ConcurrentHashMap和HashMap和HashTable
2016-07-12 18:43
253 查看
from :http://blog.csdn.net/kobejayandy/article/details/16834311
http://blog.csdn.net/zldeng19840111/article/details/6703104 http://blog.csdn.net/vking_wang/article/details/14166593 http://www.importnew.com/7010.html
1.定义:HashMap本质数据加链表。根据key取得hash值,然后计算出数组下标,如果多个key对应到同一个下标,就用链表串起来,新插入的在前面。HashTable差别为同步和值不可非空,效率问题,具体如下介绍;ConcurrentHashMap和H[b]ashTable在于效率,算法的变更[/b]
2.综述
集合类是Java API的核心,但是我觉得要用好它们是一种艺术。我总结了一些个人的经验,譬如使用ArrayList能够提高性能,而不再需要过时的Vector了,等等。JDK 1.5引入了一些好用的并发集合类,它们对于大型的、要求低延迟的电子商务系统来说非常的有用。这篇文章中将会看看ConcurrentHashMap和Hashtable之间的区别。
这篇文章是HashMap的工作原理以及HashMap和Hashtable的区别的后续。如果你已经读过的话,那么我相信你读完本篇之后会有所收获。
同步的集合类(Hashtable和Vector),同步的封装类(使用Collections.synchronizedMap()方法和Collections.synchronizedList()方法返回的对象)可以创建出线程安全的Map和List。但是有些因素使得它们不适合高并发的系统。它们仅有单个锁,对整个集合加锁,以及为了防止ConcurrentModificationException异常经常要在迭代的时候要将集合锁定一段时间,这些特性对可扩展性来说都是障碍。
ConcurrentHashMap和CopyOnWriteArrayList保留了线程安全的同时,也提供了更高的并发性。ConcurrentHashMap和CopyOnWriteArrayList并不是处处都需要用,大部分时候你只需要用到HashMap和ArrayList,它们用于应对一些普通的情况。
Hashtable和ConcurrentHashMap有什么分别呢?它们都可以用于多线程的环境,但是当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。因为ConcurrentHashMap引入了分割(segmentation),不论它变得多么大,仅仅需要锁定map的某个部分,而其它的线程不需要等到迭代完成才能访问map。简而言之,在迭代的过程中,ConcurrentHashMap仅仅锁定map的某个部分,而Hashtable则会锁定整个map。
HashMap的工作原理是近年来常见的Java面试题。几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道Hashtable和HashMap之间的区别,那么为何这道面试题如此特殊呢?是因为这道题考察的深度很深。这题经常出现在高级或中高级面试中。投资银行更喜欢问这个问题,甚至会要求你实现HashMap来考察你的编程能力。ConcurrentHashMap和其它同步集合的引入让这道题变得更加复杂。让我们开始探索的旅程吧!
“你用过HashMap吗?” “什么是HashMap?你为什么用到它?”
几乎每个人都会回答“是的”,然后回答HashMap的一些特性,譬如HashMap可以接受null键值和值,而Hashtable则不能;HashMap是非synchronized;HashMap很快;以及HashMap储存的是键值对等等。这显示出你已经用过HashMap,而且对它相当的熟悉。但是面试官来个急转直下,从此刻开始问出一些刁钻的问题,关于HashMap的更多基础的细节。面试官可能会问出下面的问题:
“你知道HashMap的工作原理吗?” “你知道HashMap的get()方法的工作原理吗?”
你也许会回答“我没有详查标准的Java API,你可以看看Java源代码或者Open JDK。”“我可以用Google找到答案。”
但一些面试者可能可以给出答案,“HashMap是基于hashing的原理,我们使用put(key,
value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。”这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。这一点有助于理解获取对象的逻辑。如果你没有意识到这一点,或者错误的认为仅仅只在bucket中存储值的话,你将不会回答如何从HashMap中获取对象的逻辑。这个答案相当的正确,也显示出面试者确实知道hashing以及HashMap的工作原理。但是这仅仅是故事的开始,当面试官加入一些Java程序员每天要碰到的实际场景的时候,错误的答案频现。下个问题可能是关于HashMap中的碰撞探测(collision
detection)以及碰撞的解决方法:
“当两个对象的hashcode相同会发生什么?” 从这里开始,真正的困惑开始了,一些面试者会回答因为hashcode相同,所以两个对象是相等的,HashMap将会抛出异常,或者不会存储它们。然后面试官可能会提醒他们有equals()和hashCode()两个方法,并告诉他们两个对象就算hashcode相同,但是它们可能并不相等。一些面试者可能就此放弃,而另外一些还能继续挺进,他们回答“因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。”这个答案非常的合理,虽然有很多种处理碰撞的方法,这种方法是最简单的,也正是HashMap的处理方法。但故事还没有完结,面试官会继续问:
“如果两个键的hashcode相同,你如何获取值对象?” 面试者会回答:当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象。面试官提醒他如果有两个值对象储存在同一个bucket,他给出答案:将会遍历链表直到找到值对象。面试官会问因为你并没有值对象去比较,你是如何确定确定找到值对象的?除非面试者直到HashMap在链表中存储的是键值对,否则他们不可能回答出这一题。
其中一些记得这个重要知识点的面试者会说,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。完美的答案!
许多情况下,面试者会在这个环节中出错,因为他们混淆了hashCode()和equals()方法。因为在此之前hashCode()屡屡出现,而equals()方法仅仅在获取值对象的时候才出现。一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
如果你认为到这里已经完结了,那么听到下面这个问题的时候,你会大吃一惊。“如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”除非你真正知道HashMap的工作原理,否则你将回答不出这道题。默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
如果你能够回答这道问题,下面的问题来了:“你了解重新调整HashMap大小存在什么问题吗?”你可能回答不上来,这时面试官会提醒你当多线程的情况下,可能产生条件竞争(race
condition)。
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail
traversing)。如果条件竞争发生了,那么就死循环了。这个时候,你可以质问面试官,为什么这么奇怪,要在多线程的环境下使用HashMap呢?:)
4.其他问题
热心的读者贡献了更多的关于HashMap的问题:
为什么String, Interger这样的wrapper类适合作为键? String,
Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
我们可以使用自定义的对象作为键吗? 这是前一个问题的延伸。当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。
我们可以使用CocurrentHashMap来代替Hashtable吗?这是另外一个很热门的面试题,因为ConcurrentHashMap越来越多人用了。我们知道Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。看看这篇博客查看Hashtable和ConcurrentHashMap的区别。
我个人很喜欢这个问题,因为这个问题的深度和广度,也不直接的涉及到不同的概念。让我们再来看看这些问题设计哪些知识点:
hashing的概念---hash化
HashMap中解决碰撞的方法----链表
equals()和hashCode()的应用,以及它们在HashMap中的重要性key.equal----value同时找到key-----值
不可变对象的好处-----保证hashCode是不变的
HashMap多线程的条件竞争----0.75负载----调整大小----多线程调整-----竞争-----可以使用CocurrentHashMap----同步方法
使用string作为key值得原因
重新调整HashMap的大小
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。
HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
因为HashMap的好处非常多,我曾经在电子商务的应用中使用HashMap作为缓存。因为金融领域非常多的运用Java,也出于性能的考虑,我们会经常用到HashMap和ConcurrentHashMap。你可以查看更多的关于HashMap的文章:
-----------------------------------------------------------
HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是否可以随机应变使用多种思路解决问题。HashMap的工作原理、ArrayList与Vector的比较以及这个问题是有关Java 集合框架的最经典的问题。Hashtable是个过时的集合类,存在于Java API中很久了。在Java 4中被重写了,实现了Map接口,所以自此以后也成了Java集合框架中的一部分。Hashtable和HashMap在Java面试中相当容易被问到,甚至成为了集合框架面试题中最常被考的问题,所以在参加任何Java面试之前,都不要忘了准备这一题。
这篇文章中,我们不仅将会看到HashMap和Hashtable的区别,还将看到它们之间的相似之处。
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
1) sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
2) Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
3) 结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。
7.ConcurrentHashMap和HashMap
从JDK1.2起,就有了HashMap,正如前一篇文章所说,HashMap不是线程安全的,因此多线程操作时需要格外小心。
在JDK1.5中,伟大的Doug Lea给我们带来了concurrent包,从此Map也有安全的了。
ConcurrentHashMap具体是怎么实现线程安全的呢,肯定不可能是每个方法加synchronized,那样就变成了HashTable。
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
测试程序:
[java] view
plain copy


import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapTest {
private static ConcurrentHashMap<Integer, Integer> map = new ConcurrentHashMap<Integer, Integer>();
public static void main(String[] args) {
new Thread("Thread1"){
@Override
public void run() {
map.put(3, 33);
}
};
new Thread("Thread2"){
@Override
public void run() {
map.put(4, 44);
}
};
new Thread("Thread3"){
@Override
public void run() {
map.put(7, 77);
}
};
System.out.println(map);
}
}
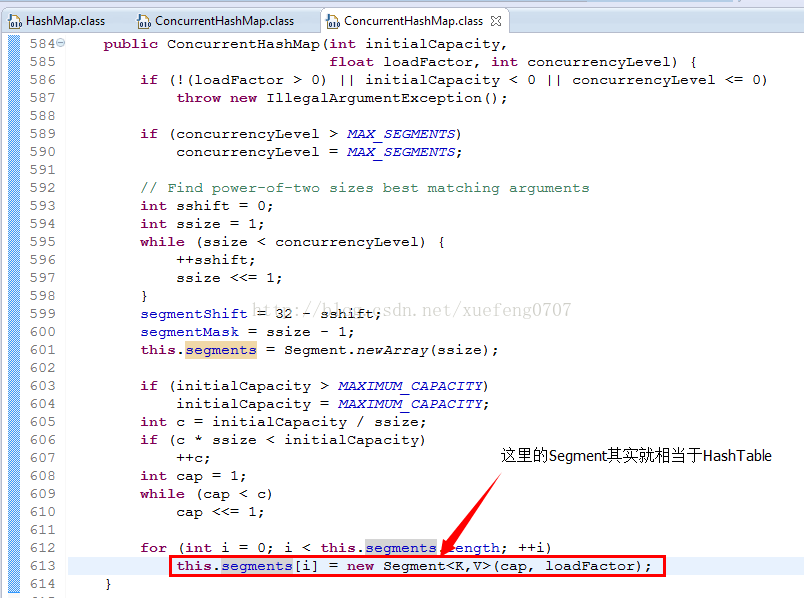
ConcurrentHashMap中默认是把segments初始化为长度为16的数组。
根据ConcurrentHashMap.segmentFor的算法,3、4对应的Segment都是segments[1],7对应的Segment是segments[12]。
(1)Thread1和Thread2先后进入Segment.put方法时,Thread1会首先获取到锁,可以进入,而Thread2则会阻塞在锁上:
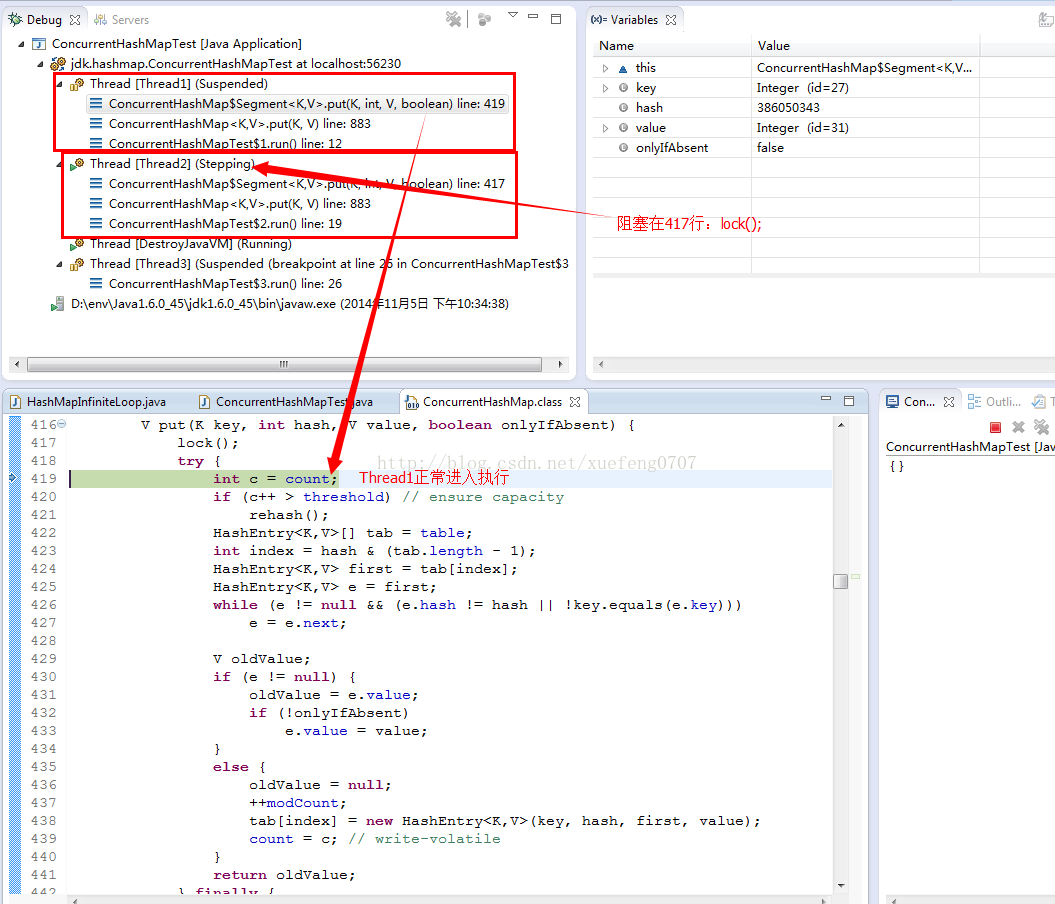
(2)切换到Thread3,也走到Segment.put方法,因为7所存储的Segment和3、4不同,因此,不会阻塞在lock():
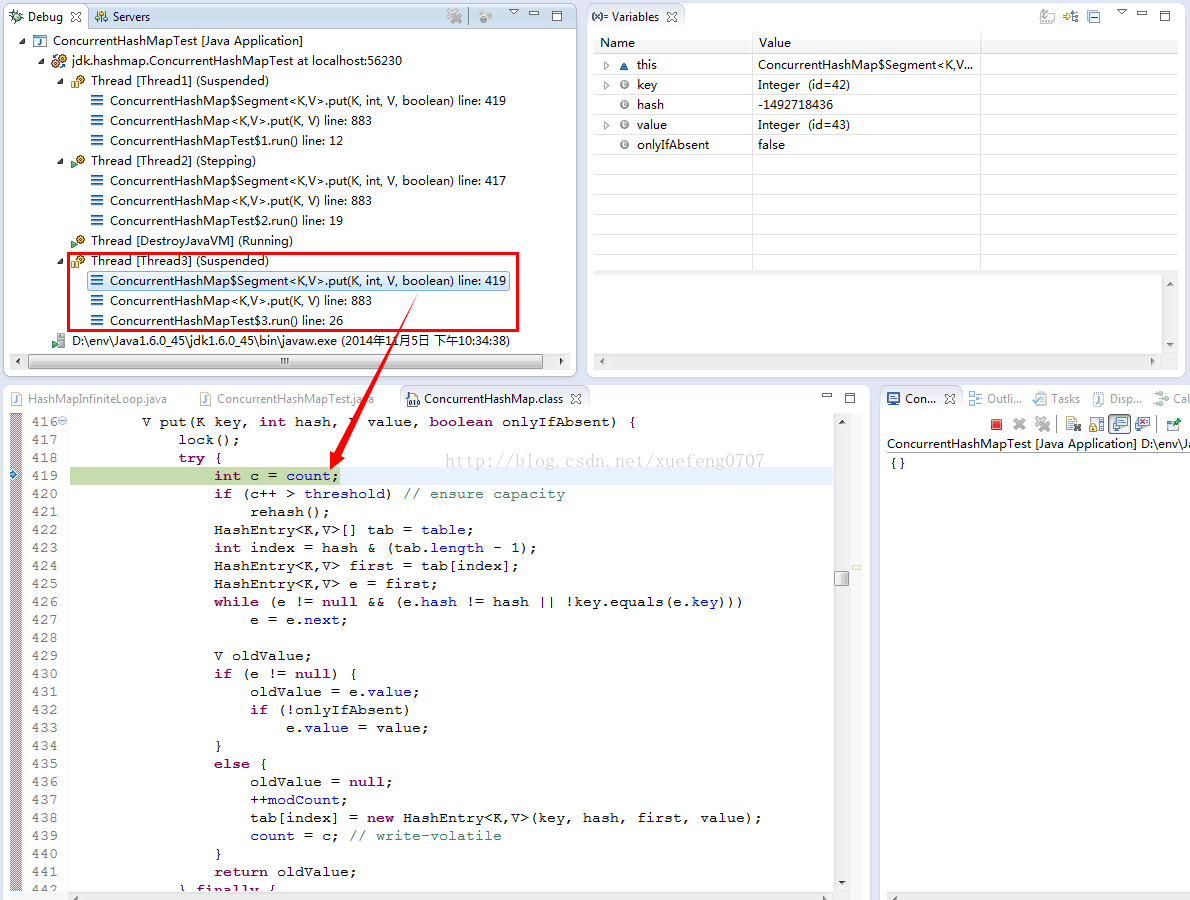
以上就是ConcurrentHashMap的工作机制,通过把整个Map分为N个Segment(类似HashTable),可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。
8.再分析:
看3段重要代码摘要:
a:
[java] view
plain copy
public HashMap(int initialCapacity, float loadFactor) {
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
有3个关键参数:
capacity:容量,就是数组大小
loadFactor:比例,用于扩容
threshold:=capacity*loadFactor 最多容纳的Entry数,如果当前元素个数多于这个就要扩容(capacity扩大为原来的2倍)
b:
[java] view
plain copy
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
根据key算hash值,再根据hash值取得数组下标,通过数组下标取出链表,遍历链表用equals取出对应key的value。
c:
[java] view
plain copy
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
从数组(通过hash值)取得链表头,然后通过equals比较key,如果相同,就覆盖老的值,并返回老的值。(该key在hashmap中已存在)
否则新增一个entry,返回null。新增的元素为链表头,以前相同数组位置的挂在后面。
另外:modCount是为了避免读取一批数据时,在循环读取的过程中发生了修改,就抛异常
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
下面看添加一个map元素
[html] view
plain copy
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
新增后,如果发现size大于threshold了,就resize到原来的2倍
[java] view
plain copy
void resize(int newCapacity) {
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
新建一个数组,并将原来数据转移过去
[java] view
plain copy
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
将原来数组中的链表一个个取出,然后遍历链表中每个元素,重新计算index并放入新数组。每个处理的也放链表头。
在取出原来数组链表后,将原来数组置空(为了大数据量复制时更快的被垃圾回收?)
还有两点注意:
static class Entry<K,V> implements Map.Entry<K,V>是hashmap的静态内部类,iterator之类的是内部类,因为不是每个元素都需要持有map的this指针。
HashMap把 transient Entry[] table;等变量置为transient,然后override了readObject和writeObject,自己实现序列化。
ConcurrentHashMap:
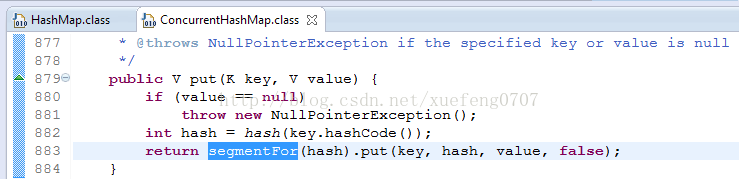
在hashMap的基础上,ConcurrentHashMap将数据分为多个segment,默认16个(concurrency level),然后每次操作对一个segment加锁,避免多线程锁得几率,提高并发效率。
[java] view
plain copy
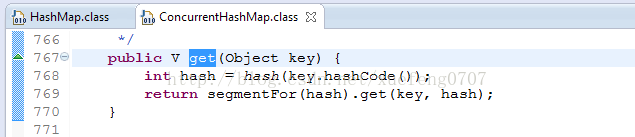
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
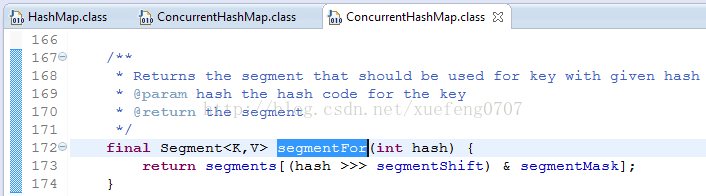
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
in class Segment:
[java] view
plain copy
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
[java] view
plain copy
/**
* Reads value field of an entry under lock. Called if value
* field ever appears to be null. This is possible only if a
* compiler happens to reorder a HashEntry initialization with
* its table assignment, which is legal under memory model
* but is not known to ever occur.
*/
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
注意,这里在并发读取时,除了key对应的value为null之外,并没有使用锁,如何做到没有问题的呢,有以下3点:
1. HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}
这里如果在读取时数组大小(tab.length)发生变化,是会导致数据不对的,但transient volatile HashEntry<K,V>[] table;是volatile得,数组大小变化能立刻知道
2. static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
这里next是final的,就保证了一旦HashEntry取出来,整个链表就是正确的。
3.value是volatile的,保证了如果有put覆盖,是可以立刻看到的。
[html] view
plain copy
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
}
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
这里除了加锁操作,其他和普通HashMap原理上无太大区别。
还有一点不理解的地方:
对于get和put/remove并发发生的时候,如果get的HashEntry<K,V> e = getFirst(hash);链表已经取出来了,这个时候put放入一个entry到链表头,如果正好是需要取的key,是否还是会取不出来?
remove时,会先去除需要remove的key,然后把remove的key前面的元素一个个接到链表头,同样也存在remove后,以前的head到了中间,也会漏掉读取的元素。
[java] view
plain copy
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
8.深度剖析
table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
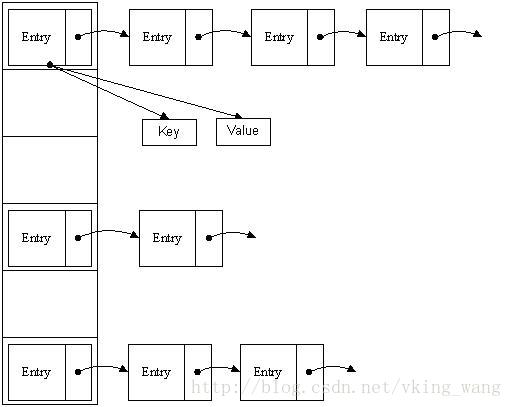
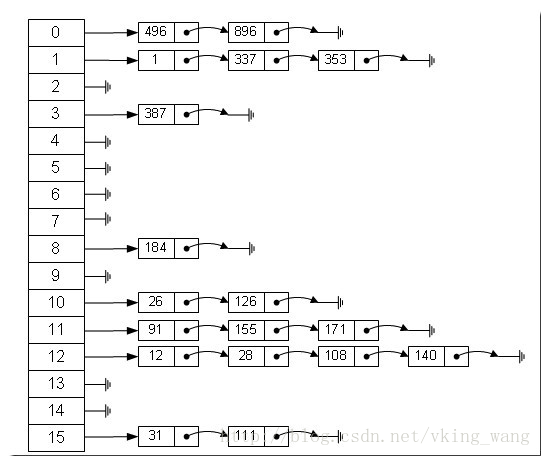
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry([b]int hash, K key, V value, int bucketIndex) {[/b]
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //参数e,
是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
}
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因子,随着map的size越来越大,Entry[]会以一定的规则加长长度。
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
按位取并,作用上相当于取模mod或者取余%。
这意味着数组下标相同,并不表示hashCode相同。
.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!!!!
————为什么这么设计呢?——
再哈希法
链地址法
建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
http://blog.csdn.net/zldeng19840111/article/details/6703104 http://blog.csdn.net/vking_wang/article/details/14166593 http://www.importnew.com/7010.html
1.定义:HashMap本质数据加链表。根据key取得hash值,然后计算出数组下标,如果多个key对应到同一个下标,就用链表串起来,新插入的在前面。HashTable差别为同步和值不可非空,效率问题,具体如下介绍;ConcurrentHashMap和H[b]ashTable在于效率,算法的变更[/b]
2.综述
集合类是Java API的核心,但是我觉得要用好它们是一种艺术。我总结了一些个人的经验,譬如使用ArrayList能够提高性能,而不再需要过时的Vector了,等等。JDK 1.5引入了一些好用的并发集合类,它们对于大型的、要求低延迟的电子商务系统来说非常的有用。这篇文章中将会看看ConcurrentHashMap和Hashtable之间的区别。
这篇文章是HashMap的工作原理以及HashMap和Hashtable的区别的后续。如果你已经读过的话,那么我相信你读完本篇之后会有所收获。
为什么我们需要ConcurrentHashMap和CopyOnWriteArrayList
同步的集合类(Hashtable和Vector),同步的封装类(使用Collections.synchronizedMap()方法和Collections.synchronizedList()方法返回的对象)可以创建出线程安全的Map和List。但是有些因素使得它们不适合高并发的系统。它们仅有单个锁,对整个集合加锁,以及为了防止ConcurrentModificationException异常经常要在迭代的时候要将集合锁定一段时间,这些特性对可扩展性来说都是障碍。ConcurrentHashMap和CopyOnWriteArrayList保留了线程安全的同时,也提供了更高的并发性。ConcurrentHashMap和CopyOnWriteArrayList并不是处处都需要用,大部分时候你只需要用到HashMap和ArrayList,它们用于应对一些普通的情况。
ConcurrentHashMap和Hashtable的区别
Hashtable和ConcurrentHashMap有什么分别呢?它们都可以用于多线程的环境,但是当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。因为ConcurrentHashMap引入了分割(segmentation),不论它变得多么大,仅仅需要锁定map的某个部分,而其它的线程不需要等到迭代完成才能访问map。简而言之,在迭代的过程中,ConcurrentHashMap仅仅锁定map的某个部分,而Hashtable则会锁定整个map。HashMap的工作原理是近年来常见的Java面试题。几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道Hashtable和HashMap之间的区别,那么为何这道面试题如此特殊呢?是因为这道题考察的深度很深。这题经常出现在高级或中高级面试中。投资银行更喜欢问这个问题,甚至会要求你实现HashMap来考察你的编程能力。ConcurrentHashMap和其它同步集合的引入让这道题变得更加复杂。让我们开始探索的旅程吧!
3.先来些简单的问题
“你用过HashMap吗?” “什么是HashMap?你为什么用到它?”几乎每个人都会回答“是的”,然后回答HashMap的一些特性,譬如HashMap可以接受null键值和值,而Hashtable则不能;HashMap是非synchronized;HashMap很快;以及HashMap储存的是键值对等等。这显示出你已经用过HashMap,而且对它相当的熟悉。但是面试官来个急转直下,从此刻开始问出一些刁钻的问题,关于HashMap的更多基础的细节。面试官可能会问出下面的问题:
“你知道HashMap的工作原理吗?” “你知道HashMap的get()方法的工作原理吗?”
你也许会回答“我没有详查标准的Java API,你可以看看Java源代码或者Open JDK。”“我可以用Google找到答案。”
但一些面试者可能可以给出答案,“HashMap是基于hashing的原理,我们使用put(key,
value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。”这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。这一点有助于理解获取对象的逻辑。如果你没有意识到这一点,或者错误的认为仅仅只在bucket中存储值的话,你将不会回答如何从HashMap中获取对象的逻辑。这个答案相当的正确,也显示出面试者确实知道hashing以及HashMap的工作原理。但是这仅仅是故事的开始,当面试官加入一些Java程序员每天要碰到的实际场景的时候,错误的答案频现。下个问题可能是关于HashMap中的碰撞探测(collision
detection)以及碰撞的解决方法:
“当两个对象的hashcode相同会发生什么?” 从这里开始,真正的困惑开始了,一些面试者会回答因为hashcode相同,所以两个对象是相等的,HashMap将会抛出异常,或者不会存储它们。然后面试官可能会提醒他们有equals()和hashCode()两个方法,并告诉他们两个对象就算hashcode相同,但是它们可能并不相等。一些面试者可能就此放弃,而另外一些还能继续挺进,他们回答“因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。”这个答案非常的合理,虽然有很多种处理碰撞的方法,这种方法是最简单的,也正是HashMap的处理方法。但故事还没有完结,面试官会继续问:
“如果两个键的hashcode相同,你如何获取值对象?” 面试者会回答:当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象。面试官提醒他如果有两个值对象储存在同一个bucket,他给出答案:将会遍历链表直到找到值对象。面试官会问因为你并没有值对象去比较,你是如何确定确定找到值对象的?除非面试者直到HashMap在链表中存储的是键值对,否则他们不可能回答出这一题。
其中一些记得这个重要知识点的面试者会说,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。完美的答案!
许多情况下,面试者会在这个环节中出错,因为他们混淆了hashCode()和equals()方法。因为在此之前hashCode()屡屡出现,而equals()方法仅仅在获取值对象的时候才出现。一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
如果你认为到这里已经完结了,那么听到下面这个问题的时候,你会大吃一惊。“如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”除非你真正知道HashMap的工作原理,否则你将回答不出这道题。默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
如果你能够回答这道问题,下面的问题来了:“你了解重新调整HashMap大小存在什么问题吗?”你可能回答不上来,这时面试官会提醒你当多线程的情况下,可能产生条件竞争(race
condition)。
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail
traversing)。如果条件竞争发生了,那么就死循环了。这个时候,你可以质问面试官,为什么这么奇怪,要在多线程的环境下使用HashMap呢?:)
4.其他问题
热心的读者贡献了更多的关于HashMap的问题:
为什么String, Interger这样的wrapper类适合作为键? String,
Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
我们可以使用自定义的对象作为键吗? 这是前一个问题的延伸。当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。
我们可以使用CocurrentHashMap来代替Hashtable吗?这是另外一个很热门的面试题,因为ConcurrentHashMap越来越多人用了。我们知道Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。看看这篇博客查看Hashtable和ConcurrentHashMap的区别。
我个人很喜欢这个问题,因为这个问题的深度和广度,也不直接的涉及到不同的概念。让我们再来看看这些问题设计哪些知识点:
hashing的概念---hash化
HashMap中解决碰撞的方法----链表
equals()和hashCode()的应用,以及它们在HashMap中的重要性key.equal----value同时找到key-----值
不可变对象的好处-----保证hashCode是不变的
HashMap多线程的条件竞争----0.75负载----调整大小----多线程调整-----竞争-----可以使用CocurrentHashMap----同步方法
使用string作为key值得原因
重新调整HashMap的大小
5.总结
HashMap的工作原理
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
因为HashMap的好处非常多,我曾经在电子商务的应用中使用HashMap作为缓存。因为金融领域非常多的运用Java,也出于性能的考虑,我们会经常用到HashMap和ConcurrentHashMap。你可以查看更多的关于HashMap的文章:
-----------------------------------------------------------
HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是否可以随机应变使用多种思路解决问题。HashMap的工作原理、ArrayList与Vector的比较以及这个问题是有关Java 集合框架的最经典的问题。Hashtable是个过时的集合类,存在于Java API中很久了。在Java 4中被重写了,实现了Map接口,所以自此以后也成了Java集合框架中的一部分。Hashtable和HashMap在Java面试中相当容易被问到,甚至成为了集合框架面试题中最常被考的问题,所以在参加任何Java面试之前,都不要忘了准备这一题。
这篇文章中,我们不仅将会看到HashMap和Hashtable的区别,还将看到它们之间的相似之处。
6.HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
要注意的一些重要术语:
1) sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。2) Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
3) 结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。
我们能否让HashMap同步?
HashMap可以通过下面的语句进行同步:Map m = Collections.synchronizeMap(hashMap);
结论
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。7.ConcurrentHashMap和HashMap
从JDK1.2起,就有了HashMap,正如前一篇文章所说,HashMap不是线程安全的,因此多线程操作时需要格外小心。
在JDK1.5中,伟大的Doug Lea给我们带来了concurrent包,从此Map也有安全的了。
ConcurrentHashMap具体是怎么实现线程安全的呢,肯定不可能是每个方法加synchronized,那样就变成了HashTable。
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
测试程序:
[java] view
plain copy
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapTest {
private static ConcurrentHashMap<Integer, Integer> map = new ConcurrentHashMap<Integer, Integer>();
public static void main(String[] args) {
new Thread("Thread1"){
@Override
public void run() {
map.put(3, 33);
}
};
new Thread("Thread2"){
@Override
public void run() {
map.put(4, 44);
}
};
new Thread("Thread3"){
@Override
public void run() {
map.put(7, 77);
}
};
System.out.println(map);
}
}
ConcurrentHashMap中默认是把segments初始化为长度为16的数组。
根据ConcurrentHashMap.segmentFor的算法,3、4对应的Segment都是segments[1],7对应的Segment是segments[12]。
(1)Thread1和Thread2先后进入Segment.put方法时,Thread1会首先获取到锁,可以进入,而Thread2则会阻塞在锁上:
(2)切换到Thread3,也走到Segment.put方法,因为7所存储的Segment和3、4不同,因此,不会阻塞在lock():
以上就是ConcurrentHashMap的工作机制,通过把整个Map分为N个Segment(类似HashTable),可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。
8.再分析:
看3段重要代码摘要:
a:
[java] view
plain copy
public HashMap(int initialCapacity, float loadFactor) {
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
有3个关键参数:
capacity:容量,就是数组大小
loadFactor:比例,用于扩容
threshold:=capacity*loadFactor 最多容纳的Entry数,如果当前元素个数多于这个就要扩容(capacity扩大为原来的2倍)
b:
[java] view
plain copy
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
根据key算hash值,再根据hash值取得数组下标,通过数组下标取出链表,遍历链表用equals取出对应key的value。
c:
[java] view
plain copy
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
从数组(通过hash值)取得链表头,然后通过equals比较key,如果相同,就覆盖老的值,并返回老的值。(该key在hashmap中已存在)
否则新增一个entry,返回null。新增的元素为链表头,以前相同数组位置的挂在后面。
另外:modCount是为了避免读取一批数据时,在循环读取的过程中发生了修改,就抛异常
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
下面看添加一个map元素
[html] view
plain copy
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
新增后,如果发现size大于threshold了,就resize到原来的2倍
[java] view
plain copy
void resize(int newCapacity) {
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
新建一个数组,并将原来数据转移过去
[java] view
plain copy
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
将原来数组中的链表一个个取出,然后遍历链表中每个元素,重新计算index并放入新数组。每个处理的也放链表头。
在取出原来数组链表后,将原来数组置空(为了大数据量复制时更快的被垃圾回收?)
还有两点注意:
static class Entry<K,V> implements Map.Entry<K,V>是hashmap的静态内部类,iterator之类的是内部类,因为不是每个元素都需要持有map的this指针。
HashMap把 transient Entry[] table;等变量置为transient,然后override了readObject和writeObject,自己实现序列化。
ConcurrentHashMap:
在hashMap的基础上,ConcurrentHashMap将数据分为多个segment,默认16个(concurrency level),然后每次操作对一个segment加锁,避免多线程锁得几率,提高并发效率。
[java] view
plain copy
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
in class Segment:
[java] view
plain copy
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
[java] view
plain copy
/**
* Reads value field of an entry under lock. Called if value
* field ever appears to be null. This is possible only if a
* compiler happens to reorder a HashEntry initialization with
* its table assignment, which is legal under memory model
* but is not known to ever occur.
*/
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
注意,这里在并发读取时,除了key对应的value为null之外,并没有使用锁,如何做到没有问题的呢,有以下3点:
1. HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}
这里如果在读取时数组大小(tab.length)发生变化,是会导致数据不对的,但transient volatile HashEntry<K,V>[] table;是volatile得,数组大小变化能立刻知道
2. static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
这里next是final的,就保证了一旦HashEntry取出来,整个链表就是正确的。
3.value是volatile的,保证了如果有put覆盖,是可以立刻看到的。
[html] view
plain copy
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
}
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
这里除了加锁操作,其他和普通HashMap原理上无太大区别。
还有一点不理解的地方:
对于get和put/remove并发发生的时候,如果get的HashEntry<K,V> e = getFirst(hash);链表已经取出来了,这个时候put放入一个entry到链表头,如果正好是需要取的key,是否还是会取不出来?
remove时,会先去除需要remove的key,然后把remove的key前面的元素一个个接到链表头,同样也存在remove后,以前的head到了中间,也会漏掉读取的元素。
[java] view
plain copy
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
8.深度剖析
1. HashMap的数据结构
数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。哈希表
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hashtable)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
2. HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
1)put
疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry([b]int hash, K key, V value, int bucketIndex) {[/b]
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //参数e,
是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
}
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因子,随着map的size越来越大,Entry[]会以一定的规则加长长度。
2)get
public V get(Object key) {if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
3)null key的存取
null key总是存放在Entry[]数组的第一个元素。private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
4)确定数组index:hashcode % table.length取模
HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标;算法如下:/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
按位取并,作用上相当于取模mod或者取余%。
这意味着数组下标相同,并不表示hashCode相同。
5)table初始大小
public HashMap(int initialCapacity, float loadFactor) {.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!!!!
————为什么这么设计呢?——
3. 解决hash冲突的办法
开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)再哈希法
链地址法
建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4. 再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}

相关文章推荐
- c语言实现hashmap(转载)
- C#中遍历Hashtable的4种方法
- C#将HashTable中键列表或值列表复制到一维数组的方法
- C#中哈希表(HashTable)用法实例详解(添加/移除/判断/遍历/排序等)
- asp.net基于HashTable实现购物车的方法
- 详解C#中HashTable的用法
- JAVASCRIPT HashTable
- JS hashMap实例详解
- java hashtable实现代码
- 解析WeakHashMap与HashMap的区别详解
- 全面解析Java中的HashMap类
- java中vector与hashtable操作实例分享
- 基于Java HashMap的死循环的启示详解
- Java中HashMap和Hashtable的区别浅析
- 重载toString实现JS HashMap分析
- C#将hashtable值转换到数组中的方法
- Android中实现HashMap排序的方法
- c语言实现的hashtable分享
- 利用C语言实现HashTable
- HashMap总结