常见算法与数据结构整理
2016-07-21 16:45
260 查看
校招季自己整理的相关知识点,会一直更新。
一、动态规划
主要思路:先确定优化方程,再确定递推关系1、最长公共字串(LCS)
X,Y的公共字串为Z,Z中的字符串在X,Y中不一定要连续出现,但是是X,Y中递增出现。
子问题:C[i,j]表示Xi和Yj的最长公共子串,则若Xi=Yj,C[i,j]=c[i-1,j-1]+1,否则C[I,j]=max(C[i-1.j],C[i,j-1]。C[0,j]=C[i,0]=0
【变形问题】给定一个字符串s,你可以从中删除一些字符,使得剩下的串是一个回文串。如何删除才能使得回文串最长呢?输出需要删除的字符个数。
比较简单的想法就是求原字符串和其反串的最大公共子串的长度,然后用原字符串的长度减去这个最大公共子串的长度就得到了最小编辑长度。
二、递归
1、欧几里得法求最大公约数a和b(a>b)的最大公约数等于b和a Mode b的最大公约数,知道余数为0,此时除数为最大公约数。
public int gcd(int a, int b){return b == 0? a : gcd(b, a%b);
}
三、并查集
并查集是一种典型的树型结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。主要操作:
初始化:把每个节点初始化为其自身
查找:查找元素所在的集合,即根节点
public int find(int x, int[] pre){int r = x;
while(pre[r] != r){r = pre[r];
//路径压缩,把x到根节点之间的点的上层节点直接改为根节点
int i=x, j;
while(i != r){j = pre[i];
pre[i] = r;
i = j;
}
return r;
}
合并:将两个元素所在的集合合并为一个集合。合并之前,应判断两个元素是否属于同一集合,这可用上面的“查找”操作实现。
public void join(int x, int y){//连通分支 合并
int fx = find(x);
int fy = find(y);
if(fx != fy)
pre[fx] = fy;
}
四、位操作
1、给一组数,其中只有一个数重复了奇数次,其余都重复了偶数次,如何找出奇数次的那个数。异或操作,a ^ a = 0;
int ans = 0;
for(int i=0; i<n; i++){ans = ans ^ num[i];
}
return ans;
五、排序
八大排序算法
交换排序有(基于比较):冒泡排序:基本思想是在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的数网上冒。即每当相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。平均复杂度O(n^2)。当原始数据升序时,复杂度O(n)。
public void bubble(int[] num){for(int i=0; i<num.length; i++){for(int j=0; j<num.length-i-1; j++){//这里-i主要是每一次遍历,都把最大的i个数沉到最底下去了,没必要再替换了
if( num[j] > num[j+1){int tmp = num[j];
num[j] = num[j+1];
num[j+1] = tmp;
}
}
}
快速排序: 基本思想是选择一个基准元素,通常选择第一个或者最后一个元素,通过一趟扫描,将待排序的分成两部分,一部分比基准元素小,一部分大于等于基准元素,此时基准元素在其排好序后的正确位置,然后用同样的方法递归排序小于基准的序列和大于基准的序列。平均复杂度O(nlogn),最坏(n^2)。
public int partition(int[] data, int low, int high){int key = data[low];
while( low < high){while(low < high && data[high] > key)
high -- ;
data[low] = data[high];
while( low < high && data[low] < key)
low ++;
data[high] = data[low];
}
data[low] = key;
return low;
}
public void quicksort(int[] data, int low, int high){int q ;
if( low < high){q = partition(data, low, high);
quicksort(data,low,q-1);
quicksort(data,q+1,high);
}
}
基于选择排序的算法有:
堆排序:堆排序是一种属性选择排序,是对直接选择排序的有效改进。最大堆的定义(最小堆类似):若以一位数组存储一个堆,则堆对应一棵完全二叉树,且所有根节点的值大于其左右子节点的值,堆顶元素是最大的。初始时把n个元素调成堆,堆顶元素是第n大的,与最后的一个元素互换,即第n大的排在最后。然后对前面的n-1个元素重新调整,使之成堆,继续将堆顶元素后调。复杂度最坏为O(nlogn)。
数组下标从0开始,第i个节点,左子节点坐标为2*i-1,右子节点坐标为2*i,第i个节点的父节点坐标为(i-1)/2;
因此,实现堆排序需解决两个问题:
(1). 如何将n 个待排序的数建成堆;
(2). 输出堆顶元素后,怎样调整剩余n-1 个元素,使其成为一个新堆。
首先讨论第二个问题:输出堆顶元素后,对剩余n-1元素重新建成堆的调整过程。
调整小顶堆的方法:
1)设有m 个元素的堆,输出堆顶元素后,剩下m-1 个元素。将堆底元素送入堆顶((最后一个元素与堆顶进行交换),堆被破坏,其原因仅是根结点不满足堆的性质。
2)将根结点与左、右子树中较小元素的进行交换。
3)若与左子树交换:如果左子树堆被破坏,即左子树的根结点不满足堆的性质,则重复方法 (2).
4)若与右子树交换,如果右子树堆被破坏,即右子树的根结点不满足堆的性质。则重复方法 (2).
5)继续对不满足堆性质的子树进行上述交换操作,直到叶子结点,堆被建成。
称这个自根结点到叶子结点的调整过程为筛选。
再讨论对n 个元素初始建堆的过程。
建堆方法:对初始序列建堆的过程,就是一个反复进行筛选的过程。
1)n 个结点的完全二叉树,则最后一个结点是第
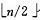
个结点的子树。
2)筛选从第
个结点为根的子树开始,该子树成为堆。
3)之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
/**
* 已知H[s…m]除了H[s] 外均满足堆的定义
* 调整H[s],使其成为大顶堆.即将对第s个结点为根的子树筛选,
*
*@param H是待调整的堆数组
*@param s是待调整的数组元素的位置
*@param length是数组的长度
*
*/
static void HeapAdjust(int H[],int s, int length)
{int tmp = H[s];
int child = 2*s+1; //左孩子结点的位置。(i+1 为当前调整结点的右孩子结点的位置)
while (child < length) { if(child+1 <length && H[child]>H[child+1]) { // 如果右孩子小于左孩子(找到比当前待调整结点小的孩子结点) ++child ;
}
if(H[s]>H[child]) { // 如果较大的子结点小于父结点 H[s] = H[child]; // 那么把较小的子结点往上移动,替换它的父结点
s = child; // 重新设置s ,即待调整的下一个结点的位置
child = 2*s+1;
}else {// 如果当前待调整结点小于它的左右孩子,则不需要调整,直接退出 break;
}
H[s] = tmp; // 当前待调整的结点放到比其小的孩子结点位置上
}
}
/**
*初始堆进行调整
*将H[0..length-1]建成堆
*调整完之后第一个元素是序列的最小的元素
*/
static void BuildingHeap(int H[], int length)
{ //最后一个有孩子的节点的位置 i= (length -1) / 2
for (int i = (length -1) / 2 ; i >= 0; --i)
HeapAdjust(H,i,length);
}
/**
*堆排序算法
*/
static void HeapSort(int H[],int length)
{//初始堆
BuildingHeap(H, length);
//从最后一个元素开始对序列进行调整
for (int i = length - 1; i > 0; --i)
{//交换堆顶元素H[0]和堆中最后一个元素
int temp = H[i]; H[i] = H[0]; H[0] = temp;
//每次交换堆顶元素和堆中最后一个元素之后,都要对堆进行调整
HeapAdjust(H,0,i);
}
}
public static void main(String[] args) {int[] H = {3,1,5,7,2,4,9,6,10,8};HeapSort(H,10);
}
1、一个N个整数的无序数组,给你一个数sum,求出数组中是否存在两个数,使他们的和为sum。
先排序,然后头尾双指针遍历,复杂度O(nlogn);
六、二叉树
完全二叉树:设树的高度为h,除第h层外,其他各层(1~h-1)的节点数都达到最大个数,第h层有叶子节点,并且叶子节点都是从左到右依次排布。满二叉树:除了叶节点外每一个节点都有左右子叶且叶子节点都处在最底层的二叉树。
平衡二叉树:又称为AVL树,它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
哈夫曼树:哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的
路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的带权路径长度记为WPL= (W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。可以证明哈夫曼树的WPL是最小的。
哈夫曼编码步骤:
一、对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F= {T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。(为方便在计算机上实现算 法,一般还要求以Ti的权值Wi的升序排列。)
二、在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
三、从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
四、重复二和三两步,直到集合F中只有一棵二叉树为止。
补充:前缀码:对每一个字符规定一个0,1串作为其代码,并要求任一字符的代码都不是其他字符代码的前缀。这种编码称为前缀码。编码的前缀性质可以使译码方法非常简单。
1、求二叉树的最大距离
二叉树看成一个图,距离定义为两节点之间边的个数。写一个程序求一棵二叉树中相距最远的两个节点之间的距离。
最大距离的两个点有可能出现在三种情况下:
a. 左子树 b.右子树 c.过根节点,左节点深度加右节点深度
递推公式:Dis(x) = max( dis(x->left), dis(x->right), height(x->left)+height(x->right)),求节点深度可以用广搜,也可用深搜。
求二叉树深度代码:从根节点到叶节点依次经过的节点形成树的一条路径,最长路径的长度为树的深度
int depth = 0;
public void DFS(TreeNode root , int d){if(root.left = null && root.rigth == null){if(d > depth)depth = d;
else{if(root.left != null)
DFS(root.left, d+1);
if(root.right != null)
DFS(root.right, d+1);
}
}
2、求二叉树的宽度和深度
空的二叉树的宽度为0,非空二叉树的宽度为各层节点个数的最大值。深度为最深的节点所在的层数。
3、求字符串的最短编码
用哈夫曼编码。字符的频率代表权重,每次选权重最小的两个开始合并。
七、KMP算法
模式匹配算法,对任何模式和目标序列,都可以在线性时间内完成匹配查找
八、回溯法
回溯法按深度优先策略搜索问题的解空间树。首先从根节点出发搜索解空间树,当算法搜索至解空间树的某一节点时,先利用剪枝函数判断该节点是否可行(即能得到问题的解)。如果不可行,则跳过该节点为根的子树的搜索,逐层向其祖先节点回溯;否则,进入该子树,继续按深度优先策略搜索。回溯法的基本行为是搜索,搜索过程中使用剪枝函数来避免无效的搜索。剪枝函数包括两类:1.使用约束函数,减去不满足约束条件的路径;2.使用界定函数,剪去不能得到最优解的路径。回溯法的两种实现方式:递归和递推
递归范式:思路简单,设计容易,但效率低,其设计范式如下
public void backtrace(int t){if(t > n)
output(x); //叶子节点,输出结果,x是可行解
else{for i = 1 to k {//当前结点的所有节点x[t] = value(i); //每个子节点的值赋值给x
if( constraint(t) && bound(t))
backtrace( t+1);
}
}
}
递推范式:算法设计相对复杂,但效率高
public void iterativeBacktrace(){int t = 1;
while( t> 0){if( ExistSubNode(t)){//当前节点存在子节点for i = 1 to k {x[t] = value(i);
if( constraint(t) && bound(t)){if( solution(t))output(x);
else t++;
}
}
}else
t--;
}
}
可以用回溯法解决的问题
(1)子集树:从所给的n个元素的集合S中找出满足某种性质的子集时,相应的解空间成为子集树。
如0-1背包问题,挑几个物品放入背包,使得背包在不超重的情况下,背包内物品价值最大。
(2)排列问题:(组合问题可以基于排列问题,限制t的深度即可,比如四个里面选两个的情况)
旅行售货员问题:一个售货员把几个城市旅行一遍,要求走到路程最小。(所有城市的排列情况取最小值,可以剪枝)
8皇后问题:x[i]为第i行的所在列位置,实质为1-8的全排列,求其中的可行解
迷宫问题:记录每一步走的坐标。从入口开始,选择下一个可以走的位置,如果位置可走,则继续往前,如果位置不可走,则返回上衣位置
九、贪心算法
贪心算法的基本要素:1、贪心选择性质。所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优解,即贪心选择来达到。这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别。
2、贪心算法通常以自定向下的方式进行,以迭代的方式作出相继的贪心选择,每作一次贪心选择就将所求问题简化为规模更小的子问题。而动态规划算法通常以自底向上的方式解决各子问题。
可以用贪心算法解决的问题
(1)背包问题:当物品可以任意拆分时,每次选择单位质量价值最高的。
(2)活动时间安排问题:只有一个会议室,求尽可能多的使参加的活动最大化。找每次结束最早的。
(3)最大整数:有n个整数,连城一排,组成一个最大的多位整数。先把整数转换成字符串,然后在比较a+b和b+a,如果a+b>=b+a,就把a排在b的前面,反之则把a排在b的后面(改排序算法里的比较部分)。

相关文章推荐
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- C#递归算法之分而治之策略
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- C#算法之大牛生小牛的问题高效解决方法
- C#算法函数:获取一个字符串中的最大长度的数字
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- 经典排序算法之冒泡排序(Bubble sort)代码
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法