动态上下线datanode节点及副本均衡机制
2016-08-06 14:30
337 查看
本篇博客继hadoop-2.4.1 HA 分布式集群安装部署,现在我们的状态如下:
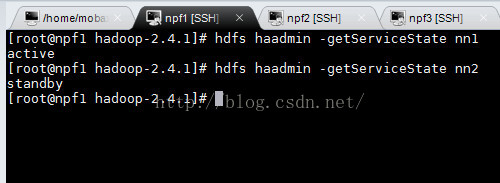
此时我们的集群是好的。
1.现在我们通过Java程序向HDFS提交文件。
core-site.xml
hdfs-site.xml
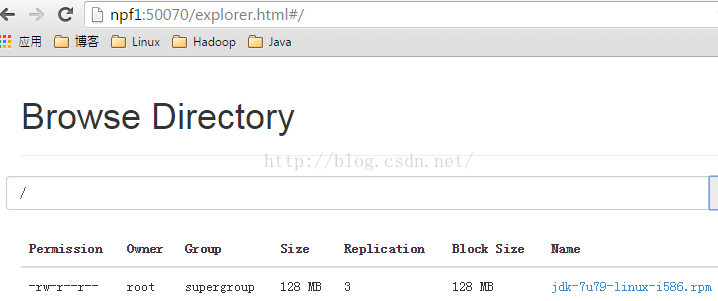
现在我们运行HdfsApp.java,然后访问http://npf1:50070
2.现在我们测试,如果在上传文件的过程中,active namenode故障了,上传文件的过程会被中断么?
现在我们的npf1是active namenode,npf2是standby namenode。
现在我们运行程序,上传jkd-7u79,在上传的过程了,kill 掉npf1 上面的namenode进程。
运行的过程中:
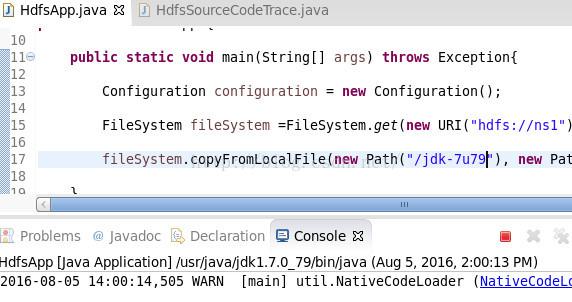
kill 掉npf1上面的namenode进程:
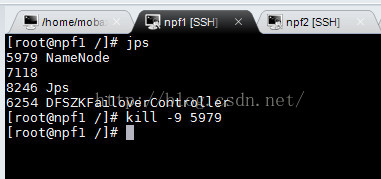
然后访问http://npf2:50070
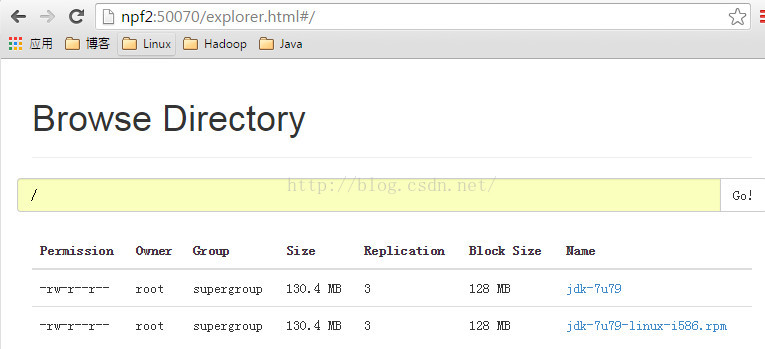
结果表明:
即使在上传的过程中,namenode发生了故障,standby namenode上面的zkfc会检测到active namenode故障,然后standy namenode通过zkfc向npf1发生SSH kill的指令,已确定npf1的namenode确实已经被kill掉了,然后standby namenode会切换成active namenode,对外提供服务。
3.动态增加一个datanode节点
分别修改npf1,npf2,npf3,npf4,npf5,npf6,npf7,npf8下面的/etc/hosts
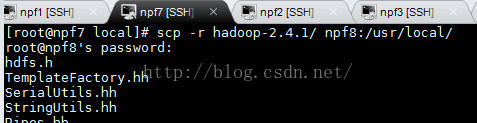
我们的JDK已经安装完毕,现在只要安装hadoop就可以了,在npf7上面,运行下面的命令,将npf7上面的hadoop环境拷贝到npf8上面。
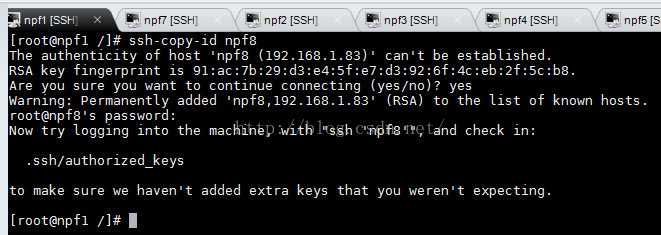
分别配置npf1,npf2到npf8的免密码登录
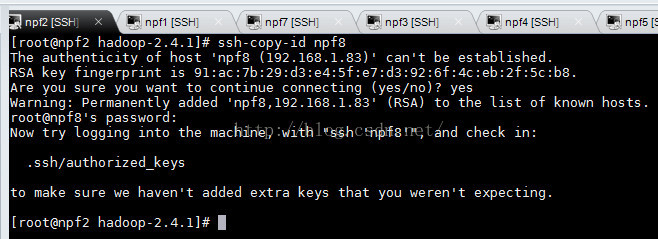
在npf8上面启动datanode启动之前,我们来看下现在的datanode的活动数目:

在npf8上面启动datanode:
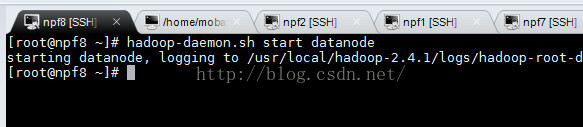
现在我们再来看下datanode的活动数目:

已经有4个了,说明我们的npf8的datanode已经被集群感知了。
此时我们的集群是好的。
1.现在我们通过Java程序向HDFS提交文件。
package com.npf.hadoop;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HdfsApp {
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://ns1/"), configuration);
fileSystem.copyFromLocalFile(new Path("/flowcount.jar"), new Path("/"));
}
}并且在classpath下面添加下面两个配置文件:core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定hdfs的nameservice为ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-2.4.1/tmp</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>npf5:2181,npf6:2181,npf7:2181</value> </property> </configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name><value>ns1</value> </property> <!-- ns1下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns1</name><value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>npf1:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>npf1:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>npf2:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>npf2:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://npf5:8485;npf6:8485;npf7:8485/ns1</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/hadoop-2.4.1/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>
现在我们运行HdfsApp.java,然后访问http://npf1:50070
2.现在我们测试,如果在上传文件的过程中,active namenode故障了,上传文件的过程会被中断么?
现在我们的npf1是active namenode,npf2是standby namenode。
现在我们运行程序,上传jkd-7u79,在上传的过程了,kill 掉npf1 上面的namenode进程。
运行的过程中:
kill 掉npf1上面的namenode进程:
然后访问http://npf2:50070
结果表明:
即使在上传的过程中,namenode发生了故障,standby namenode上面的zkfc会检测到active namenode故障,然后standy namenode通过zkfc向npf1发生SSH kill的指令,已确定npf1的namenode确实已经被kill掉了,然后standby namenode会切换成active namenode,对外提供服务。
3.动态增加一个datanode节点
| 主机名 | IP | 安装的软件 | 运行的进程 |
| npf8 | 192.168.1.83 | jdk、hadoop | DataNode |
我们的JDK已经安装完毕,现在只要安装hadoop就可以了,在npf7上面,运行下面的命令,将npf7上面的hadoop环境拷贝到npf8上面。
分别配置npf1,npf2到npf8的免密码登录
在npf8上面启动datanode启动之前,我们来看下现在的datanode的活动数目:
在npf8上面启动datanode:
现在我们再来看下datanode的活动数目:
已经有4个了,说明我们的npf8的datanode已经被集群感知了。

相关文章推荐
- hadoop1.1.2集群动态添加datanode节点
- Hadoop动态加入/删除节点(datanode和tacktracker)
- Hadoop之——Hadoop 2.6.3动态增加/删除DataNode节点
- hadoop 动态添加节点datanode及tasktracker
- Hadoop 2.6.3动态增加/删除DataNode节点
- hadoop中datanode节点不同的dfs.data.dir之间数据均衡问题
- hadoop datanode节点硬盘故障下线及上线方法
- Hadoop 生产环境集群平滑下线节点(datanode/tasktracker or nodemanager)
- Datanode部分节点下线
- 关于hadoop中datanode节点不同的dfs.data.dir之间数据均衡问题
- Hadoop 2.6.3动态增加/删除DataNode节点
- Hadoop动态添加/删除节点(datanode和tacktracker)
- NameNode工作机制和DataNode副本工作机制
- datanode节点下线/删除/退役 Decommission Datanode
- 关于hadoop中datanode节点不同的dfs.data.dir之间数据均衡问题
- Hadoop集群动态添加datanode节点步骤
- hadoop集群中动态添加新的DataNode节点
- hdfs haadmin使用,DataNode动态上下线,NameNode状态切换管理,数据块的balance,HA下hdfs-api变化(来自学习资料)
- [Nutch]Hadoop动态增加DataNode节点和TaskTracker节点
- Hadoop 2.6.3动态增加/删除DataNode节点