[入门]selenium+JAVA实现网页爬虫(2016/7/13)
2016-07-14 00:00
369 查看
用JAVA写爬虫程序最常用的就是利用HttpClient这个第三方库了,但对于页面中JS生成的内容,则有些无能为力。另外,部分网站对爬虫程序的敏感度较高,用HttpClient访问很容易被跳转至验证码页面。而使用selenium来控制浏览器访问页面,再进行HTML解析是个有效的解决方案。
环境:JDK_1.8,Eclipse_4.6,selenium_2.53.1,Firefox_47.0.1,
selenium下载地址:http://docs.seleniumhq.org/download/ ,在Selenium Client & WebDriver Language Bindings栏中下载JAVA的jar包,下载到的是一个名为“selenium-java-2.53.1.zip”的压缩包。
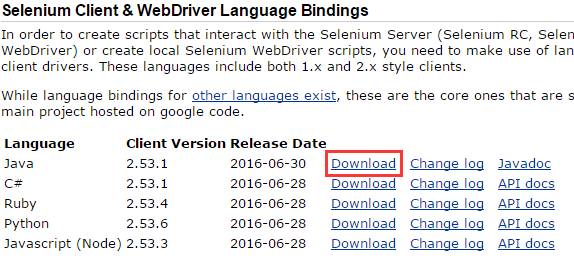
Firefox可直接被selenium调用,如果要使用其他浏览器,则需要在页面下方下载对应的浏览器驱动。
新建一个java工程,将压缩包内selenium-java-2.53.1.jar和selenium-java-2.53.1-srcs.jar,以及lib文件夹下的所有jar文件导入工程内。
之后编写一个demo进行测试,代码如下:
运行后观察启动Firefox并进行搜索的过程。
后台输出如下:
(360的搜索结果标题的标签并不完全相同,因此按照我代码中的xpath语法进行匹配,遗漏掉了几条百度贴吧的搜索结果)
环境:JDK_1.8,Eclipse_4.6,selenium_2.53.1,Firefox_47.0.1,
selenium下载地址:http://docs.seleniumhq.org/download/ ,在Selenium Client & WebDriver Language Bindings栏中下载JAVA的jar包,下载到的是一个名为“selenium-java-2.53.1.zip”的压缩包。
Firefox可直接被selenium调用,如果要使用其他浏览器,则需要在页面下方下载对应的浏览器驱动。
新建一个java工程,将压缩包内selenium-java-2.53.1.jar和selenium-java-2.53.1-srcs.jar,以及lib文件夹下的所有jar文件导入工程内。
之后编写一个demo进行测试,代码如下:
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebDriver.Navigation;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxProfile;
import org.openqa.selenium.firefox.internal.ProfilesIni;
public class Demo {
public void testFirefox(){
//如果Firefox不是安装在默认路径下,需要手动指定其位置
System.setProperty("webdriver.firefox.bin",
"D:\\Program Files\\Mozilla Firefox\\firefox.exe");
//加载Firefox默认配置
ProfilesIni pi = new ProfilesIni();
FirefoxProfile profile = pi.getProfile("default");
//启动Firefox浏览器
WebDriver ffDriver = new FirefoxDriver(profile);
Navigation navigation = ffDriver.navigate();
//打开360搜索
navigation.to("http://www.so.com");
//搜索HTML元素,支持按id、name、标签名、CSS选择器、xpath语法等方式
//用id获取搜索输入框
WebElement inputText = ffDriver.findElement(By.id("input"));
//用id获取搜索按钮
WebElement submitButton = ffDriver.findElement(By.id("search-button"));
//搜索输入框内输入“喵帕斯”
inputText.sendKeys("喵帕斯");
//为演示点击效果,延迟3秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//点击“搜一下”按钮
submitButton.click();
//使用xpath语法获取文章标题
List<WebElement> titleList =
ffDriver.findElements(By.xpath("//h3[@class='res-title']/a"));
//输出获取到的文章标题
for(WebElement e : titleList)
System.out.println(e.getText());
//5秒后关闭浏览器
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(ffDriver != null)
ffDriver.close();
}
public static void main(String args[]){
Demo demo = new Demo();
demo.testFirefox();
}
}运行后观察启动Firefox并进行搜索的过程。
后台输出如下:
喵帕斯_360百科 【悠哉日常大王】官方解释“喵帕斯”的意思_bilibili吧_百度贴吧 喵帕斯吧_百度贴吧 喵帕斯喵一喵_音MAD_鬼畜_bilibili_哔哩哔哩弹幕视频网 【喵帕斯】喵帕斯喵帕斯_音MAD_鬼畜_bilibili_哔哩哔哩弹幕视频网 「悠哉日常大王」人气投票结果公布 喵帕斯荣登榜首! - 178动漫频道 【表情、截图】喵帕斯~自己做的表情以及一些截图。_悠哉日常大王...
(360的搜索结果标题的标签并不完全相同,因此按照我代码中的xpath语法进行匹配,遗漏掉了几条百度贴吧的搜索结果)

相关文章推荐
- Python3写爬虫(四)多线程实现数据爬取
- Scrapy的架构介绍
- 爬虫笔记
- 基于C#实现网页爬虫
- Nodejs爬虫进阶教程之异步并发控制
- Node.js环境下编写爬虫爬取维基百科内容的实例分享
- PHP+HTML+JavaScript+Css实现简单爬虫开发
- 如何优雅地使用c语言编写爬虫
- PHP实现简单爬虫的方法
- NodeJS制作爬虫全过程(续)
- php实现简单爬虫的开发
- node.js基础模块http、网页分析工具cherrio实现爬虫
- PHP爬虫之百万级别知乎用户数据爬取与分析
- 一个PHP实现的轻量级简单爬虫
- nodejs爬虫抓取数据乱码问题总结
- 基于Node.js的强大爬虫 能直接发布抓取的文章哦
- nodeJs爬虫获取数据简单实现代码
- nodejs爬虫抓取数据之编码问题
- Node.js编写爬虫的基本思路及抓取百度图片的实例分享
- 针对Ruby的Selenium WebDriver安装指南