Torch7学习(四)——学习神经网络包的用法(2)
2016-07-25 20:11
531 查看
torch7学习(一)——Tensor
Torch7学习(二) —— Torch与Matlab的语法对比
Torch7学习(三)——学习神经网络包的用法(1)
Torch7学习(四)——学习神经网络包的用法(2)
Torch7学习(五)——学习神经网路包的用法(3)
Torch7学习(六)——学习神经网络包的用法(4)——利用optim进行训练
Torch7学习(七)——从neural-style代码中看自定义重载函数的训练方式
1. [output]forward(input)
2. [gradInput] backward (input.gradOutput)
以及在后面自动挡训练方式中重载的两个函数
3. [output] updateOutput (input)
4. [gradInput] updateGradInput (input, gradOutput)
注意点:
1. forward函数的input必须和backward的函数的input一致!否则梯度更新会有问题。
2. Module的forward会调用updateOutput(input), 而backward会调用[gradInput] updateGradInput (input, gradOutput)和accGradParameters(input, gradOutput)
3. 高级训练方式只要重载updateOutput和updateGradInput这两个函数,内部参数会自动改变。
4. 对于第3点,需要更加深入的探讨
container的子类主要有三个:Sequential, Parallel, Concat 。他重新实现了Module类的方法。此外还增加了很多方法。
主要函数:
1. add(module)
2. get(index)
3. size() return the number of contained modules.
4. remove(index)
5. insert (module, [index] ) 注意这里的index是插入后,其排到的index
用法就是,一般是用一个Sequential,然后不断add(module),而module有simple layers和卷积层。在后面进行说明。
这个没啥好说的。
里面有挺多激活函数的. SoftMax, SoftMin, SoftPlus, LogSigmoid, LogSoftMax, Sigmoid, Tanh, ReLU, PReLU, ELU, LeakyReLU等等。
这里就拿Tanh举例吧。
具有参数的modules有:
Linear
Add : 对输入增加一个偏置项
Mul
CMul
等等
进行基本Tensor运算的
View
Transpose
等等
进行数学运算的
Max, Min, Exp, Mean, Log, Abs, MM:matrix-matrix multiplication.
Normalize: normalize the input to have unit L-p norm
其他
Identity
Dropout
下面调重要常见的几个
Linear就是全连接呗。
运行后发现,只要初始化后网络,里面就有初始权值和偏置。但是gradBias和gradGradient不是很大就是很小,显然这是垃圾数据。现在有个问题,网络权值的初始化对整个网络的训练非常重要,torch是怎样自定义初始化权值的呢?我现在还没发现!先做个标记!
这个就是Dropout层。简单的说每一个神经元的输入将会以p的概率丢弃。这个方法是一个避免过拟合的正规化方法。可参见Improving neural networks by preventing co-adaptation of feature detectors
可以看出,上面一些值被丢弃。
如果是用view(-1)则可特别地用作minibatch的输入。
作为minibatch的输入!
L-p范式进行归一化,eps默认是1e-10,防止输入全为0时除0的情况。
transA/transB 为true时,则对应的矩阵进行转置。
如果是3维矩阵,则第一维被理解成batches的num,转置只会对后面的两维进行。
简单层一个常见的Module是Add,放在下篇博客讲。因为会用简单层的Add模块讲手动挡训练演示。
Torch7学习(二) —— Torch与Matlab的语法对比
Torch7学习(三)——学习神经网络包的用法(1)
Torch7学习(四)——学习神经网络包的用法(2)
Torch7学习(五)——学习神经网路包的用法(3)
Torch7学习(六)——学习神经网络包的用法(4)——利用optim进行训练
Torch7学习(七)——从neural-style代码中看自定义重载函数的训练方式
总说
上篇博客已经初步介绍了Module类。这里将更加仔细的介绍。并且还将介绍Container, Transfer Functions Layers和 Simple Layers模块。Module
主要有4个函数。1. [output]forward(input)
2. [gradInput] backward (input.gradOutput)
以及在后面自动挡训练方式中重载的两个函数
3. [output] updateOutput (input)
4. [gradInput] updateGradInput (input, gradOutput)
注意点:
1. forward函数的input必须和backward的函数的input一致!否则梯度更新会有问题。
2. Module的forward会调用updateOutput(input), 而backward会调用[gradInput] updateGradInput (input, gradOutput)和accGradParameters(input, gradOutput)
3. 高级训练方式只要重载updateOutput和updateGradInput这两个函数,内部参数会自动改变。
4. 对于第3点,需要更加深入的探讨
Container
复杂的神经网络可以用container类进行构建。container的子类主要有三个:Sequential, Parallel, Concat 。他重新实现了Module类的方法。此外还增加了很多方法。
主要函数:
1. add(module)
2. get(index)
3. size() return the number of contained modules.
4. remove(index)
5. insert (module, [index] ) 注意这里的index是插入后,其排到的index
用法就是,一般是用一个Sequential,然后不断add(module),而module有simple layers和卷积层。在后面进行说明。
Transfer Functions Layers
就是激活函数,在第上一篇博客已经说明了,torch中讲神经网络看成是module(或是container)的组合。你可以加入层模块,或是激活函数的层模块,最后还可以加上criterion层模块。如此一来,整个网络就构建好了。这个没啥好说的。
里面有挺多激活函数的. SoftMax, SoftMin, SoftPlus, LogSigmoid, LogSoftMax, Sigmoid, Tanh, ReLU, PReLU, ELU, LeakyReLU等等。
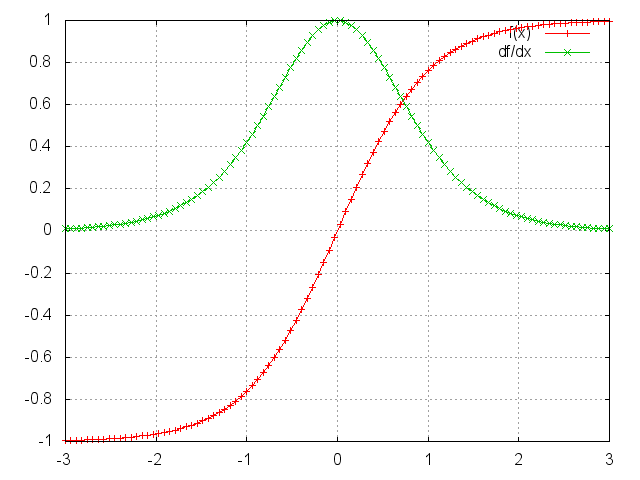
这里就拿Tanh举例吧。
ii=torch.linspace(-3,3)
m=nn.Tanh()
oo=m:forward(ii)
go=torch.ones(100)
gi=m:backward(ii,go)
gnuplot.plot({'f(x)',ii,oo,'+-'},{'df/dx',ii,gi,'+-'})
gnuplot.grid(true)Simple Layers
简单层有很多,一些是提供仿射变换的,一些是进行Tensor method的。具有参数的modules有:
Linear
Add : 对输入增加一个偏置项
Mul
CMul
等等
进行基本Tensor运算的
View
Transpose
等等
进行数学运算的
Max, Min, Exp, Mean, Log, Abs, MM:matrix-matrix multiplication.
Normalize: normalize the input to have unit L-p norm
其他
Identity
Dropout
下面调重要常见的几个
Linear
module = nn.Linear(inputDim, outputDim, [bias = true])
Linear就是全连接呗。
module = nn.Linear(10,5) mlp = nn.Sequential() mlp:add(module) print(module.weight) print(module.bias) print(module.gradWeight) print(module.gradBias) x = torch.Tensor(10) -- 10 inputs y = module:forward(x)
运行后发现,只要初始化后网络,里面就有初始权值和偏置。但是gradBias和gradGradient不是很大就是很小,显然这是垃圾数据。现在有个问题,网络权值的初始化对整个网络的训练非常重要,torch是怎样自定义初始化权值的呢?我现在还没发现!先做个标记!
Dropout
module = nn.Dropout(p)
这个就是Dropout层。简单的说每一个神经元的输入将会以p的概率丢弃。这个方法是一个避免过拟合的正规化方法。可参见Improving neural networks by preventing co-adaptation of feature detectors
module = nn.Dropout()
> x = torch.Tensor{{1, 2, 3, 4}, {5, 6, 7, 8}}
> module:forward(x)
2 0 0 8
10 0 14 0
[torch.DoubleTensor of dimension 2x4]
> module:forward(x)
0 0 6 0
10 0 0 0
[torch.DoubleTensor of dimension 2x4]可以看出,上面一些值被丢弃。
View
这个主要是改变网络输出的tensor的sizes,就是reshape一下。module = nn.View(sizes)
如果是用view(-1)则可特别地用作minibatch的输入。
x = torch.Tensor(4, 4) for i = 1, 4 do for j = 1, 4 do x[i][j] = (i-1)*4+j end end print(nn.View(2, 8):forward(x)) --[[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ]]
作为minibatch的输入!
> input = torch.Tensor(2, 3) > minibatch = torch.Tensor(5, 2, 3) > m = nn.View(-1):setNumInputDims(2) > print(#m:forward(minibatch)) 5 6 [torch.LongStorage of size 2] --每一行就是一个example的结果。
Normalize
module = nn.Normalize(p, [eps])
L-p范式进行归一化,eps默认是1e-10,防止输入全为0时除0的情况。
MM
module = nn.MM(transA,transB)
transA/transB 为true时,则对应的矩阵进行转置。
如果是3维矩阵,则第一维被理解成batches的num,转置只会对后面的两维进行。
module = nn.MM(true, false)
A = torch.randn(b,n,m)
B = torch.randn(b,n,p)
c = module:forward({A, B})
--[[
c是 b * m * p的
]]简单层一个常见的Module是Add,放在下篇博客讲。因为会用简单层的Add模块讲手动挡训练演示。

相关文章推荐
- 网络编程的几个函数
- http缓存浅谈
- 基本控件使用(一)(遮罩、HTTP请求、ControlSlider、ControlSwitch、ProgressTo)
- 远程更新公告---目标软件-----枫彩网络工具箱
- 0143 [HLS]做自己的m3u8点播系统使用HTTP Live Streaming(HLS技术)
- 网络Http 相关 工具 类
- vagrant 网络
- HttpClient4.5和RestTemplate使用
- HTTP 介绍
- 跳转至系统网络设置界面
- CentOS tcpflow抓包
- java网络socket编程(六)之HTTP请求/响应报文
- 浅谈WebService SOAP、Restful、HTTP(post/get)请求
- 北京全时天地在线网络信息股份有限公司(投放广告)
- iOS网络请求工具oc版,swift版基于AFNetworking的简单封装
- Retrofit初探
- [置顶] Android之三种网络请求解析数据(最佳案例)
- javaWeb-----Http协议的解读
- 斯坦福大学深度学习笔记:神经网络
- HTTPS系列之SSL/TLS协议