GZIP压缩原理分析(09)——第四章 基于gzip的HTTP压缩详解(四03) 处理细节(关于流压缩的问题)以及本章总结
2016-07-30 10:18
981 查看
我们构建负载均衡设备的模型来描述流压缩的问题。模型是这样的:负载均衡设备在服务器前端,客户端访问服务器实际上是访问这个负载均衡设备,由该设备将来自客户端的请求发送给服务器并将服务器回复的应答发送给客户端。HTTP压缩功能就做在这个负载均衡设备上,服务器发送给负载均衡设备的HTTP应答是未经过压缩的明文。由负载均衡设备将明文应答压缩后再将压缩结果发送给客户端。
负载均衡设备在压缩明文应答数据时有这样两种处理方法:
1、收齐全部明文应答数据,并且这些数据是保存在负载均衡设备内存中的。当确认全部收齐后,将这些数据统一压缩,并将压缩结果发送回客户端;
2、收到部分应答数据就开始压缩,并将这部分压缩结果发送给客户端,而不是非要等到收齐全部数据再压缩(简言之,就是收点压点再收点再压点。再往细讲还会涉及异步或者同步压缩,但这是涉及到负载均衡设备压缩功能的具体实现细节方面的东西,已经不在我们这里讨论的范畴了)。
第一种方法较为古老并且算是一种“临时性”的方法(我最初就是用这种方法),好处是原理简单、压缩率较高、编码容易、维护轻松,坏处是内存消耗大、扩展性差、功能较为局限(因为要收齐全部应答报文,那么为缓存这些应答报文,使用多大的内存合适呢?如果某种情况下应答报文始终大于缓存区的尺寸,那是不是就不能提供压缩功能了?!)。第二种方法是目前的主流,负载均衡设备业界称之为“流压缩”。这种方法的好处相当明显,不用将报文收齐就可以开始压缩并将结果发送给客户端,这么做首先提高了应答报文的交付速度。其次不用缓冲全部应答报文,这样一来对设备内存的依赖就小了,甭管需要压缩的应答数据有多大,因为再大也是“分组转发”,数据是一个包一个包过来的,惹急了每一个MSS大小的数据就压一次并发送(当然,要先让TCP保证顺序才行)!理论上讲,第二种方法是不限制待压缩数据尺寸的,无论多大都能压!有人会说第二种方法压缩率不够,其实不然,压缩内部的实现也是分成一块一块的(后续讲源码的章节我会仔细分析),只要设定好与当前设备内存对应的一个应答数据收取阈值即可保证压缩率,收取阈值大小的数据就可以开始压缩。上文提到的那个MSS,其实就是把TCP中的那个MSS作为这里的“阈值”了。
目前不少负载均衡设备的HTTP压缩功能都已经使用专门的硬件去实现压缩功能了,我下面要提到的是使用软件接口时要注意的一些实际问题,使用硬件压缩可能并不会涉及这类问题。注意,以下这些问题都是针对流压缩而言的。
对于流压缩而言,因为在没有得到最终压缩结果的时候就已经把当前的压缩结果发送出去了,所以在发送第一个压缩结果的时候,是不知道总压缩结果长度的,也就是说,不能用Content-Length字段去记录总的经过压缩后的数据长度。但也不是绝对的,这要看那个阈值怎么设了,要是整个应答报文都在阈值内,一次压缩就可以搞定全部应答数据,此时当然可以使用Content-Length字段。另外,如果连接不是Keep-Alive的,那么报文头中可以不携带表示数据大小的字段,也不用chunk传输,使用Connection:
close字段即可,直接在压完全部数据之后断开连接。
我主要想说的还是Transfer-Encoding: chunked字段。使用这个字段比较方便,每压完一部分,把这部分放到一个chunk中即可。对于应答数据特别大的情况,使用这种传输方式会非常方便。但必须注意的是,每个chunk都不可以是单独压缩的!!!所谓单独压缩,就是指完成一次gzip压缩!!!结合之前的章节,这里的“一次”可以简单粗暴的理解为带有gzip头和尾的一次压缩过程。也就是说,如果每个chunk里的数据都带有自己的gzip头和尾,即,该chunk对应的原始数据单独使用了一次gzip压缩,那么,虽然整个应答被分成了多个chunk,但是,浏览器,更广义的讲是客户端,只会解压收到的第一个chunk。虽然还有后续chunk,而且后续chunk都携带着自己的压缩数据,但是浏览器不会解压了!!!说到这里,肯定有不少人会说百度等大型网站用了gzip压缩而且还是用Transfer-Encoding传输的,对此,我只想说,麻烦自己抓个包一个字节一个字节的核对一下好吧!!!没错,这些大型网站确实是这样做的,但是,用wireshark把收到的所有的chunk拼起来会发现,它们只有一个gzip头和尾!!!贴图不方便,直接看报文才直观,用wireshark抓即可。
上面说的是实际现象,对于不能每个chunk就压一次的问题,还有理论依据:
见维基百科,http://en.wikipedia.org/wiki/Chunked_transfer_encoding,如下图所示,
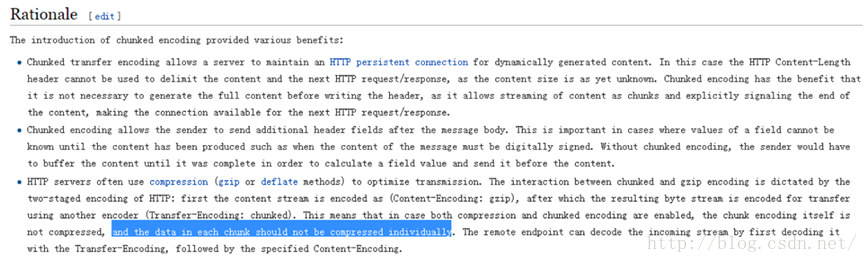
[align=left]可惜我没从RFC2616中找到相应的依据,不知道是我找的不仔细还是根本没有,只找到了下面这句话,如下图所示,[/align]

[align=left]但是没有提到压缩,貌似和压缩没有关系。无论理论依据如何,反正现网目前就是这样的,不排除今后每个chunk可以单独压缩的可能(个人觉得可能性不大)。[/align]
本章总结
本章主要分析gzip在HTTP压缩中的实际应用,并针对现网中的实现细节进行基本分析。这部分内容对压缩本身来讲并不是完全必要的,如果仅仅为了了解压缩,本章可以略过。
负载均衡设备在压缩明文应答数据时有这样两种处理方法:
1、收齐全部明文应答数据,并且这些数据是保存在负载均衡设备内存中的。当确认全部收齐后,将这些数据统一压缩,并将压缩结果发送回客户端;
2、收到部分应答数据就开始压缩,并将这部分压缩结果发送给客户端,而不是非要等到收齐全部数据再压缩(简言之,就是收点压点再收点再压点。再往细讲还会涉及异步或者同步压缩,但这是涉及到负载均衡设备压缩功能的具体实现细节方面的东西,已经不在我们这里讨论的范畴了)。
第一种方法较为古老并且算是一种“临时性”的方法(我最初就是用这种方法),好处是原理简单、压缩率较高、编码容易、维护轻松,坏处是内存消耗大、扩展性差、功能较为局限(因为要收齐全部应答报文,那么为缓存这些应答报文,使用多大的内存合适呢?如果某种情况下应答报文始终大于缓存区的尺寸,那是不是就不能提供压缩功能了?!)。第二种方法是目前的主流,负载均衡设备业界称之为“流压缩”。这种方法的好处相当明显,不用将报文收齐就可以开始压缩并将结果发送给客户端,这么做首先提高了应答报文的交付速度。其次不用缓冲全部应答报文,这样一来对设备内存的依赖就小了,甭管需要压缩的应答数据有多大,因为再大也是“分组转发”,数据是一个包一个包过来的,惹急了每一个MSS大小的数据就压一次并发送(当然,要先让TCP保证顺序才行)!理论上讲,第二种方法是不限制待压缩数据尺寸的,无论多大都能压!有人会说第二种方法压缩率不够,其实不然,压缩内部的实现也是分成一块一块的(后续讲源码的章节我会仔细分析),只要设定好与当前设备内存对应的一个应答数据收取阈值即可保证压缩率,收取阈值大小的数据就可以开始压缩。上文提到的那个MSS,其实就是把TCP中的那个MSS作为这里的“阈值”了。
目前不少负载均衡设备的HTTP压缩功能都已经使用专门的硬件去实现压缩功能了,我下面要提到的是使用软件接口时要注意的一些实际问题,使用硬件压缩可能并不会涉及这类问题。注意,以下这些问题都是针对流压缩而言的。
对于流压缩而言,因为在没有得到最终压缩结果的时候就已经把当前的压缩结果发送出去了,所以在发送第一个压缩结果的时候,是不知道总压缩结果长度的,也就是说,不能用Content-Length字段去记录总的经过压缩后的数据长度。但也不是绝对的,这要看那个阈值怎么设了,要是整个应答报文都在阈值内,一次压缩就可以搞定全部应答数据,此时当然可以使用Content-Length字段。另外,如果连接不是Keep-Alive的,那么报文头中可以不携带表示数据大小的字段,也不用chunk传输,使用Connection:
close字段即可,直接在压完全部数据之后断开连接。
我主要想说的还是Transfer-Encoding: chunked字段。使用这个字段比较方便,每压完一部分,把这部分放到一个chunk中即可。对于应答数据特别大的情况,使用这种传输方式会非常方便。但必须注意的是,每个chunk都不可以是单独压缩的!!!所谓单独压缩,就是指完成一次gzip压缩!!!结合之前的章节,这里的“一次”可以简单粗暴的理解为带有gzip头和尾的一次压缩过程。也就是说,如果每个chunk里的数据都带有自己的gzip头和尾,即,该chunk对应的原始数据单独使用了一次gzip压缩,那么,虽然整个应答被分成了多个chunk,但是,浏览器,更广义的讲是客户端,只会解压收到的第一个chunk。虽然还有后续chunk,而且后续chunk都携带着自己的压缩数据,但是浏览器不会解压了!!!说到这里,肯定有不少人会说百度等大型网站用了gzip压缩而且还是用Transfer-Encoding传输的,对此,我只想说,麻烦自己抓个包一个字节一个字节的核对一下好吧!!!没错,这些大型网站确实是这样做的,但是,用wireshark把收到的所有的chunk拼起来会发现,它们只有一个gzip头和尾!!!贴图不方便,直接看报文才直观,用wireshark抓即可。
上面说的是实际现象,对于不能每个chunk就压一次的问题,还有理论依据:
见维基百科,http://en.wikipedia.org/wiki/Chunked_transfer_encoding,如下图所示,
[align=left]可惜我没从RFC2616中找到相应的依据,不知道是我找的不仔细还是根本没有,只找到了下面这句话,如下图所示,[/align]
[align=left]但是没有提到压缩,貌似和压缩没有关系。无论理论依据如何,反正现网目前就是这样的,不排除今后每个chunk可以单独压缩的可能(个人觉得可能性不大)。[/align]
本章总结
本章主要分析gzip在HTTP压缩中的实际应用,并针对现网中的实现细节进行基本分析。这部分内容对压缩本身来讲并不是完全必要的,如果仅仅为了了解压缩,本章可以略过。

相关文章推荐
- GZIP压缩原理分析(08)——第四章 基于gzip的HTTP压缩详解(四02) 原理
- GZIP压缩原理分析(07)——第四章 基于gzip的HTTP压缩详解(四01) 章前语
- 网络流入门
- (一个常用的案例)Fragment xlistview pull 网络请求 刷新分页加载 ImageLoader
- 在inet_peer/tcp_metrics_hash中记录通往一个IP地址的链路状况历史的metrics信息
- IOS网络请求的一些需要记录的info设置
- 精选30道Java笔试题(原网站:http://www.cnblogs.com/lanxuezaipiao/p/3371224.html)
- Python网络编程之socket编程(一)--使用TCP和UDP客户端和服务器通信
- [置顶] pull解析请求网络的数据(带分页加载,刷新) xlistview HttpUtils
- 神经网络与深度学习读书笔记第二天
- http://ambitiongold.blog.163.com/blog/static/1840165522012921103511610/
- 2016太原网络营销师解说怎样让产品盈利,你知道吗?
- 题目199 无线网络覆盖
- python socket 实现的简单http服务器
- CS231n 学习笔记(3)——神经网络 part3 :最优化
- 使用 枫彩网络_云流量____向导
- Android网络编程
- Android下使用TcpDump抓包Wireshark分析数据
- 1.1.4 计算机网络的分类
- OkHttp源码解析(五)——cache缓存