要稍微掌握jsoup语法就可以像js操作dom一样的用Java来操作请求到的html网页了。jsoup的官方教程地址:http://www.open-open.com/jsoup/。
开始之前,你应该有一定的工具的,不如已经有一款熟练的ide来调试和查看变量,有一个web调试工具,如火狐的firebug之类的,总之,就是有一个java web程序员日常开发和调试使用的工具就差不多了。
第一步:新建一个maven项目。这个maven项目可以是一个java se项目,选择jar包就行了。重点是引入jsoup所需要的jar包。pom.xml配置如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.shizongger.jsoup</groupId> <artifactId>jsoup-shizongger</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <dependency> <!-- jsoup HTML parser library @ http://jsoup.org/ --> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.9.2</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.1</version> </dependency> <dependency> <groupId>org.mockito</groupId> <artifactId>mockito-all</artifactId> <version>1.8.4</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.6</source> <target>1.6</target> </configuration> </plugin> </plugins> </build> </project>
第二步:新建一个带有main方法的类,当然你也可以不带main方法,不过我只是写一个java se小程序而已。(如果是配置了http代理的,按照这一步:配置http代理,这点很重要,不然请求不到html网页的,我们都知道,我们的浏览器都配置了代理了的,不然根本无法请求到html网页,不信你可以把IE浏览器的代理取消,去浏览百度一下看看)。设置http代理的代码如下:
System.setProperty("http.maxRedirects", "50");
System.getProperties().setProperty("proxySet", "true");
// 如果不设置,只要代理IP和代理端口正确,此项不设置也可以
String ip = "代理服务器地址";
System.getProperties().setProperty("http.proxyHost", ip);
System.getProperties().setProperty("http.proxyPort", "代理的端口");上面ip是代理的ip地址,端口8080是代理的端口,参考的地方就是自己去IE浏览器的配置查看。
第三步:好了,如果是一般的网站,直接可以发送post或者get请求了,但是csdn还需要在http头发送几个信息,反正之前我没有发送这些头部信息,是请求不到的。用firebug分析数据,如图:
private static final String URL = "http://blog.csdn.net/guolin_blog";
Connection conn = Jsoup.connect(URL)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:47.0) Gecko/20100101 Firefox/47.")
.timeout(30000)
.method(Connection.Method.GET);第三步:到这里,可以得到一个Connection了,接着就可以获取一个html文档了。
Document doc = conn.get();
如图,html的内容已经加载进来了。
第四步:用jsoup获取所得到的dom节点,有必须时,还需要用到正则表达式,不过本篇博客不会用到正则。其他任务可能会用到,总之,java爬虫应该经常用到正则表达式的。
我用firebug看到所有的文章,都是显示在
<div id="article_list" class="list"></div>内,而每篇文章都是在这个div下面的这个div:
<div class="list_item article_item">,
每篇文章占据的div,完整的html元素如下:
<div class="list_item article_item"> <div class="article_title"> <span class="ico ico_type_Original"></span> <h1> <span class="link_title"><a href="/guolin_blog/article/details/51336415"> Android提醒微技巧,你真的了解Dialog、Toast和Snackbar吗? </a></span> </h1> </div> <div class="article_description"> Dialog和Toast所有人肯定都不会陌生的,这个我们平时用的实在是太多了。而Snackbar是Design Support库中提供的新控件,有些朋友可能已经用过了,有些朋友可能还没去了解。但是你真的知道什么时候应该使用Dialog,什么时候应该使用Toast,什么时候应该使用Snackbar吗?本篇文章中我们就来学习一下这三者使用的时机,另外还会介绍一些额外的技巧... </div> <div class="article_manage"> <span class="link_postdate">2016-07-26 07:55</span> <span class="link_view" title="阅读次数"><a href="/guolin_blog/article/details/51336415" title="阅读次数">阅读</a>(7458)</span> <span class="link_comments" title="评论次数"><a href="/guolin_blog/article/details/51336415#comments" title="评论次数" onclick="_gaq.push(['_trackEvent','function', 'onclick', 'blog_articles_pinglun'])">评论</a>(45)</span> </div> <div class="clear"></div> </div>
仔细分析一下,这个div中涵盖了文章的简介,阅读次数,连接地址等等,总之,这个div才是重头戏要获取的数据都在这呢。
public static List<ArticleEntity> getArtitcleByPage(int pageNow) throws IOException{
Connection conn = Jsoup.connect(URL + "/article/list/" + pageNow)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:47.0) Gecko/20100101 Firefox/47.")
.timeout(30000)
.method(Connection.Method.GET);
Document doc = conn.get();
Element body = doc.body();
List<ArticleEntity> resultList = new ArrayList<ArticleEntity>();
Element articleListDiv = body.getElementById("article_list");
Elements articleList = articleListDiv.getElementsByClass("list_item");
for(Element article : articleList){
ArticleEntity articleEntity = new ArticleEntity();
Element linkNode = (article.select("div h1 a")).get(0);
Element desptionNode = (article.getElementsByClass("article_description")).get(0);
Element articleManageNode = (article.getElementsByClass("article_manage")).get(0);
articleEntity.setAddress(linkNode.attr("href"));
articleEntity.setTitle(linkNode.text());
articleEntity.setDesption(desptionNode.text());
articleEntity.setTime(articleManageNode.select("span:eq(0").text());
resultList.add(articleEntity);
}
return resultList;
}现在可以将当前页数的文章挖掘出来了,但是郭神的技术文章不止一页啊。就是传说中的,还要进行分页挖掘,首先我们来看看我们的Java是如何做分页的。虚算法如下:
分页存储过程或者页面分页中的分页算法: int pagesize // 每页记录数 int recordcount // 总记录数 int pagecount // 总页数 pagecount=(recordcount+pagesize-1)/pagesize 此方法得出的结果为实际页码 pagecount=(recordcount-1)/pagesize 此方法得出的结果为实际页码-1 注:两个整数相除的结果始终是整数。例如:5除以2的结果为2。若要确定5除以2的余数,请使用modulo运算符(%)。若要获取作为有理数或分数的商,应将被除数或除数设置为float或double型。可以通过在数字后添加一个小数点来隐式执行此操作
那么,我们先来获取总记录数,总页数,每页有多少技术文章吧!好在csdn的信息都放在地下的div里面了呢,来来来,我们用firebug看一看。
<div id="papelist" class="pagelist"> <span> 94条 共7页</span><strong>1</strong> <a href="/sinyu890807/article/list/2">2</a> <a href="/sinyu890807/article/list/3">3</a> <a href="/sinyu890807/article/list/4">4</a> <a href="/sinyu890807/article/list/5">5</a> <a href="/sinyu890807/article/list/6">...</a> <a href="/sinyu890807/article/list/2">下一页</a> <a href="/sinyu890807/article/list/7">尾页</a> </div>
代码如下:
private int totalPage;
private int nowPage;
/**
* despt:分页算法
* @return
* @throws IOException
*/
public List<ArticleEntity> goPage() throws IOException{
Connection conn = Jsoup.connect(URL)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:47.0) Gecko/20100101 Firefox/47.")
.timeout(30000)
.method(Connection.Method.GET);
Document doc = conn.get();
Element body = doc.body();
//获取总页数
String totalPage = body.getElementById("papelist").select("span:eq(0)").text();
String regex = ".+共(\\d+)页";
totalPage = totalPage.replaceAll(regex, "$1");
this.totalPage = Integer.parseInt(totalPage);
this.nowPage = 1;
List<ArticleEntity> list = new ArrayList<ArticleEntity>();
for(nowPage = 1; this.nowPage <= this.totalPage; this.nowPage++){
list.addAll(getArtitcleByPage(this.nowPage));
}
return list;
}至此,就可以将郭霖的csdn技术博客都可以获取了。此时你只需要将得到的信息都封装好,在需要的时候调用就行了。
完整代码如下:
public class ArticleEntity {
/**
* ���µ�ַ����Ե�ַ
*/
private String address;
/**
* ���±���
*/
private String title;
/**
* ��������
*/
private String desption;
/**
* ����ʱ��
*/
private String time;
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getDesption() {
return desption;
}
public void setDesption(String desption) {
this.desption = desption;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
}import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.*;
import com.shizongger.entity.ArticleEntity;
public class MyBlog {
private static final String URL = "http://blog.csdn.net/guolin_blog";
private int totalPage;
private int nowPage;
public static void main(String[] args) {
System.setProperty("http.maxRedirects", "50");
System.getProperties().setProperty("proxySet", "true");
// 如果不设置,只要代理IP和代理端口正确,此项不设置也可以
String ip = "172.17.18.80";
System.getProperties().setProperty("http.proxyHost", ip);
System.getProperties().setProperty("http.proxyPort", "8080");
MyBlog demo = new MyBlog();
try {
List<ArticleEntity> list = demo.goPage();
for(ArticleEntity tmp : list) {
System.out.println("文章地址:" + tmp.getAddress());
System.out.println("文章标题:" + tmp.getTitle());
System.out.println("文章简介:" + tmp.getDesption());
System.out.println("发表时间:" + tmp.getTime());
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* despt:分页算法
* @return
* @throws IOException
*/
public List<ArticleEntity> goPage() throws IOException{
Connection conn = Jsoup.connect(URL)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:47.0) Gecko/20100101 Firefox/47.")
.timeout(30000)
.method(Connection.Method.GET);
Document doc = conn.get();
Element body = doc.body();
//获取总页数
String totalPage = body.getElementById("papelist").select("span:eq(0)").text();
String regex = ".+共(\\d+)页";
totalPage = totalPage.replaceAll(regex, "$1");
this.totalPage = Integer.parseInt(totalPage);
this.nowPage = 1;
List<ArticleEntity> list = new ArrayList<ArticleEntity>();
for(nowPage = 1; this.nowPage <= this.totalPage; this.nowPage++){
list.addAll(getArtitcleByPage(this.nowPage));
}
return list;
}
public static List<ArticleEntity> getArtitcleByPage(int pageNow) throws IOException{
Connection conn = Jsoup.connect(URL + "/article/list/" + pageNow)
.userAgent("Mozilla/5.0 (Windows NT 6.1; rv:47.0) Gecko/20100101 Firefox/47.")
.timeout(30000)
.method(Connection.Method.GET);
Document doc = conn.get();
Element body = doc.body();
List<ArticleEntity> resultList = new ArrayList<ArticleEntity>();
Element articleListDiv = body.getElementById("article_list");
Elements articleList = articleListDiv.getElementsByClass("list_item");
for(Element article : articleList){
ArticleEntity articleEntity = new ArticleEntity();
Element linkNode = (article.select("div h1 a")).get(0);
Element desptionNode = (article.getElementsByClass("article_description")).get(0);
Element articleManageNode = (article.getElementsByClass("article_manage")).get(0);
articleEntity.setAddress(linkNode.attr("href"));
articleEntity.setTitle(linkNode.text());
articleEntity.setDesption(desptionNode.text());
articleEntity.setTime(articleManageNode.select("span:eq(0").text());
resultList.add(articleEntity);
}
return resultList;
}
}在控制台已经输出想要的信息,这里截取一段吧,
文章地址:/guolin_blog/article/details/51336415 文章标题:Android提醒微技巧,你真的了解Dialog、Toast和Snackbar吗? 文章简介:Dialog和Toast所有人肯定都不会陌生的,这个我们平时用的实在是太多了。而Snackbar是Design Support库中提供的新控件,有些朋友可能已经用过了,有些朋友可能还没去了解。但是你真的知道什么时候应该使用Dialog,什么时候应该使用Toast,什么时候应该使用Snackbar吗?本篇文章中我们就来学习一下这三者使用的时机,另外还会介绍一些额外的技巧... 发表时间:2016-07-26 07:55

相关文章推荐
- JAVA爬虫挖取CSDN博客文章
- JAVA爬虫挖取CSDN博客文章(续)
- java爬虫小项目-挖取CSDN博客文章
- CSDN博客文章之JavaWeb框架资源
- 【Python脚本】-爬虫得到CSDN博客的文章访问量和评论量
- Java网络编程(一) - Java网页爬虫 - 爬取自己的CSDN博客标题和阅读数(附源码)
- C/C++ | Qt 实现爬虫功能,爬取CSDN博客文章
- python爬虫之python2.7.8抓取csdn博客文章
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
- 【CSDN博客精品文章,佟强】深刻理解Java编程的7个例子
- java实现CSDN博客迁移到WordPress爬虫工具
- 自动检测CSDN博客文章阅读次数的爬虫
- Hello Python!用python写一个抓取CSDN博客文章的简单爬虫
- Python爬虫自动获取CSDN博客收藏文章
- 【CSDN博客精品文章,佟强】深刻理解Java编程的7个例子
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
- 如何用Live Writer发表Csdn 博客文章
- 如何使用live writer客户端来发布CSDN的博客文章?
- 我的csdn博客的第一篇文章