从关系型数据库到非关系数据库
2016-07-16 21:54
218 查看
1.关系型数据的价值
获得持久化数据:数据库最大的价值就是获得持久化储存大量的数据,最常见的后背存储器就是磁盘,在数据量较大时,数据库比文件系统更加灵活,它能让应用程序快速获得其中的一小部分数据并发:关系型数据库通过事务来控制对数据的访问,以便处理并发情况下数据的不一致。
集成:现在的应用开发中多是一个团队共同开发,不用应用程序经常需要使用同一份数据。常用的办法就是使用共享数据库集成,多个应用的数据保存到一个数据库中
近乎标准的模型:关系型数据库近乎标准的方式提供了上述的核心优势。尽管各种关系型数据库之间有差异,但是核心机制相同,不同厂商的SQL类似,而且事务操作的方式也类似。
2.阻抗失谐(impedance mismatch)
关系型数据库的一个劣势就是 阻抗失谐(impedance mismatch):关系模型和内存中的数据结构之间存在差异关系型数据库中不可以含有嵌套纪录,一个订单里面可能是多个数据表信息组成例如 客户信息表,价格信息表,信用卡信息表。而内存中的数据结构则没有这个限制,它可以使用数据组织形式较为丰富的数据结构,例如下面这图
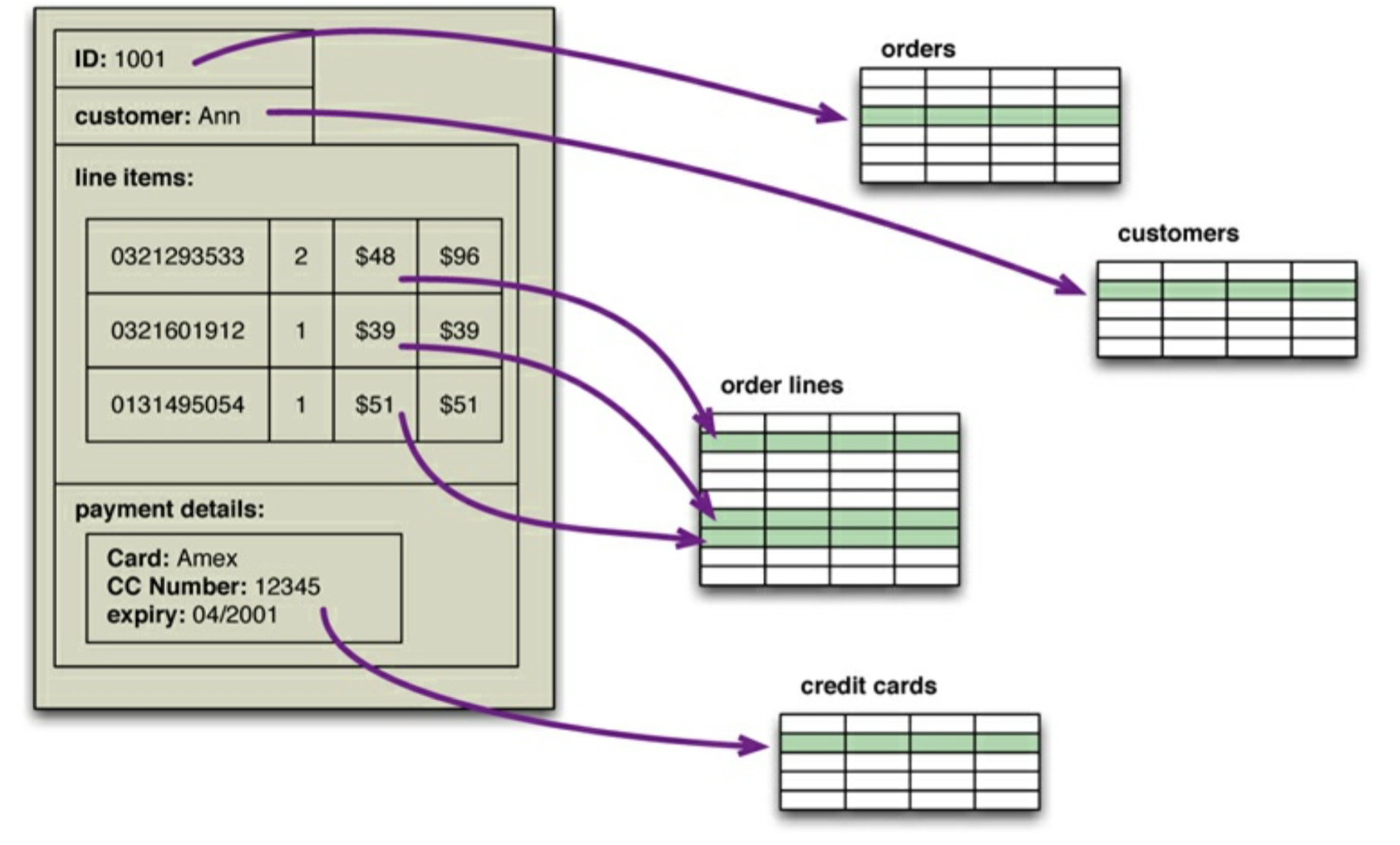
当我们把内存中订单信息的数据保存在关系型数据库中 我们需要将其转化成关系的形式。工程上位了应对关系型数据库的阻抗失谐问题,已经有了很多“对象-关系映射框架”(object-relational mapping framework),可以轻松解决阻抗失谐的问题,例如Hibernate和iBATIS,他们实现了著名的映射模式。
但是,映射问题依然存在。“对象-关系”映射框架简化了很多繁重的工作,如果过分依赖而不是用数据库的话,那框架本身就有问题:因为性能会下降
当内存中较为丰富的数据结构,保存在磁盘之前,必须要将其转化成 关系的形式
3.蜂拥而至的集群
关系型数据库从一开始就不是为了集群设计的,这就为要处理的数据量越来越大的公司带来挑战。所以在2000年到2009年间,谷歌和亚马逊都自主研发自己的数据库并把成果发表在一片极短却影响力巨大的论文上,它们就是BigTable(谷歌)和Dynamo(亚马逊)。4.NoSQL登场
大多数NoSQL数据库都是为了集群而设计的出了图数据库。关系型数据库使用ACID事务来保持整个数据库的一致性,而这种方式本身就与集群环境相冲突。可以理解为NoSQL选择牺牲一致性来达到可扩展性
选用NoSQL的两个主要原因是
1,待处理的数据量很大,或对数据访问的效率要求很高,从而放在集群上
2,想采用一种更为方便的数据交互方式来提高程序开发的效率

相关文章推荐
- Undo Redo log实现事务
- mysql简单入门三——创建表相关语句
- 【搬运】MySQL常见问题及解决(ing)
- mysql 5.7.12 新增 X plugin 详解
- 说说MySQL中的事务
- 几个常见的MySQL语法
- MySql简单入门二——数据库中的数据类型
- MySQL如何安装和启动
- 浅谈MySql的存储引擎(表类型)
- kali(ubuntu)linux Oracle jdk 8安装
- MySQL中的存储引擎讲解(InnoDB,MyISAM,Memory等各存储引擎对比)
- 带你从零了解mysql
- Oracle clob无法修改为blob
- Nginx+Tomcat+Memcached集群Session共享
- 关于rst.Open Trim$(SQL), cnn, adOpenKeyset, adLockOptimistic
- MySql简单入门一
- mongodb聚合
- windows环境下如何安装memcached教程
- MySQL基于gtid特性与xtrabackup的数据恢复
- 开源新闻速递:Ubuntu 官方论坛遭遇了 SQL 注入攻击