【深度学习】A neural algorithm of artistic style算法详解
2016-08-07 11:45
260 查看
Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. “A neural algorithm of artistic style.” arXiv preprint arXiv:1508.06576 (2015).
下面这篇发表于CVPR16,内容类似,排版更便于阅读。
Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. “Image Style Transfer Using Convolutional Neural Networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- 基于Torch的Neural-Style
- 基于Tensorflow的Neural Art
- 基于Caffe的Style Transfer。
本文的核心思路如下:
- 使用现成的识别网络,提取图像不同层级的特征。
- 低层次响应描述图像的风格,高层次响应描述图像的内容。
- 使用梯度下降方法,可以调整输入响应,在特定层次获得特定的响应。
- 多次迭代之后,输入响应即为特定风格和内容的图像。
【辨】一般网络层有如下形式
xt+1=f(Wxt+b)
网络的权重W,网络的响应xt+1。
特别要强调的是,常见的深度学习问题利用输入-输出样本对训练网络的权重。这篇文章中,是利用已经训练好的权重,获取一个符合输出要求的输入。
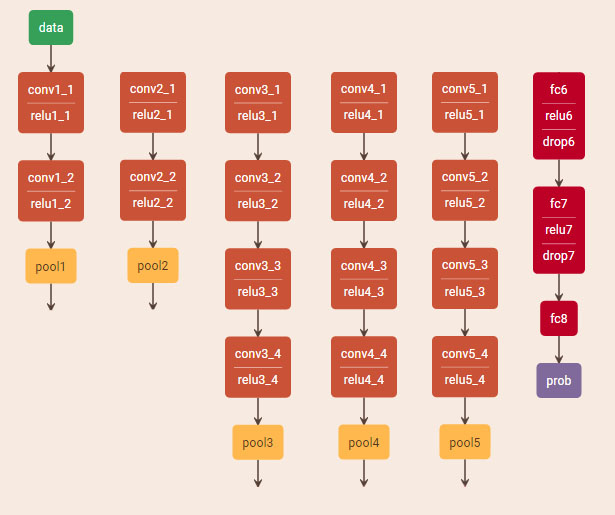
网络不同层次的响应描述了图像不同层次的信息:低层次描述小范围的边角、曲线,中层次描述方块、螺旋,高层次描述内容。
下文在提到“卷积层”时,实际指的是Conv+ReLU的复合体。用惯了Torch的同学尤其注意。
对于目标图像X0¯¯¯¯¯,同样送入该网络,可以得到该层响应Xl¯¯¯¯。
若希望X0和X0¯¯¯¯¯内容相似,可以最小化如下二范数误差:
Elc=12||Xl−Xl¯¯¯¯||2
这一误差可以对本层响应的每一元素求导2:
∂Elc∂xlhwk=xhwk−xhwk¯¯¯¯¯¯
h=1,2...H,w=1,2...W,k=1,2...N
进一步,利用链式法则,可以求得误差对输入图像每一元素的导数∂Elc/∂x0hwk。这一步骤就是神经网络经典的back-propagation方法。
利用∂Elc/∂X0来更新X0,可以获得一个新的输入图像,其在第l层的响应Xl更接近目标图像的响应Xl¯¯¯¯。也就是说:和目标图像的内容更接近。
Glij=∑hwxlhwi⋅xlhwj
i=1,2...N,j=1,2...N
Gl由第l层的响应计算而来,但是消除了响应的位置信息,可以看做对于风格的描述。ij位置的元素描述第i通道响应和第j通道响应的相关性。
对于目标图像相应层的风格Gl¯¯¯¯,最小化如下误差可以使X0和X0¯¯¯¯¯的风格近似:
Els=12||Gl−Gl¯¯¯¯||2
可以求得误差对本层响应的导数:
∂Els∂xlhwk=(Xl)T(Gl−Gl¯¯¯¯)ji
同样可以通过back-propagation求得∂Els/∂X0,进而更新X0使其风格接近X0¯¯¯¯¯。
内容层 - conv4_2
风格层 - conv1_1, conv2_1, conv3_1, conv4_1, conv5_1
当风格误差权重很高时,得到的结果近似风格图像的纹理。

这告诉我们:风格本身也是非常抽象的概念,需要较深的网络来描述。
- 深度学习不只是一头进一头出的“香肠工厂”。
-“识别”这个看似无关的高层任务包含了很丰富的信息。
我们并不需要特别训练,就能够欣赏非写实风格的绘画,识别其中的对象,辨认画家的风格。这说明人类在认识真实世界的过程中,就学习到了分别提取“内容”和“风格”的能力。
同样的,以真实世界物体训练的识别神经网络,也自然地能够分别提取“内容”和“风格”。
想要亲自体验的同学,可以使用DeepArt网站提交自己的风格图像和内容图像,不过免费版本需要等待几天。网站还提供了其他用户的精彩作品可以欣赏。
2016年夏季在俄罗斯大热的照片滤镜Prisma同样实现风格转移,只需等待几十秒到若干分钟,8月份的更新更是支持移动端的离线运算,不过其提速依赖于另外的论文。
在处理视频时,这篇文章考虑了结果的连续性和稳定性,这里有基于Torch的实现。
K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556 [cs], Sept. 2014. arXiv: 1409.1556. 3 ↩
原文此处似乎混淆了非线性运算之前和之后的响应。 ↩
下面这篇发表于CVPR16,内容类似,排版更便于阅读。
Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. “Image Style Transfer Using Convolutional Neural Networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
概述
本文介绍Leon Gatys在2016年初大热的Style Transfer算法。这一算法结果直观,理论简洁,广受人民群众喜爱,在github上有各种平台的源码实现:- 基于Torch的Neural-Style
- 基于Tensorflow的Neural Art
- 基于Caffe的Style Transfer。
本文的核心思路如下:
- 使用现成的识别网络,提取图像不同层级的特征。
- 低层次响应描述图像的风格,高层次响应描述图像的内容。
- 使用梯度下降方法,可以调整输入响应,在特定层次获得特定的响应。
- 多次迭代之后,输入响应即为特定风格和内容的图像。
【辨】一般网络层有如下形式
xt+1=f(Wxt+b)
网络的权重W,网络的响应xt+1。
特别要强调的是,常见的深度学习问题利用输入-输出样本对训练网络的权重。这篇文章中,是利用已经训练好的权重,获取一个符合输出要求的输入。
复习:分类网络
直接使用VGG191分类网络(下图省略了末尾处做分类的几层)。和原始分类网络相比,本文仅将max pooling换成了average pooling,略微提升结果视效。网络不同层次的响应描述了图像不同层次的信息:低层次描述小范围的边角、曲线,中层次描述方块、螺旋,高层次描述内容。
下文在提到“卷积层”时,实际指的是Conv+ReLU的复合体。用惯了Torch的同学尤其注意。
图像中的信息
使用分类网络中卷积层的响应来表达图像的风格和内容。内容:响应
任取一张图像X0,将其输入上述分类网络。其第l个卷积层的响应记为Xl,其尺寸是Hl×Wl×Nl。对于目标图像X0¯¯¯¯¯,同样送入该网络,可以得到该层响应Xl¯¯¯¯。
若希望X0和X0¯¯¯¯¯内容相似,可以最小化如下二范数误差:
Elc=12||Xl−Xl¯¯¯¯||2
这一误差可以对本层响应的每一元素求导2:
∂Elc∂xlhwk=xhwk−xhwk¯¯¯¯¯¯
h=1,2...H,w=1,2...W,k=1,2...N
进一步,利用链式法则,可以求得误差对输入图像每一元素的导数∂Elc/∂x0hwk。这一步骤就是神经网络经典的back-propagation方法。
利用∂Elc/∂X0来更新X0,可以获得一个新的输入图像,其在第l层的响应Xl更接近目标图像的响应Xl¯¯¯¯。也就是说:和目标图像的内容更接近。
风格:响应的矩阵积
先引入一个Nl×Nl的特征矩阵Gl:Glij=∑hwxlhwi⋅xlhwj
i=1,2...N,j=1,2...N
Gl由第l层的响应计算而来,但是消除了响应的位置信息,可以看做对于风格的描述。ij位置的元素描述第i通道响应和第j通道响应的相关性。
对于目标图像相应层的风格Gl¯¯¯¯,最小化如下误差可以使X0和X0¯¯¯¯¯的风格近似:
Els=12||Gl−Gl¯¯¯¯||2
可以求得误差对本层响应的导数:
∂Els∂xlhwk=(Xl)T(Gl−Gl¯¯¯¯)ji
同样可以通过back-propagation求得∂Els/∂X0,进而更新X0使其风格接近X0¯¯¯¯¯。
实验
以高斯噪声为初始输入图像,优化内容+风格的混合误差,多次执行前向/后向迭代使用L-BFGS方法优化,即可实现style transfer。其中:内容层 - conv4_2
风格层 - conv1_1, conv2_1, conv3_1, conv4_1, conv5_1
权重
内容误差与风格误差的权重设为α,β,两者之比从1×10−3到5×10−4,五个风格层权重相同。当风格误差权重很高时,得到的结果近似风格图像的纹理。
风格层
和直觉相反,风格误差可以包含非常高的卷积层(conv5_1),反而有更自然,更“神似”的视觉效果。这告诉我们:风格本身也是非常抽象的概念,需要较深的网络来描述。
速度
由于需要反复迭代,本文算法的速度很慢。512×512图像,使用NVIDIA K40 GPU,需要近1小时完成。总结
这篇文章颇有一些启发:- 深度学习不只是一头进一头出的“香肠工厂”。
-“识别”这个看似无关的高层任务包含了很丰富的信息。
我们并不需要特别训练,就能够欣赏非写实风格的绘画,识别其中的对象,辨认画家的风格。这说明人类在认识真实世界的过程中,就学习到了分别提取“内容”和“风格”的能力。
同样的,以真实世界物体训练的识别神经网络,也自然地能够分别提取“内容”和“风格”。
想要亲自体验的同学,可以使用DeepArt网站提交自己的风格图像和内容图像,不过免费版本需要等待几天。网站还提供了其他用户的精彩作品可以欣赏。
2016年夏季在俄罗斯大热的照片滤镜Prisma同样实现风格转移,只需等待几十秒到若干分钟,8月份的更新更是支持移动端的离线运算,不过其提速依赖于另外的论文。
在处理视频时,这篇文章考虑了结果的连续性和稳定性,这里有基于Torch的实现。
K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556 [cs], Sept. 2014. arXiv: 1409.1556. 3 ↩
原文此处似乎混淆了非线性运算之前和之后的响应。 ↩

相关文章推荐
- MSIL深度挖掘(1) 学习笔记
- 深度,广度,如何把握学习的“度” ?
- 嵌入式linux c 学习笔记4-深度优先搜索和广义优先搜索
- 学习:深度和广度之谈
- 深度探索c++学习笔记
- 分享《21个项目玩转深度学习:基于TensorFlow的实践详解》PDF+源代码
- 由布局学习CSS——浮动清除的深度探究(hasLayout和BFC对浮动的影响)
- c++中的几个转换数据类型的深度学习
- ASP.NET温故而知新学习系列之深度剖析ASP.NET架构—HttpModule(二)
- [学习笔记]C语言深度剖析
- Castle ActiveRecord学习实践(10):深度分析Schema Pitfals
- 我的opengl编程学习(二)(混合、深度测试、雾化、多边形平移、显示列表)
- 【转】我的opengl编程学习(二)(混合、深度测试、雾化、
- C++学习(四) 深度剖析堆与栈
- 转一篇学习多线程的好文!绝对有深度!
- Castle ActiveRecord学习实践(10):深度分析Schema Pitfals
- 数据结构学习_图(1)深度优先搜索、广度优先搜索和最小生成树
- JAVA学习提高之----简单克隆与深度克隆的思考
- C语言深度剖析学习心得之关键字
- java 动态代理深度学习