Kafka基本介绍
2016-07-19 09:43
666 查看
一、背景
1、Why Kafka
以ActiveMQ为例,和Kafka同属于Apache,发展前景都十分被看好。但两种的设计目标却各有侧重。ActiveMQ可以支持多种协议、事务等,但在吞吐量上,他的Forwarding Bridge机制一直被很多人吐槽。但Kafka侧重点在大数据、分布式应用,他可以支持动态扩容(通过zk)。Kafka是为分布式而生的,他主要来应对庞大的活动流数据。因此,强大的吞吐量是更重要的,为此,砍掉了很多复杂特性:如事务、分发策略等。
2、是什么
Kafka是一个高吞吐量的分布式发布订阅消息系统,也可以叫做分布式消息中间件。
二、相关概念
1、AMQP
Advanced Message Queuing Protocol 高级消息协议,是一种应用层协议的开放标准。作为一种协议,他提供的是一种标准、规范或者叫模型。为的是提供一种全行业广泛使用的标准中间件技术,来降低企业应用的开销。
2、Topic & Partition
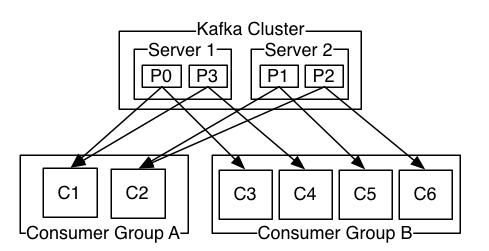
Topic可以看作消息的分类,我们可以将一类业务划分为一个Topic。每个Topic中由一个或多个Partition。Partition是最小单位,类似一个FIFO队列。如图:每个broker类似一个Server。

3、Consumer Group
传统的消息中间件至少提供两种消息模型:点对点、发布订阅模型。但Kafka提出了消费者组的概念,来实现这两种模型。规则是:一个消息可以被多个消费者消费,但只能被一个消费者组里的一个消费者消费。
听起来有点绕,直接上图。比如Server1中的P0消息,他可以被C1、C3消费,因为他们分属不同的Consumer Group。其他的消息也是如此。
在同一个Consumer Group中,Kafka实现了点对点模型。
在不同的Group中,又实现了发布订阅模型。
三、特性
1、push vs pull
在消息系统中,发送消息的方式主要有push和pull两种。push是指直接将消息推送到用户,pull正好相反,需要消费者自己获取。pull方法,消费者比较麻烦,需要自己拿,通常会定时拉取,可能消息推送不及时。push方法对于消费者(用户)来说,就便利很多了,他不需要你实时关注变化。
2、Replication
Kafka的副本设计是一大亮点,目的是为了保持更强的持久性和高可用性。自动的副本管理可以保证即使在某台服务器发生故障后,也不会造成数据丢失和服务不可用。
相关文章推荐
- Kafka 之 中级
- Apache Isis 1.4.0 发布,领域驱动开发框架
- RH436 Day3 课后总结
- Linux快速构建apache web服务器
- Awstats处理多apache日志
- 安装perl模块小窍门
- Apache静态编译与动态编译的区别
- PHP+Apache在Windows 9x下的安装和配置
- Apache服务器配置全攻略
- Apache Web让JSP“动”起来
- Linux Apache+MySQL+PHP
- 建立Apache+PHP+MySQL数据库驱动的动态网站
- apache 环境下 php 的配置注意事项
- 在RedHat下安装apache jserv 1.1.2方法
- windows8.1下Apache+Php+MySQL配置步骤
- windows中PHP5.2.14以及apache2.2.16安装配置方法第1/2页
- 在Windows XP下安装Apache+MySQL+PHP环境
- 解析阿里云ubuntu12.04环境下配置Apache+PHP+PHPmyadmin+MYsql
- apache rewrite防盗链三例
- Apache 配置详解(最好的APACHE配置教程)