互联网编程知识
2016-07-15 23:02
609 查看
1: 数据库
1) 事务的隔离级别有几种. 都是为了解决哪些问题.
● 未授权读取(Read Uncommitted):允许脏读取,但不允许更新丢失。如果一个事务已经开始写数据,则另外一个数据则不允许同时进行写操作,但允许其他事务读此行数据。该隔离级别可以通过“排他写锁”实现。● 授权读取(Read Committed):允许不可重复读取,但不允许脏读取。这可以通过“瞬间共享读锁”和“排他写锁”实现。读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。
● 可重复读取(Repeatable Read):禁止不可重复读取和脏读取,但是有时可能出现幻影数据。这可以通过“共享读锁”和“排他写锁”实现。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。
● 序列化(Serializable):提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行。如果仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到。
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed,它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、虚读和第二类丢失更新这些并发问题,在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁来控制。
2) Spring管理事务的传播机制有哪些. 怎么用.用于什么场景.
| 事务传播行为类型 | 说明 |
| PROPAGATION_REQUIRED | 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。 |
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行。 |
| PROPAGATION_MANDATORY | 使用当前的事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。 |
| PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。 |
几种容易引起误解的组合事务传播行为
当服务接口方法分别使用表1中不同的事务传播行为,且这些接口方法又发生相互调用的情况下,大部分组合都是一目了然,容易理解的。但是,也存在一些容易引起误解的组合事务传播方式。
下面,我们通过两个具体的服务接口的组合调用行为来破解这一难点。这两个服务接口分别是UserService和ForumService,UserSerice有一个addCredits()方法,ForumSerivce#addTopic()方法调用了UserSerice#addCredits()方法,发生关联性服务方法的调用:
public class ForumService {
private UserService userService;
public void addTopic(){①调用其它服务接口的方法
//add Topic…
userService.addCredits();②被关联调用的业务方法
}
}
嵌套调用的事务方法
对Spring事务传播行为最常见的一个误解是:当服务接口方法发生嵌套调用时,被调用的服务方法只能声明为PROPAGATION_NESTED。这种观点犯了望文生义的错误,误认为PROPAGATION_NESTED是专为方法嵌套准备的。这种误解遗害不浅,执有这种误解的开发者错误地认为:应尽量不让Service类的业务方法发生相互的调用,Service类只能调用DAO层的DAO类,以避免产生嵌套事务。
其实,这种顾虑是完全没有必要的,PROPAGATION_REQUIRED已经清楚地告诉我们:事务的方法会足够“聪明”地判断上下文是否已经存在一个事务中,如果已经存在,就加入到这个事务中,否则创建一个新的事务。
依照上面的例子,假设我们将ForumService#addTopic()和UserSerice#addCredits()方法的事务传播行为都设置为PROPAGATION_REQUIRED,这两个方法将运行于同一个事务中。
为了清楚地说明这点,可以将Log4J的日志设置为DEBUG级别,以观察Spring事务管理器内部的运行情况。下面将两个业务方法都设置为PROPAGATION_REQUIRED,Spring所输出的日志信息如下:
Using transaction object
[org.springframework.jdbc.datasource.DataSourceTransactionManager$DataSourceTransactionObject@e3849c]
①为ForumService#addTopic()新建一个事务
Creating new transaction with name [com.baobaotao.service.ForumService.addTopic]: PROPAGATION_REQUIRED,ISOLATION_DEFAULT
Acquired Connection [org.apache.commons.dbcp.PoolableConnection@dc41c5] for JDBC transaction
Switching JDBC Connection [org.apache.commons.dbcp.PoolableConnection@dc41c5] to manual commit
Bound value [org.springframework.jdbc.datasource.ConnectionHolder@ee1ede] for key [org.apache.commons.dbcp.BasicDataSource@4204] to thread [main]
Initializing transaction synchronization
Getting transaction for [com.baobaotao.service.ForumService.addTopic]
Retrieved value [org.springframework.jdbc.datasource.ConnectionHolder@ee1ede] for key [org.apache.commons.dbcp.BasicDataSource@4204] bound to thread [main]
Using transaction object [org.springframework.jdbc.datasource.DataSourceTransactionManager$DataSourceTransactionObject@8b8a47]
②UserService#addCredits()简单地加入到已存在的事务中(即①处创建的事务)
Participating in existing transaction
Getting transaction for [com.baobaotao.service.UserService.addCredits]
Completing transaction for [com.baobaotao.service.UserService.addCredits]
Completing transaction for [com.baobaotao.service.ForumService.addTopic]
Triggering beforeCommit synchronization
Triggering beforeCompletion synchronization
Initiating transaction commit
③调用底层Connection#commit()方法提交事务
Committing JDBC transaction on Connection [org.apache.commons.dbcp.PoolableConnection@dc41c5]
Triggering afterCommit synchronization
Triggering afterCompletion synchronization
Clearing transaction synchronization
嵌套事务
将ForumService#addTopic()设置为PROPAGATION_REQUIRED时,UserSerice#addCredits()设置为PROPAGATION_REQUIRED、PROPAGATION_SUPPORTS、PROPAGATION_MANDATORY时,运行的效果都是一致的(当然,如果单独调用addCredits()就另当别论了)。
当addTopic()运行在一个事务下(如设置为PROPAGATION_REQUIRED),而addCredits()设置为PROPAGATION_NESTED时,如果底层数据源支持保存点,Spring将为内部的addCredits()方法产生的一个内嵌的事务。如果addCredits()对应的内嵌事务执行失败,事务将回滚到addCredits()方法执行前的点,并不会将整个事务回滚。内嵌事务是内层事务的一部分,所以只有外层事务提交时,嵌套事务才能一并提交。
嵌套事务不能够提交,它必须通过外层事务来完成提交的动作,外层事务的回滚也会造成内部事务的回滚。
嵌套事务和新事务
PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED也是容易混淆的两个传播行为。PROPAGATION_REQUIRES_NEW 启动一个新的、和外层事务无关的“内部”事务。该事务拥有自己的独立隔离级别和锁,不依赖于外部事务,独立地提交和回滚。当内部事务开始执行时,外部事务将被挂起,内务事务结束时,外部事务才继续执行。
由此可见, PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的最大区别在于:PROPAGATION_REQUIRES_NEW 将创建一个全新的事务,它和外层事务没有任何关系,而 PROPAGATION_NESTED 将创建一个依赖于外层事务的子事务,当外层事务提交或回滚时,子事务也会连带提交和回滚。
其它需要注意问题
以下几个问题值得注意:
1) 当业务方法被设置为PROPAGATION_MANDATORY时,它就不能被非事务的业务方法调用。如将ForumService#addTopic()设置为PROPAGATION_MANDATORY,如果展现层的Action直接调用addTopic()方法,将引发一个异常。正确的情况是:addTopic()方法必须被另一个带事务的业务方法调用(如ForumService#otherMethod())。所以PROPAGATION_MANDATORY的方法一般都是被其它业务方法间接调用的。
2) 当业务方法被设置为PROPAGATION_NEVER时,它将不能被拥有事务的其它业务方法调用。假设UserService#addCredits()设置为PROPAGATION_NEVER,当ForumService# addTopic()拥有一个事务时,addCredits()方法将抛出异常。所以PROPAGATION_NEVER方法一般是被直接调用的。
3)当方法被设置为PROPAGATION_NOT_SUPPORTED时,外层业务方法的事务会被挂起,当内部方法运行完成后,外层方法的事务重新运行。如果外层方法没有事务,直接运行,不需要做任何其它的事。
小结
在Spring声明式事务管理的配置中,事务传播行为是最容易被误解的配置项,原因在于事务传播行为名称(如PROPAGATION_NESTED:嵌套式事务)和代码结构的类似性上(业务类方法嵌套调用另一个业务类方法)。这种误解在很多Spring开发者中广泛存在,本文深入讲解了Spring事务传播行为对业务方法嵌套调用的真实影响,希望能帮助读者化解对事务传播行为的困惑。
3) mysql 的存储引擎. innodb和myisam. 各有什么特性. 分别用于什么场合.
MyISAM与InnoDB的区别是什么?1、 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
2、 存储空间
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
3、 可移植性、备份及恢复
MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
4、 事务支持
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
5、 AUTO_INCREMENT
MyISAM:可以和其他字段一起建立联合索引。引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
InnoDB:InnoDB中必须包含只有该字段的索引。引擎的自动增长列必须是索引,如果是组合索引也必须是组合索引的第一列。
6、 表锁差异
MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
7、 全文索引
MyISAM:支持 FULLTEXT类型的全文索引
InnoDB:不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。
8、 表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。
InnoDB:如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值。
9、 表的具体行数
MyISAM:保存有表的总行数,如果select count(*) from table;会直接取出出该值。
InnoDB:没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre条件后,myisam和innodb处理的方式都一样。
10、 CURD操作
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。
11、 外键
MyISAM:不支持
InnoDB:支持
通过上述的分析,基本上可以考虑使用InnoDB来替代MyISAM引擎了,原因是InnoDB自身很多良好的特点,比如事务支持、存储 过程、视图、行级锁定等等,在并发很多的情况下,相信InnoDB的表现肯定要比MyISAM强很多。另外,任何一种表都不是万能的,只用恰当的针对业务类型来选择合适的表类型,才能最大的发挥MySQL的性能优势。如果不是很复杂的Web应用,非关键应用,还是可以继续考虑MyISAM的,这个具体情况可以自己斟酌。
4) mysql 的索引. 组合索引的应用.
对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a |a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。下面用几个例子对比查询条件的不同对性能影响.
create table test(
a int,
b int,
c int,
KEY a(a,b,c)
);
优: select * from test where a=10 and b>50
差: select * from test where a50
优: select * from test where order by a
差: select * from test where order by b
差: select * from test where order by c
优: select * from test where a=10 order by a
优: select * from test where a=10 order by b
差: select * from test where a=10 order by c
优: select * from test where a>10 order by a
差: select * from test where a>10 order by b
差: select * from test where a>10 order by c
优: select * from test where a=10 and b=10 order by a
优: select * from test where a=10 and b=10 order by b
优: select * from test where a=10 and b=10 order by c
优: select * from test where a=10 and b=10 order by a
优: select * from test where a=10 and b>10 order by b
差: select * from test where a=10 and b>10 order by c
索引原则
1.索引越少越好
原因:主要在修改数据时,第个索引都要进行更新,降低写速度。
2.最窄的字段放在键的左边
3.避免file sort排序,临时表和表扫描.
于是上网查了下相关的资料:(关于复合索引优化的)
两个或更多个列上的索引被称作复合索引。
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
如:建立 姓名、年龄、性别的复合索引。
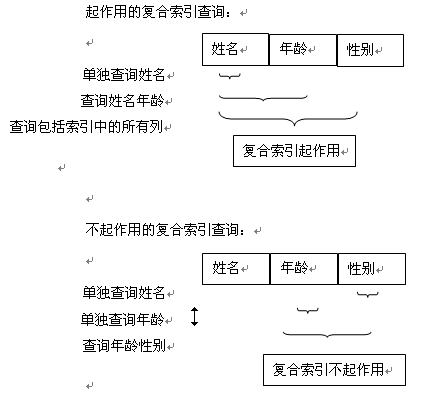
复合索引的建立原则:
如果您很可能仅对一个列多次执行搜索,则该列应该是复合索引中的第一列。如果您很可能对一个两列索引中的两个列执行单独的搜索,则应该创建另一个仅包含第二列的索引。
如上图所示,如果查询中需要对年龄和性别做查询,则应当再新建一个包含年龄和性别的复合索引。
包含多个列的主键始终会自动以复合索引的形式创建索引,其列的顺序是它们在表定义中出现的顺序,而不是在主键定义中指定的顺序。在考虑将来通过主键执行的搜索,确定哪一列应该排在最前面。
请注意,创建复合索引应当包含少数几个列,并且这些列经常在select查询里使用。在复合索引里包含太多的列不仅不会给带来太多好处。而且由于使用相当多的内存来存储复合索引的列的值,其后果是内存溢出和性能降低。
复合索引对排序的优化:
复合索引只对和索引中排序相同或相反的order by 语句优化。
在创建复合索引时,每一列都定义了升序或者是降序。如定义一个复合索引:
Sql代码
CREATE INDEX idx_example
ON table1 (col1 ASC, col2 DESC, col3 ASC)
其中
有三列分别是:col1 升序,col2 降序, col3 升序。现在如果我们执行两个查询
1:Select
col1, col2, col3 from table1 order by col1 ASC, col2 DESC, col3 ASC
和索引顺序相同
2:Select
col1, col2, col3 from table1 order by col1 DESC, col2 ASC, col3 DESC
和索引顺序相反
查询1,2
都可以别复合索引优化。
如果查询为:
Select col1, col2, col3 from table1 order by col1 ASC, col2 ASC, col3 ASC
排序结果和索引完全不同时,此时的查询不会被复合索引优化。
查询优化器在在where查询中的作用:
如果一个多列索引存在于
列 Col1 和 Col2 上,则以下语句:Select * from table where col1=val1 AND col2=val2 查询优化器会试图通过决定哪个索引将找到更少的行。之后用得到的索引去取值。
1.
如果存在一个多列索引,任何最左面的索引前缀能被优化器使用。所以联合索引的顺序不同,影响索引的选择,尽量将值少的放在前面。
如:一个多列索引为 (col1 ,col2, col3)
那么在索引在列 (col1) 、(col1 col2) 、(col1 col2 col3) 的搜索会有作用。
Sql代码
SELECT * FROM tb WHERE col1 = val1
SELECT * FROM tb WHERE col1 = val1 and col2 = val2
SELECT * FROM tb WHERE col1 = val1 and col2 = val2 AND col3 = val3
2.
如果列不构成索引的最左面前缀,则建立的索引将不起作用。
如:
Sql代码
SELECT * FROM tb WHERE col3 = val3
SELECT * FROM tb WHERE col2 = val2
SELECT * FROM tb WHERE col2 = val2 and col3=val3
3.
如果一个 Like 语句的查询条件不以通配符起始则使用索引。
如:%车 或 %车% 不使用索引。
车% 使用索引。
索引的缺点:
1. 占用磁盘空间。
2. 增加了插入和删除的操作时间。一个表拥有的索引越多,插入和删除的速度越慢。如 要求快速录入的系统不宜建过多索引。
下面是一些常见的索引限制问题
1、使用不等于操作符(<>, !=)
下面这种情况,即使在列dept_id有一个索引,查询语句仍然执行一次全表扫描
select * from dept where staff_num <> 1000;
但是开发中的确需要这样的查询,难道没有解决问题的办法了吗?
有!
通过把用 or 语法替代不等号进行查询,就可以使用索引,以避免全表扫描:上面的语句改成下面这样的,就可以使用索引了。
Sql代码
select * from dept shere staff_num < 1000 or dept_id > 1000;
2、使用 is null 或 is not null
使用 is null 或is nuo null也会限制索引的使用,因为数据库并没有定义null值。如果被索引的列中有很多null,就不会使用这个索引(除非索引是一个位图索引,关于位图索引,会在以后的blog文章里做详细解释)。在sql语句中使用null会造成很多麻烦。
解决这个问题的办法就是:建表时把需要索引的列定义为非空(not null)
3、使用函数
如果没有使用基于函数的索引,那么where子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。下面的查询就不会使用索引:
Sql代码
select * from staff where trunc(birthdate) = '01-MAY-82';
但是把函数应用在条件上,索引是可以生效的,把上面的语句改成下面的语句,就可以通过索引进行查找。
Sql代码
select * from staff where birthdate < (to_date('01-MAY-82') + 0.9999);
4、比较不匹配的数据类型
比较不匹配的数据类型也是难于发现的性能问题之一。
下面的例子中,dept_id是一个varchar2型的字段,在这个字段上有索引,但是下面的语句会执行全表扫描。
Sql代码
select * from dept where dept_id = 900198;
这是因为oracle会自动把where子句转换成to_number(dept_id)=900198,就是3所说的情况,这样就限制了索引的使用。
把SQL语句改为如下形式就可以使用索引
Sql代码
select * from dept where dept_id = '900198';
2: Spring 的AOP和IOC. 多数据源管理
同一个项目有时会涉及到多个数据库,也就是多数据源。多数据源又可以分为两种情况:1)两个或多个数据库没有相关性,各自独立,其实这种可以作为两个项目来开发。比如在游戏开发中一个数据库是平台数据库,其它还有平台下的游戏对应的数据库;
2)两个或多个数据库是master-slave的关系,比如有mysql搭建一个 master-master,其后又带有多个slave;或者采用MHA搭建的master-slave复制;
目前我所知道的 Spring 多数据源的搭建大概有两种方式,可以根据多数据源的情况进行选择。
1. 采用spring配置文件直接配置多个数据源
比如针对两个数据库没有相关性的情况,可以采用直接在spring的配置文件中配置多个数据源,然后分别进行事务的配置,如下所示:
<context:component-scan base-package="net.aazj.service,net.aazj.aop" />
<context:component-scan base-package="net.aazj.aop" />
<!-- 引入属性文件 -->
<context:property-placeholder location="classpath:config/db.properties" />
<!-- 配置数据源 -->
<bean name="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="url" value="${jdbc_url}" />
<property name="username" value="${jdbc_username}" />
<property name="password" value="${jdbc_password}" />
<!-- 初始化连接大小 -->
<property name="initialSize" value="0" />
<!-- 连接池最大使用连接数量 -->
<property name="maxActive" value="20" />
<!-- 连接池最大空闲 -->
<property name="maxIdle" value="20" />
<!-- 连接池最小空闲 -->
<property name="minIdle" value="0" />
<!-- 获取连接最大等待时间 -->
<property name="maxWait" value="60000" />
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="configLocation" value="classpath:config/mybatis-config.xml" />
<property name="mapperLocations" value="classpath*:config/mappers/**/*.xml" />
</bean>
<!-- Transaction manager for a single JDBC DataSource -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 使用annotation定义事务 -->
<tx:annotation-driven transaction-manager="transactionManager" />
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="net.aazj.mapper" />
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
</bean>
<!-- Enables the use of the @AspectJ style of Spring AOP -->
<aop:aspectj-autoproxy/>
<!-- ===============第二个数据源的配置=============== -->
<bean name="dataSource_2" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="url" value="${jdbc_url_2}" />
<property name="username" value="${jdbc_username_2}" />
<property name="password" value="${jdbc_password_2}" />
<!-- 初始化连接大小 -->
<property name="initialSize" value="0" />
<!-- 连接池最大使用连接数量 -->
<property name="maxActive" value="20" />
<!-- 连接池最大空闲 -->
<property name="maxIdle" value="20" />
<!-- 连接池最小空闲 -->
<property name="minIdle" value="0" />
<!-- 获取连接最大等待时间 -->
<property name="maxWait" value="60000" />
</bean>
<bean id="sqlSessionFactory_slave" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource_2" />
<property name="configLocation" value="classpath:config/mybatis-config-2.xml" />
<property name="mapperLocations" value="classpath*:config/mappers2/**/*.xml" />
</bean>
<!-- Transaction manager for a single JDBC DataSource -->
<bean id="transactionManager_2" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource_2" />
</bean>
<!-- 使用annotation定义事务 -->
<tx:annotation-driven transaction-manager="transactionManager_2" />
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="net.aazj.mapper2" />
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory_2"/>
</bean>如上所示,我们分别配置了两个 dataSource,两个sqlSessionFactory,两个transactionManager,以及关键的地方在于MapperScannerConfigurer 的配置——使用sqlSessionFactoryBeanName属性,注入不同的sqlSessionFactory的名称,这样的话,就为不同的数据库对应的 mapper 接口注入了对应的 sqlSessionFactory。
需要注意的是,多个数据库的这种配置是不支持分布式事务的,也就是同一个事务中,不能操作多个数据库。这种配置方式的优点是很简单,但是却不灵活。对于master-slave类型的多数据源配置而言不太适应,master-slave性的多数据源的配置,需要特别灵活,需要根据业务的类型进行细致的配置。比如对于一些耗时特别大的select语句,我们希望放到slave上执行,而对于update,delete等操作肯定是只能在master上执行的,另外对于一些实时性要求很高的select语句,我们也可能需要放到master上执行——比如一个场景是我去商城购买一件兵器,购买操作的很定是master,同时购买完成之后,需要重新查询出我所拥有的兵器和金币,那么这个查询可能也需要防止master上执行,而不能放在slave上去执行,因为slave上可能存在延时,我们可不希望玩家发现购买成功之后,在背包中却找不到兵器的情况出现。
所以对于master-slave类型的多数据源的配置,需要根据业务来进行灵活的配置,哪些select可以放到slave上,哪些select不能放到slave上。所以上面的那种所数据源的配置就不太适应了。
2. 基于 AbstractRoutingDataSource 和 AOP 的多数据源的配置
基本原理是,我们自己定义一个DataSource类ThreadLocalRountingDataSource,来继承AbstractRoutingDataSource,然后在配置文件中向ThreadLocalRountingDataSource注入 master 和 slave 的数据源,然后通过 AOP 来灵活配置,在哪些地方选择 master 数据源,在哪些地方需要选择 slave数据源。下面看代码实现:
1)先定义一个enum来表示不同的数据源:
package net.aazj.enums;
/**
* 数据源的类别:master/slave
*/
public enum DataSources {
MASTER, SLAVE
}2)通过 TheadLocal 来保存每个线程选择哪个数据源的标志(key):
package net.aazj.util;
import net.aazj.enums.DataSources;
public class DataSourceTypeManager {
private static final ThreadLocal<DataSources> dataSourceTypes = new ThreadLocal<DataSources>(){
@Override
protected DataSources initialValue(){
return DataSources.MASTER;
}
};
public static DataSources get(){
return dataSourceTypes.get();
}
public static void set(DataSources dataSourceType){
dataSourceTypes.set(dataSourceType);
}
public static void reset(){
dataSourceTypes.set(DataSources.MASTER0);
}
}3)定义 ThreadLocalRountingDataSource,继承AbstractRoutingDataSource:
package net.aazj.util;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
public class ThreadLocalRountingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DataSourceTypeManager.get();
}
}4)在配置文件中向 ThreadLocalRountingDataSource 注入 master 和 slave 的数据源:
<context:component-scan base-package="net.aazj.service,net.aazj.aop" />
<context:component-scan base-package="net.aazj.aop" />
<!-- 引入属性文件 -->
<context:property-placeholder location="classpath:config/db.properties" />
<!-- 配置数据源Master -->
<bean name="dataSourceMaster" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="url" value="${jdbc_url}" />
<property name="username" value="${jdbc_username}" />
<property name="password" value="${jdbc_password}" />
<!-- 初始化连接大小 -->
<property name="initialSize" value="0" />
<!-- 连接池最大使用连接数量 -->
<property name="maxActive" value="20" />
<!-- 连接池最大空闲 -->
<property name="maxIdle" value="20" />
<!-- 连接池最小空闲 -->
<property name="minIdle" value="0" />
<!-- 获取连接最大等待时间 -->
<property name="maxWait" value="60000" />
</bean>
<!-- 配置数据源Slave -->
<bean name="dataSourceSlave" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="url" value="${jdbc_url_slave}" />
<property name="username" value="${jdbc_username_slave}" />
<property name="password" value="${jdbc_password_slave}" />
<!-- 初始化连接大小 -->
<property name="initialSize" value="0" />
<!-- 连接池最大使用连接数量 -->
<property name="maxActive" value="20" />
<!-- 连接池最大空闲 -->
<property name="maxIdle" value="20" />
<!-- 连接池最小空闲 -->
<property name="minIdle" value="0" />
<!-- 获取连接最大等待时间 -->
<property name="maxWait" value="60000" />
</bean>
<bean id="dataSource" class="net.aazj.util.ThreadLocalRountingDataSource">
<property name="defaultTargetDataSource" ref="dataSourceMaster" />
<property name="targetDataSources">
<map key-type="net.aazj.enums.DataSources">
<entry key="MASTER" value-ref="dataSourceMaster"/>
<entry key="SLAVE" value-ref="dataSourceSlave"/>
<!-- 这里还可以加多个dataSource -->
</map>
</property>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="configLocation" value="classpath:config/mybatis-config.xml" />
<property name="mapperLocations" value="classpath*:config/mappers/**/*.xml" />
</bean>
<!-- Transaction manager for a single JDBC DataSource -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 使用annotation定义事务 -->
<tx:annotation-driven transaction-manager="transactionManager" />
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="net.aazj.mapper" />
<!-- <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/> -->
</bean>上面spring的配置文件中,我们针对master数据库和slave数据库分别定义了dataSourceMaster和dataSourceSlave两个dataSource,然后注入到<bean id="dataSource"class="net.aazj.util.ThreadLocalRountingDataSource"> 中,这样我们的dataSource就可以来根据 key 的不同来选择dataSourceMaster和
dataSourceSlave了。
5)使用Spring AOP 来指定 dataSource 的 key ,从而dataSource会根据key选择 dataSourceMaster 和 dataSourceSlave:
package net.aazj.aop;
import net.aazj.enums.DataSources;
import net.aazj.util.DataSourceTypeManager;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
@Aspect // for aop
@Component // for auto scan
@Order(0) // execute before @Transactional
public class DataSourceInterceptor {
@Pointcut("execution(public * net.aazj.service..*.getUser(..))")
public void dataSourceSlave(){};
@Before("dataSourceSlave()")
public void before(JoinPoint jp) {
DataSourceTypeManager.set(DataSources.SLAVE);
}
// ... ...
}这里我们定义了一个 Aspect 类,我们使用 @Before 来在符合 @Pointcut("execution(public * net.aazj.service..*.getUser(..))") 中的方法被调用之前,调用DataSourceTypeManager.set(DataSources.SLAVE) 设置了
key 的类型为 DataSources.SLAVE,所以 dataSource 会根据key=DataSources.SLAVE 选择 dataSourceSlave 这个dataSource。所以该方法对于的sql语句会在slave数据库上执行(经网友老刘1987提醒,这里存在多个Aspect之间的一个执行顺序的问题,必须保证切换数据源的Aspect必须在@Transactional这个Aspect之前执行,所以这里使用了@Order(0)来保证切换数据源先于@Transactional执行)。
我们可以不断的扩充 DataSourceInterceptor 这个 Aspect,在中进行各种各样的定义,来为某个service的某个方法指定合适的数据源对应的dataSource。
这样我们就可以使用 Spring AOP 的强大功能来,十分灵活进行配置了。
6)AbstractRoutingDataSource原理剖析
ThreadLocalRountingDataSource继承了AbstractRoutingDataSource,实现其抽象方法protected abstract Object determineCurrentLookupKey(); 从而实现对不同数据源的路由功能。我们从源码入手分析下其中原理:
public abstract class AbstractRoutingDataSource extends AbstractDataSource implements InitializingBean
AbstractRoutingDataSource 实现了 InitializingBean 那么spring在初始化该bean时,会调用InitializingBean的接口 void afterPropertiesSet() throws Exception; 我们看下AbstractRoutingDataSource是如何实现这个接口的:
@Override
public void afterPropertiesSet() {
if (this.targetDataSources == null) {
throw new IllegalArgumentException("Property 'targetDataSources' is required");
}
this.resolvedDataSources = new HashMap<Object, DataSource>(this.targetDataSources.size());
for (Map.Entry<Object, Object> entry : this.targetDataSources.entrySet()) {
Object lookupKey = resolveSpecifiedLookupKey(entry.getKey());
DataSource dataSource = resolveSpecifiedDataSource(entry.getValue());
this.resolvedDataSources.put(lookupKey, dataSource);
}
if (this.defaultTargetDataSource != null) {
this.resolvedDefaultDataSource = resolveSpecifiedDataSource(this.defaultTargetDataSource);
}
}targetDataSources 是我们在xml配置文件中注入的 dataSourceMaster 和 dataSourceSlave. afterPropertiesSet方法就是使用注入的 dataSourceMaster 和 dataSourceSlave来构造一个HashMap——resolvedDataSources。方便后面根据 key 从该map 中取得对应的dataSource。 我们在看下 AbstractDataSource 接口中的 Connection getConnection() throws SQLException; 是如何实现的:
@Override
public Connection getConnection() throws SQLException {
return determineTargetDataSource().getConnection();
}关键在于 determineTargetDataSource(),根据方法名就可以看出,应该此处就决定了使用哪个 dataSource :
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}Object lookupKey = determineCurrentLookupKey(); 该方法是我们实现的,在其中获取ThreadLocal中保存的 key 值。获得了key之后, 在从afterPropertiesSet()中初始化好了的resolvedDataSources这个map中获得key对应的dataSource。而ThreadLocal中保存的 key 值 是通过AOP的方式在调用service中相关方法之前设置好的。OK,到此搞定!
7)扩展 ThreadLocalRountingDataSource
上面我们只是实现了 master-slave 数据源的选择。如果有多台 master 或者有多台 slave。多台master组成一个HA,要实现当其中一台master挂了是,自动切换到另一台master,这个功能可以使用LVS/Keepalived来实现,也可以通过进一步扩展ThreadLocalRountingDataSource来实现,可以另外加一个线程专门来每个一秒来测试mysql是否正常来实现。同样对于多台slave之间要实现负载均衡,同时当一台slave挂了时,要实现将其从负载均衡中去除掉,这个功能既可以使用LVS/Keepalived来实现,同样也可以通过近一步扩展ThreadLocalRountingDataSource来实现。
3. 总结
从本文中我们可以体会到AOP的强大和灵活。
本文使用的是mybatis,其实使用Hibernate也应该是相似的配置。
3: Redis 分布式. 主从搭建.
redis分布式(主从复制)
Redis主从复制配置和使用都非常简单。通过主从复制可以允许多个slave server拥有和master server相同的数据库副本。Redis的复制原理:
本身就是Master发送数据给slave,只是第一次连接是Slave向Master发送同步请求,其它的都是Master主动向Slave发送数据。
Redis主从复制的过程:
当设置好slave服务器后,slave会建立和master的连接,然后发送sync命令。无论是第一次同步建立的连接还是连接断开后的自动尝试重新连接,master都会启动一个后台进程,将数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存起来。后台进程完成写文件后,master就发送文件给slave,slave将文件保存到磁盘上,然后加载到内存恢复数据库快照到slave上的数据库中。
master后续收到的写命令都会通过开始建立的连接发送给slave。从master到slave的同步数据的命令和从client发送的命令使用相同的协议格式。当master和slave的连接断开时slave可以自动尝试重新建立连接。如果master同时收到多个slave发来的同步连接命令,只会使用启动一个进程来写数据库镜像,然后发送给所有slave。
Redis主从复制特点:
1.master可以拥有多个slave
2.多个slave不但可以连接同一个master外,还可以连接到其它slave
3.主从复制不会阻塞master,在同步数据时,master可以继续处理client请求
4.提高系统的伸缩性
配置slave服务器(master无需特别配置,只配置slave即可):
vi编辑配置文件
[root@martin etc]# vi /usr/local/redis/etc/redis.conf
1.在约116行找到 # slaveof <masterip> <masterport> 这里是主服务器的IP和端口(从属于哪个master的哪个port)
slaveof 192.168.1.26 6379
2.在约124行找到 # masterauth <master-password> 这里是主服务器的授权密码(如果master没有设置密码此处则不用配置)
masterauth 123456
3.重启slave服务器,重新登录到slave
4.查看服务器角色(身份):
redis 127.0.0.1:6379> info
......
role:slave #角色
master_host:192.168.1.26 #master主机
master_port:6379 #master端口
master_link_status:up #master连接状态:up同步;down异步
master_last_io_seconds_ago:4 #最后一次同步在见秒钟前
master_sync_in_progress:0
slave_priority:100
db0:keys=4,expires=0 #数据库有几个key,过期key的数量
总结:照此方法,此slave机还可以被充当为其它服务器的master。
4: Solr的搭建 . 集群. 使用.
5: RocketMQ 原理. 使用. 使用MQ的场景以及需要注意的地方. (重复消费/消息丢失)
</pre><span style="font-family: Verdana, Arial, Helvetica, sans-serif; font-size: 13.92px; line-height: 20.88px;"></span></div>http://www.cnblogs.com/super-d2/p/4154541.html<div><span style="font-family: Verdana, Arial, Helvetica, sans-serif; font-size: 13.92px; line-height: 20.88px;"></span></div><h1> 6) RPC框架 . 如Dubbo的使用, Dubbo的通信机制. </h1><div>http://doc.okbase.net/zhouyuqwert/archive/126965.html</div><h1> 7) Zookeeper: 原理与使用.如何选主. 如何注册自己的程序到zookeeper. </h1><div>http://blog.csdn.net/gs80140/article/details/51496925</div><h1> 8) maven: 原理. 生命周期. 私服. 本地仓库. 远程仓库. 依赖. 依赖冲突. </h1><h1> 9) Git: Git原理以及使用. 分支. Tag. 冲突</h1><h1> 10) JVM内存分配(常见的各种内存溢出以及配置优化). GC回收策略. </h1><div><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> JVM中的内存使用方式,包括虚拟机内存区域的划分,Java对象分配时的处理原则和逻辑,以及我们日常开发中最需要关心的GC回收的策略和算法,是开发出拥有出色而稳定的Java软件产品所必须深刻理解的。从各种途径阅读到的讲解JVM内存管理,GC过程和策略的资料也都从不同的侧重点讲述了这些话题。我在这里按照自己的理解总结一下,算是整理下自己的思路,以让自己JVM方面的知识体系结构化,打下更扎实的基础。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 1. JVM的运行时数据区域的划分</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;">JVM在执行Java程序过程中会将其管理的内存划分为不同的部分作为各自的不同用途。其中,JVM下所有线程共享的部分有: 方法区及堆;而每个独立运行的线程,各自又享有各自的1)虚拟机栈 2)程序计数器 3)本地方法栈。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 本文重点总结一下方法区及堆的内存使用和分配。各个线程独享的虚拟机栈本地方法栈等等以后再补充。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 1)方法区</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 其实就是平时我们常说的永久代(PermGen),在Java程序调试时候会碰到的"<span style="line-height: 21px;">java.lang.OutOfMemoryError: PermGen Space</span>" 就发生在这个区域。这个永久代是各个线程共享的JVM内存区域,用于存储虚拟机已加载的类信息,常量,静态变量,即使编译器编译后的代码等等数据,还会包括一些<span style="line-height: 21px;">跟类有关的对象数组和类型数组,</span><span style="line-height: 21px;">JVM</span><span style="line-height: 21px; border: 0px; margin: 0px; padding: 0px;">使用的内部对象,以及</span><span style="line-height: 21px;">编译器优化的使用信息等。在过去的JVM版本中,常量池也是放在永久代的。但在HotSpot 的JDK 1.7开始,字符串常量池已经从永久代中移出了。</span><span style="line-height: 21px;">方法区的大小,在JVM启动参数里可以用</span><span style="line-height: 21px; border: 0px; margin: 0px; padding: 0px;">-XX:MaxPermSize=XXXM来设置</span></span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="line-height: 21px; border: 0px; margin: 0px; padding: 0px;"><span style="font-family: KaiTi_GB2312;"> 2) Java堆</span></span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="line-height: 21px; border: 0px; margin: 0px; padding: 0px;"><span style="font-family: KaiTi_GB2312;"> 这是JVM所管理的最大的一块内存区域,被所有线程共享。该区域唯一的用途就是用来存放对象实例。所有的Java对象实例及数组都要在堆上分配内存。于是堆也成了垃圾收集器管理的最主要区域,本文总结的对象分配及垃圾回收的策略,主要就是针对堆这个内存区域的啦。JVM启动参数-Xmx及-Xms可用来控制堆内存大小。</span></span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 2. 创建对象时的分配策略和原则</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 普通Java对象的创建,通常是以new关键字来调用一个类的构造方法开始的。程序执行到此时,在Java堆内存中的对象分配工作便开始了。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 1)第一步,检查该new指令的参数,是否在常量池中能够定位到一个类的引用。如String对象,如果字符串常量池中已有该String的引用,则直接返回。字符串常量池又是另一个话题,这里先不讨论了。查找常量池后,则要检查该类是否已被加载,解析及初始化过。如未加载该类,则先要执行相应的类加载过程。在类加载完成之后,该new指令需要分配多大的内存空间就可以被确定了。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 2)第二步,就是给该对象分配内存了。详细的分配策略及细节,跟使用的垃圾收集器组合有关系,还有JVM中与堆内存相关的参数设置。这里总结一下一些通用的规则。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 通常情况下,对象在新生代的Eden区进行分配。如果Eden区没有足够空间进行分配时,JVM将发起一次MinorGC。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 大对象,即新生代没有足够的连续空间可供其使用的对象,通常是那种需要大量连续内存空间的长字符串或者数组对象,在其所需空间大于 -XX:PretenureSizeThreshold参数时,直接在老年代分配。手动设置这个值可避免在年轻代的Eden区及Survivor区之间发生大量的内存复制,而复制后依然不够分配。很消耗CPU运行时间的喔</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 我们在设计程序时候亦应该尽量避免大对象的分配,尤其是生命周期很短的大对象分配。因为这会导致Eden区还有大量空间的情况下(但空间不连续,没法容纳我们需要的大对象),提前触发GC来获得连续空间。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 3. GC回收策略及算法</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 1) GC分代的方式</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> JVM为了更有效地管理和回收堆内存,以HotSpot虚拟机为例,其基于以下假设,将堆内存从物理上划分为两个部分,即年轻代(Young Generation)和年老代(Old Generation)。这两个假设便是: </span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"></span></p><ul style="color: rgb(51, 51, 51); font-size: 14px; border: 0px; margin: 0px 0px 20px; padding: 0px; list-style-position: inside; font-family: 'Microsoft YaHei', 宋体, 'Myriad Pro', Lato, 'Helvetica Neue', Helvetica, Arial, sans-serif; line-height: 21px;"><li style="border: 0px; margin: 0px; padding: 0px;"><span style="white-space: pre;"></span>大多数对象的生命周期都不会很长。也就意味着这些对象的引用会很快变得不可达;</li><li style="border: 0px; margin: 0px; padding: 0px;"> 只有很少的由老对象(创建时间较长的对象)指向新生对象的引用</li></ul><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 对于年轻代,绝大多数新分配对象会在这块区域被创建;</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 年老代,占用空间会比年轻代多,年轻代中进行minor GC时存活下来的对象最终会进入这里。年老代中发生GC(即Full GC)的次数要少得多;</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 而年轻代又会被划分为三个区域,通常是一个较大的区域主要用作对象分配的,叫Eden区;以及两个Survivor区。Eden区无需多说,对象分配时首先从这里分配空间。而两个Survivor的作用在于,Eden中经过一次minor GC后存活下来的对象,会进入其中一个Survivor区,而另一个Survivor区域则留作当前Survivor区的备份空间。当Survivor A区域中的空间饱和的时候,此时发生的Minor GC会将Survivor A中依然存活的对象,以及Eden中存活的对象,都复制到Survivor B,然后清空Survivor A。就这样循环往复,两个Survivor之间互相复制。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> GC采用分代收集思想,于是就有了对象年龄计数这一概念。出生在Eden的对象,经过一次Minor GC仍存活,年龄+1。如果其能被Survivor区容纳,将进入Survivor区域。也就是说只要其活过一次minorGC,就可进入survivor区了。随后每一次minorGC, 活下来的对象年龄都+1,达到一定年龄的对象将进入老年代(默认是15岁)。该阈值可通过 -XX:MaxTenuringThreshold设置。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 同时,如果survivor区内很多年龄不太大的对象怎么办呢,大家年龄都不足以进入老年代,但数量太多,survivor也吃不消啊。于是还有一条规则,就是survivor区内所有年龄相同的对象大小总和如果超过survivor区空间的一半,年龄大于等于该年龄的对象都直接进入老年代,不受参数MaxTenuringThreshold参数的限制了。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;">a) Minor GC: 新生代GC。发生相对频繁,回收速度也较快。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;">b) Major GC/Full GC: 老年代GC。通常会伴随一次Minor GC,速度较慢,通常比Minor GC耗时多10倍以上。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 2) GC回收策略</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> JVM回收的对象,是那些已经不再被使用的对象。而判断是否不再被使用的原则,可以从两个方面来描述。简单来说,第一是不可到达,第二是引用计数为0。这两点,其实说的是一回事,从不同的方面来描述罢了。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 详细来说,不可到达,就是说从GC Root出发,对象之间的引用链没有指向的对象,我们称之为不可到达。引用计数为0其实说的就是从GC Root开始的对象引用链到达该对象的引用计数为0,即没有可到达的引用路径指向它了。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 可作为GC Root的对象包括:*方法区中加载的类的静态字段引用的对象,常量引用的对象;*每个线程对象的虚拟机栈中引用的对象;*本地方法栈中引用的本地对象或常量。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 既然说了可到达,那么提一句弱引用及软引用。弱引用即不影响可到达性的引用,如果没有强引用只有弱引用的对象,GC照样回收,也就是说弱引用是被GC直接忽略的。软引用则比弱引用略强硬一些,通常用来描述有用但非必须的对象。在系统将要发生内存溢出时会把软引用对象进行一次回收。</span></p><p style="color: rgb(51, 51, 51); font-family: Arial; font-size: 14px; line-height: 26px;"><span style="font-family: KaiTi_GB2312;"> 至于具体的对象回收算法,其实现就要取决于垃圾收集器了。不同的垃圾收集器有其不同的回收算法。概括地讲,比较典型的包括“标记-清除”,“标记-复制-清除”,“标记-清除-整理”等等。</span></p></div><h1> 11) 连接池技术. (数据库连接池. Redis客户端连接池)</h1><div>http://greemranqq.iteye.com/blog/1969273</div><div><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 16px; color: rgb(61, 70, 77); font-family: 'Lantinghei SC', 'Open Sans', Arial, 'Hiragino Sans GB', 'Microsoft YaHei', STHeiti, 'WenQuanYi Micro Hei', SimSun, sans-serif; font-size: 16px; line-height: 30px;">一、先来搞清楚两个问题:Redis 到底是什么,数据库连接池又是怎么一回事?</p><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 16px; color: rgb(61, 70, 77); font-family: 'Lantinghei SC', 'Open Sans', Arial, 'Hiragino Sans GB', 'Microsoft YaHei', STHeiti, 'WenQuanYi Micro Hei', SimSun, sans-serif; font-size: 16px; line-height: 30px;"> 1. Redis 是一个key-value<a target=_blank href="http://baike.baidu.com/view/51839.htm" target="_blank" rel="nofollow" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; outline: 0px; border: none; text-decoration: none; color: rgb(68, 102, 187); transition: color 0.3s;">存储系统</a>。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(<a target=_blank href="http://baike.baidu.com/view/549479.htm" target="_blank" rel="nofollow" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; outline: 0px; border: none; text-decoration: none; color: rgb(68, 102, 187); transition: color 0.3s;">链表</a>)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些<a target=_blank href="http://baike.baidu.com/view/675645.htm" target="_blank" rel="nofollow" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; outline: 0px; border: none; text-decoration: none; color: rgb(68, 102, 187); transition: color 0.3s;">数据类型</a>都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。</p><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 16px; color: rgb(61, 70, 77); font-family: 'Lantinghei SC', 'Open Sans', Arial, 'Hiragino Sans GB', 'Microsoft YaHei', STHeiti, 'WenQuanYi Micro Hei', SimSun, sans-serif; font-size: 16px; line-height: 30px;"> Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了<a target=_blank href="http://baike.baidu.com/view/794242.htm" target="_blank" rel="nofollow" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; outline: 0px; border: none; text-decoration: none; color: rgb(68, 102, 187); transition: color 0.3s;">memcached</a>这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Python,Ruby,Erlang,PHP客户端,使用很方便。</p><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 16px; color: rgb(61, 70, 77); font-family: 'Lantinghei SC', 'Open Sans', Arial, 'Hiragino Sans GB', 'Microsoft YaHei', STHeiti, 'WenQuanYi Micro Hei', SimSun, sans-serif; font-size: 16px; line-height: 30px;"> Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。</p><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 16px; color: rgb(61, 70, 77); font-family: 'Lantinghei SC', 'Open Sans', Arial, 'Hiragino Sans GB', 'Microsoft YaHei', STHeiti, 'WenQuanYi Micro Hei', SimSun, sans-serif; font-size: 16px; line-height: 30px;"> 2. 数据库连接池:</p><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 16px; color: rgb(61, 70, 77); font-family: 'Lantinghei SC', 'Open Sans', Arial, 'Hiragino Sans GB', 'Microsoft YaHei', STHeiti, 'WenQuanYi Micro Hei', SimSun, sans-serif; font-size: 16px; line-height: 30px;"> <a target=_blank href="http://baike.baidu.com/view/1088.htm" target="_blank" rel="nofollow" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; outline: 0px; border: none; text-decoration: none; color: rgb(68, 102, 187); transition: color 0.3s;">数据库</a>连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些<a target=_blank href="http://baike.baidu.com/view/1088.htm" target="_blank" rel="nofollow" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; outline: 0px; border: none; text-decoration: none; color: rgb(68, 102, 187); transition: color 0.3s;">数据库</a>连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大<a target=_blank href="http://baike.baidu.com/view/1088.htm" target="_blank" rel="nofollow" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; outline: 0px; border: none; text-decoration: none; color: rgb(68, 102, 187); transition: color 0.3s;">数据库</a>连接数量限定了这个连接池能占有的<a target=_blank href="http://baike.baidu.com/view/253275.htm" target="_blank" rel="nofollow" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; outline: 0px; border: none; text-decoration: none; color: rgb(68, 102, 187); transition: color 0.3s;">最大连接数</a>,当<a target=_blank href="http://baike.baidu.com/view/330120.htm" target="_blank" rel="nofollow" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; outline: 0px; border: none; text-decoration: none; color: rgb(68, 102, 187); transition: color 0.3s;">应用程序</a>向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。</p><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 16px; color: rgb(61, 70, 77); font-family: 'Lantinghei SC', 'Open Sans', Arial, 'Hiragino Sans GB', 'Microsoft YaHei', STHeiti, 'WenQuanYi Micro Hei', SimSun, sans-serif; font-size: 16px; line-height: 30px;"><span style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><span style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; font-size: 20px;">二、<span style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; font-family: 'microsoft yahei';"> </span>redis_java操作</span></span></p><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 16px; color: rgb(61, 70, 77); font-family: 'Lantinghei SC', 'Open Sans', Arial, 'Hiragino Sans GB', 'Microsoft YaHei', STHeiti, 'WenQuanYi Micro Hei', SimSun, sans-serif; font-size: 16px; line-height: 30px;"><span style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; font-size: 12.5px;"></span></p><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 0px; margin-top: 0px; padding-top: 0px; padding-bottom: 0px; color: rgb(85, 85, 85); font-family: 'microsoft yahei'; font-size: 15.5556px; line-height: 35px;">Jedis 客户端实现</p><p style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; margin-bottom: 0px; margin-top: 0px; padding-top: 0px; padding-bottom: 0px; color: rgb(85, 85, 85); font-family: 'microsoft yahei'; font-size: 15.5556px; line-height: 35px;">Maven pom文件 加入依赖</p><pre class="brush:java;toolbar: true; auto-links: false;" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; color: rgb(61, 70, 77); line-height: 30px;"><code class="hljs xml" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent; display: block; padding: 10px; color: rgb(119, 119, 119); border-radius: 4px; overflow-x: auto; line-height: 1.4; word-wrap: normal; background: rgb(253, 246, 227);"><span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">dependencies</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">dependency</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">groupId</span>></span>redis.clients<span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">groupId</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">artifactId</span>></span>jedis<span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">artifactId</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">version</span>></span>2.1.0<span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">version</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">dependency</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">dependency</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">groupId</span>></span>junit<span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">groupId</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">artifactId</span>></span>junit<span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">artifactId</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">version</span>></span>4.8.2<span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">version</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"><<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">scope</span>></span>test<span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">scope</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">dependency</span>></span> <span class="hljs-tag" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;"></<span class="hljs-name" style="box-sizing: inherit; -webkit-tap-highlight-color: transparent;">dependencies</span>></span></code>
Jedis 简单使用
/* * JedisTest.java */ package com.x.java2000_wl; import org.junit.Before; import org.junit.Test; import redis.clients.jedis.Jedis; /** * jedis 简单使用 * @author http://blog.csdn.net/java2000_wl * @version <b>1.0</b> */ public class JedisSimpleTest { private Jedis jedis; /** * 初始化连接 * <br>------------------------------<br> */ @Before public void beforeClass() { jedis = new Jedis("127.0.0.1"); jedis.auth("java2000_wl"); } /** * set 新增 * <br>------------------------------<br> */ @Test public void testSet() { jedis.set("blog", "java2000_wl"); } /** * 获取 * <br>------------------------------<br> */ @Test public void testGet() { System.out.println(jedis.get("blog")); } /** * 修改key * <br>------------------------------<br> */ @Test public void testRenameKey() { jedis.rename("blog", "blog_new"); } /** * 按key删除 * <br>------------------------------<br> */ @Test public void testDel() { jedis.del("blog_new"); } /** * 获取所有的key * <br>------------------------------<br> */ @Test public void testKeys() { System.out.println(jedis.keys("*")); } }
使用commons-pool连接池
/* * JedisPoolTest.java */ package com.x.java2000_wl; import java.util.ResourceBundle; import org.junit.Assert; import org.junit.BeforeClass; import org.junit.Test; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; /** * jedis Pool 操作 * @author http://blog.csdn.net/java2000_wl * @version <b>1.0</b> */ public class JedisPoolTest { private static JedisPool jedisPool; /** * initPoolConfig * <br>------------------------------<br> * @return */ private static JedisPoolConfig initPoolConfig() { JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); // 控制一个pool最多有多少个可用的的jedis实例 jedisPoolConfig.setMaxActive(1000); // 最大能够保持空闲状态的对象数 jedisPoolConfig.setMaxIdle(300); // 超时时间 jedisPoolConfig.setMaxWait(1000); // 在borrow一个jedis实例时,是否提前进行alidate操作;如果为true,则得到的jedis实例均是可用的; jedisPoolConfig.setTestOnBorrow(true); // 在还会给pool时,是否提前进行validate操作 jedisPoolConfig.setTestOnReturn(true); return jedisPoolConfig; } /** * 初始化jedis连接池 * <br>------------------------------<br> */ @BeforeClass public static void before() { JedisPoolConfig jedisPoolConfig = initPoolConfig(); // 属性文件读取参数信息 ResourceBundle bundle = ResourceBundle.getBundle("redis_config"); String host = bundle.getString("redis.host"); int port = Integer.valueOf(bundle.getString("redis.port")); int timeout = Integer.valueOf(bundle.getString("redis.timeout")); String password = bundle.getString("redis.password"); // 构造连接池 jedisPool = new JedisPool(jedisPoolConfig, host, port, timeout, password); } @Test public void testSet() { Jedis jedis = null; // 从池中获取一个jedis实例 try { jedis = jedisPool.getResource(); jedis.set("blog_pool", "java2000_wl"); } catch (Exception e) { // 销毁对象 jedisPool.returnBrokenResource(jedis); Assert.fail(e.getMessage()); } finally { // 还会到连接池 jedisPool.returnResource(jedis); } } @Test public void testGet() { Jedis jedis = null; try { // 从池中获取一个jedis实例 jedis = jedisPool.getResource(); System.out.println(jedis.get("blog_pool")); } catch (Exception e) { // 销毁对象 jedisPool.returnBrokenResource(jedis); Assert.fail(e.getMessage()); } finally { // 还会到连接池 jedisPool.returnResource(jedis); } } }
[/code]

相关文章推荐
- 日本聊天应用LINE上市
- 日本聊天应用LINE上市
- Everything使用攻略和技巧
- 互联网趋势其实很浮夸
- 你需要一个专业的测试工程师
- 如何快速搭建一个完整的移动直播系统?
- “互联网+金融”案例分享:无锡农商行乘“互联网+”快车
- 互联网数据化运营管理:复购篇
- Open-Falcon 互联网企业级监控系统
- 免密支付存隐患,Uber支付账号被盗刷
- 互联网 免费的WebService接口
- 一线互联网公司的前端开发流程
- 大型系统重构的步骤简单梳理
- 互联网数据化运营管理:复购篇
- 互联网数据化运营管理:复购篇
- 【转载】贝叶斯推断及其互联网应用(一):定理简介
- 互联网创业如何更好的规划商业模式
- 【原创】浅析密码学在互联网支付中的应用|RSA,Hash,AES,DES,3DES,SHA1,SHA256,MD5,SSL,Private Key,Public Key
- 互联网创业如何更好的规划商业模式
- 计算广告的历史、现状及未来