Python requests模块的学习
2016-07-14 09:03
441 查看
学习环境:python 2.7 windows10
一、 requests get 请求
1.获得一个get请求
2.获得网页文本
3.可以看到乱码。打印requests获得的网页编码
输出结果是
4.可以知道正确编码未获得可以手工指定编码
5.重新获得网页文本
输处的网页文本
可以看到编码正确
6.指定带参数的的get请求
输出的结果是
7.也可以指定head头
例如
8.获取响应码
输出结果
具体更多参数可以参看w3c或图解http这本书
9.稍微深入一下看一下get函数的代码
它实际上是调用的的request函数
request的函数调用的是session中的request,session.request,它调用的是session.send方法具体的可以自己看源码
二、post 请求
1.得到一个post请求
2.传入cookies
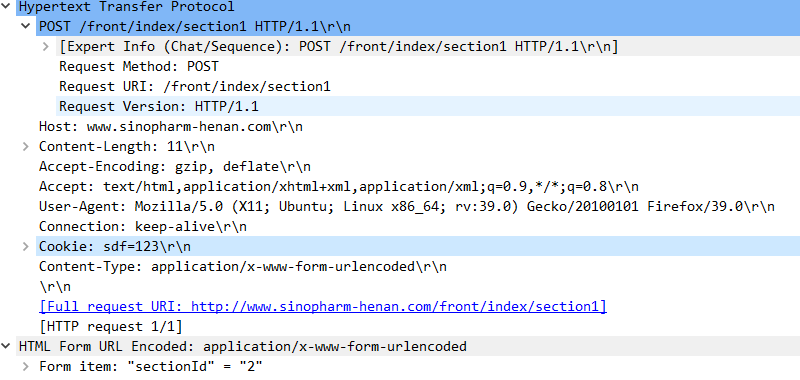
抓取数据包验证一下
3.另附r.text 和r.content的区别
先看一下content函数的源码
再看一下text函数的源代码
同时看一下返回值得类型
源代码的注释也说得很清楚,content 返回的bytes数组转成的字符串。text是经过编码后的Unicode型的数据
一、 requests get 请求
1.获得一个get请求
r = requests.get("http://www.hactcm.edu.cn"2.获得网页文本
print r.text
输出结果 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html><head><title>æ²³å—ä¸åŒ»è¯å¤§å¦ä¸æ–‡ç½‘</title> <meta http-equiv="X-UA-Compatible" content="IE=EmulateIE7" /> <meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><link rel="stylesheet" type="text/css" href="style/style.css"> <style>
3.可以看到乱码。打印requests获得的网页编码
print r.encoding
输出结果是
ISO-8859-1
4.可以知道正确编码未获得可以手工指定编码
r.encoding='utf-8'
5.重新获得网页文本
print r.text
输处的网页文本
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html><head><title>河南中医药大学中文网</title> <meta http-equiv="X-UA-Compatible" content="IE=EmulateIE7" /> <meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><link rel="stylesheet" type="text/css" href="style/style.css"> <style>
可以看到编码正确
6.指定带参数的的get请求
url='http://www.sinopharm-henan.com/front/index/section1'
pars={"sectionId":'2'}#参数
r = requests.get(url,params=pars)
print r.url输出的结果是
http://www.sinopharm-henan.com/front/index/section1?sectionId=2
7.也可以指定head头
例如
url='http://www.sinopharm-henan.com/front/index/section1'
pars={"sectionId":'2'}#参数
header={"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0",\
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",\
"Content-Type":"application/x-www-form-urlencoded"
}
r = requests.get(url,params=pars)
print r.url8.获取响应码
print r.status_code
输出结果
200
具体更多参数可以参看w3c或图解http这本书
9.稍微深入一下看一下get函数的代码
def get(url, params=None, **kwargs):
"""Sends a GET request.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary or bytes to be sent in the query string for the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
kwargs.setdefault('allow_redirects', True)
return request('get', url, params=params, **kwargs)它实际上是调用的的request函数
def request(method, url, **kwargs):
:param method: method for the new :class:`Request` object.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary or bytes to be sent in the query string for the :class:`Request`.
:param data: (optional) Dictionary, bytes, or file-like object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': ('filename', fileobj)}``) for multipart encoding upload.
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
:param timeout: (optional) How long to wait for the server to send data
before giving up, as a float, or a :ref:`(connect timeout, read
timeout) <timeouts>` tuple.
:type timeout: float or tuple
:param allow_redirects: (optional) Boolean. Set to Tru
d856
e if POST/PUT/DELETE redirect following is allowed.
:type allow_redirects: bool
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
:param verify: (optional) whether the SSL cert will be verified. A CA_BUNDLE path can also be provided. Defaults to ``True``.
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
:return: :class:`Response <Response>` object
:rtype: requests.Response
....省略
with sessions.Session() as session:
return session.request(method=method, url=url, **kwargs)request的函数调用的是session中的request,session.request,它调用的是session.send方法具体的可以自己看源码
二、post 请求
1.得到一个post请求
url='http://www.sinopharm-henan.com/front/index/section1'
data={"sectionId":'2'}
header={"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0",\
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",\
"Content-Type":"application/x-www-form-urlencoded"
}
r = requests.post(url, data=data, headers=header)
print r.url2.传入cookies
url='http://www.sinopharm-henan.com/front/index/section1'
cookie={'sdf':'123'}
data={"sectionId":'2'}
header={"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0",\
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",\
"Content-Type":"application/x-www-form-urlencoded"
}
r = requests.post(url, data=data, headers=header,cookies=cookie)
print r.url抓取数据包验证一下
3.另附r.text 和r.content的区别
先看一下content函数的源码
def content(self): """Content of the response, in bytes.""" if self._content is False: # Read the contents. try: if self._content_consumed: raise RuntimeError( 'The content for this response was already consumed') if self.status_code == 0: self._content = None else: self._content = bytes().join(self.iter_content(CONTENT_CHUNK_SIZE)) or bytes() except AttributeError: self._content = None self._content_consumed = True # don't need to release the connection; that's been handled by urllib3 # since we exhausted the data. return self._content @property
再看一下text函数的源代码
def text(self):
"""Content of the response, in unicode.
If Response.encoding is None, encoding will be guessed using
``chardet``.
The encoding of the response content is determined based solely on HTTP
headers, following RFC 2616 to the letter. If you can take advantage of
non-HTTP knowledge to make a better guess at the encoding, you should
set ``r.encoding`` appropriately before accessing this property.
"""
# Try charset from content-type
content = None
encoding = self.encoding
if not self.content:
return str('')
# Fallback to auto-detected encoding.
if self.encoding is None:
encoding = self.apparent_encoding
# Decode unicode from given encoding.
try:
content = str(self.content, encoding, errors='replace')
except (LookupError, TypeError):
# A LookupError is raised if the encoding was not found which could
# indicate a misspelling or similar mistake.
#
# A TypeError can be raised if encoding is None
#
# So we try blindly encoding.
content = str(self.content, errors='replace')
return content同时看一下返回值得类型
content的函数返回值类型 print type(r.content) # <type 'str'> text的函数返回值类型 print type(r.text) <type 'unicode'>
源代码的注释也说得很清楚,content 返回的bytes数组转成的字符串。text是经过编码后的Unicode型的数据

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- Python 七步捉虫法