一种高效的 vector 四则运算处理方法
2016-07-17 10:41
441 查看
实现 vector 的四则运算
这里假设 vector 的运算定义为对操作数 vector 中相同位置的元素进行运算,最后得到一个新的 vector。具体来说就是,假如vector<int>
d1{1, 2, 3}, d2{4, 5, 6};则, v1 + v2等于
{5,
7, 9}。实现这样的运算看起来并不是很难,一个非常直观的做法如下所示:vector<int> operator+(const vector<int>& v1, const vector<int>& v2) {
// 假设 v1.size() == v2.size()
vector<int> r;
r.reserve(v1.size());
for (auto i = 0; i < v1.size(); ++i) {
r.push_back(v1[i] + v2[i]);
}
return r;
}
// 同理,需要重载其它运算符我们针对 vector 重载了每种运算符,这样一来,vector 的运算就与一般简单类型无异,实现也很直白明了,但显然这个直白的做法有一个严重的问题:效率不高。效率不高的原因在于整个运算过程中,每一步的运算都产生了中间结果,而中间结果是个 vector,因此每次都要分配内存,如果参与运算的 vector 比较大,然后运算又比较长的话,效率会比较低,有没有更好的做法呢?
既然每次运算产生中间结果会导致效率问题,那能不能优化掉中间结果?回过头来看,这种 vector 的加减乘除与普通四则运算并无太大差异,在编译原理中,对这类表达式进行求值通常可以通过先把表达式转为一棵树,然后通过遍历这棵树来得到最后的结果,结果的计算是一次性完成的,并不需要保存中间状态,比如对于表达式:
v1 + v2 * v3,我们通常可以先将其转化为如下样子的树:

因此求值就变成一次简单的中序遍历,那么我们的 vector 运算是否也可以这样做呢?
表达式模板
要把中间结果去掉,关键是要推迟对表达式的求值,但 c++ 不支持 lazy evaluation,因此需要想办法把表达式的这些中间步骤以及状态,用一个轻量的对象保存起来,具体来说,就是需要能够将表达式的中间步骤的操作数以及操作类型封装起来,以便在需要时能动态的执行这些运算得到结果,为此需要定义类似如下这样一个类:http://item.taobao.com/item.htm?id=41222768202enum OpType {
OT_ADD,
OT_SUB,
OT_MUL,
OT_DIV,
};
class VecTmp {
int type_;
const vector<int>& op1_;
const vector<int>& op2_;
public:
VecTmp(int type, const vector<int>& op1, const vector<int>& op2)
: type_(type), op1_(op1), op2_(op2) {}
int operator[](const int i) const {
switch(type_) {
case OT_ADD: return op1_[i] + op2_[i];
case OT_SUB: return op1_[i] - op2_[i];
case OT_MUL: return op1_[i] * op2_[i];
case OT_DIV: return op1_[i] / op2_[i];
default: throw "bad type";
}
}
};有了这个类,我们就可以把一个简单的运算表达式的结果封装到一个对象里面去了,当然,我们得先将加法操作符(以及其它操作符)重载一下:
VecTmp operator+(const vector<int>& op1, const vector<int>& op2) {
return VecTmp(OT_ADD, op1, op2);
}这样一来,对于
v1 + v2,我们就得到了一个非常轻量的 VecTmp 对象,而该对象可以很轻松地转化
v1 + v2的结果(遍历一遍 VecTmp 中的操作数)。但上面的做法还不能处理
v1 + v2 * v3这样的套嵌的复杂表达式:
v2 * v3得到一个 VecTmp,那
v1 + VecTmp怎么搞呢?
同理,我们还是得把
v1 + VecTmp放到一个轻量的对象里,因此最好我们的 VecTmp 中保存的操作数也能是 VecTmp 类型的,有点递归的味道。。。用模板就可以了,于是得到如下代码:http://item.taobao.com/item.htm?id=41222768202
#include <vector>
#include <iostream>
using namespace std;
enum OpType {
OT_ADD,
OT_SUB,
OT_MUL,
OT_DIV,
};
template<class T1, class T2>
class VecSum {
OpType type_;
const T1& op1_;
const T2& op2_;
public:
VecSum(int type, const T1& op1, const T2& op2): type_(type), op1_(op1), op2_(op2) {}
int operator[](const int i) const {
switch(type_) {
case OT_ADD: return op1_[i] + op2_[i];
case OT_SUB: return op1_[i] - op2_[i];
case OT_MUL: return op1_[i] * op2_[i];
case OT_DIV: return op1_[i] / op2_[i];
default: throw "bad type";
}
}
};
template<class T1, class T2>
VecSum<T1, T2> operator+(const T1& t1, const T2& t2) {
return VecSum<T1, T2>(OT_ADD, t1, t2);
}
template<class T1, class T2>
VecSum<T1, T2> operator*(const T1& t1, const T2& t2) {
return VecSum<T1, T2>(OT_MUL, t1, t2);
}
int main() {
std::vector<int> v1{1, 2, 3}, v2{4, 5, 6}, v3{7, 8, 9};
auto r = v1 + v2 * v3;
for (auto i = 0; i < r.size(); ++i) {
std::cout << r[i] << " ";
}
}上面的代码漂亮地解决了前面提到的效率问题,扩展性也很好而且对 vector 来说还是非侵入性的,虽然实现上乍看起来可能不是很直观,除此也还有些小问题可以更完善些:http://item.taobao.com/item.htm?id=41222768202
操作符重载那里很可能会影响别的类型,因此最好限制一下,只针对 vector 和 VecTmp 进行重载,这里可以用 SFINAE 来处理。
VecTmp 的 operator[] 函数中的 switch 可以优化掉,VecTmp 模板只需增加一个参数,然后对各种运算类型进行偏特化就可以了。
VecTmp 对保存的操作数是有要求的,只能是 vector 或者是 VecTmp<>,这里也应该用 SFINAE 强化一下限制,使得用错时出错信息好看些。
现在我们来重头再看看这一小段奇怪的代码,显然关键在于 VecTmp 这个类,我们可以发现,它的接口其实很简单直白,但它的类型却可以是那么地复杂,比如说对于 v1 + v2 * v3 这个表达式,它的结果的类型是这样的:
http://item.taobao.com/item.htm?id=41222768202,如果表达式再复杂些,它的类型也就更复杂了,如果你看仔细点,是不是还发现这东西和哪里很像?像一棵树,一棵类型的树。
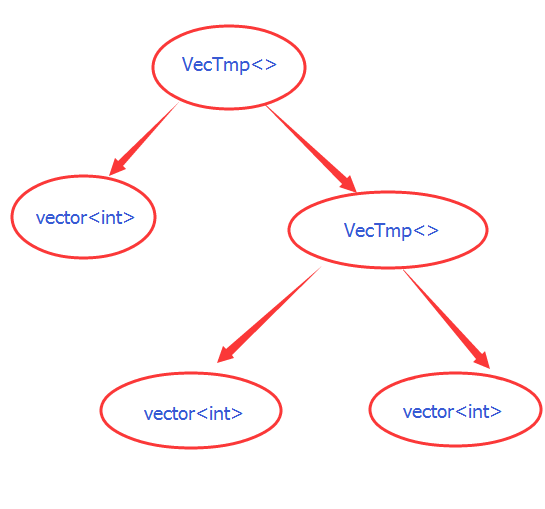
这棵树看起来是不是还很眼熟,每个叶子结点都是 vector,而每个内部结点则是由 VecTmp 实例化的:这是一棵类型的树,在编译时就确定了。这种通过表达式在编译时得到的复杂类型有一个学名叫: Expression template。在 c++ 中每一个表达式必产生一个结果,而结果必然有类型,类型是编译时的东西,结果却是运行时的。像这种运算表达式,它的最终类型是由其中每一步运算所产生的结果所对应的类型组合起来所决定的,类型确定的过程其实和表达式的识别是一致的。
VecTmp 对象在逻辑上其实也是一棵树,它的成员变量 op1_, op2_ 则分别是左右儿子结点,树的内部结点代表一个运算,叶子结点则为操作数,一遍中序遍历下来,得到的就是整个表达式的值。

相关文章推荐
- MySQL中的integer 数据类型
- MySQL存储过程
- 基于 Red Hat 的发行版 Oracle Linux 正式发布Oracle Linux 7.1
- mysql中int、bigint、smallint 和 tinyint的区别与长度
- mysql load data 导出、导入 csv
- source命令执行SQL脚本文件
- MySQL创建用户及权限控制
- MySQL管理数据表
- linux下mysql添加用户
- mysql procedure
- mysql触发器
- Oracle Containers for J2EE远程安全漏洞(CVE-2014-0413)
- Oracle 10g R2不能使用EM的问题
- MySQL 备份和恢复策略
- 表空间操作
- PreparedStatement中in子句的处理
- mac下安装mysql(转载)
- mysql 修改编码 Linux/Mac/Unix/通用(杜绝修改后无法启动的情况!)