聚类算法小记
2016-07-07 18:26
288 查看
序
博主前不久初到实验室,导师在校外接的一个项目已经进行到一半儿,导师便让我参与到项目中学习。这个项目运用的最主要技术便是“文本聚类”。
由于有个师兄要做开题报告,他的开题报告就是与聚类相关的。
每次听他的开题报告像听天书一样晦涩难懂,随着不断的深入学习与编码,总算对这种技术算是理清了思路…
概念
看了许多博客,貌似聚类没有学术界公认的定义。根据我对自己项目的理解,聚类就比如是有一大堆书籍堆在地板上,书籍有各种各样的类型的(计算机类的、医学类的、机械类的……)
现在给你布置个任务,为了方便观看,必须把这些书籍进行归类,就是计算机类的书籍放在一堆,医学类的放在一堆……
总之,聚类是一个无监督学习的分类,它没有任何先验知识可用。
关于[无监督学习(unsupervised learning)与监督学习(supervised learning)]这个博客链接写的比较形象。(http://blog.csdn.net/zd0303/article/details/8425563)
文本聚类(Text clustering)思想
基于:同类文档相似度较大,不同类文档相似度较低。过程:
1.文档切分
在做文本处理时,很多大规模数据不一定是按文本顺序分开,而是将所有的文本集放入一个大的文件中。
比如我的项目数据文件。

这个项目数据文件是一个excel文件有4532行,每一行都是一条独立的新闻数据。
当然这个excel数据的文档切分是十分容易的,也是十分显而易见的。
每一行数据就是一个独立文档(相当于)
2.文本分词
文本聚类当然是机器根据某数据指标进行归类的,机器当然不能像人一样能理解一句话的意思从而进行归类。
首先他会将一条文档数据进行分词,然后……(后文讲)分词的效果是这样:

将如上的一句话(看成一条文档数据)分成如控制台的词语。作者用的是Ansj中文分词,效果还不错。
然后此条文档数据就转化为Document = {“尊敬”, “律师”, “本人” …“3.04万元”};
3.去停用词(stopwords)(或者加载停用词)
在对自然语言进行分析与处理的时候,有时候为了提高效率以及节省空间需要去掉一些没意义的虚词。这些词语就称之为停用词。
停用词分为两类:
第一类:自然语言没实际意义的虚词(“的”、“是”、“哪”、“这”、“可”、“而且”等)。
第二类:一些动词性词汇(“给予”、“注意”等)…
对于不同的需求,任何一个词语都可能成为停用词,网上有许多停用词表,按实际需要可以自己添加一些停用词进去。
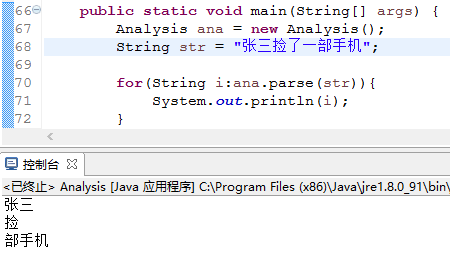
比如说,“张三捡了一部手机”这条信息,你可以将“张三”设置成停用词。
未将张三设置停用词的时候:
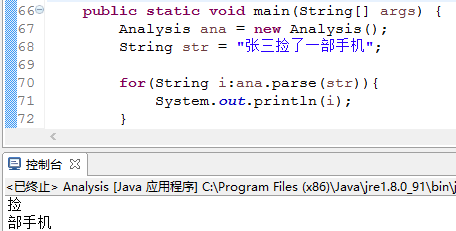
将张三设置停用词的时候:

4.文本特征提取
在去掉停用词后,我们需要在剩余的词中找到最能够代表文本主旨的词汇,最常用的方法是TFIDF(词频倒文档频率)。
该方法认为一个词的主要程度与这个词在该文本的出现频率成正比例,与这个词出现的总文档数成反比例。
也就是说,一个词在一个文本出现的越多,在其他文本中出现的越少,那么这个词对该文档的重要程度就越高。
由于我项目里每一条文档数据都是以标题进行聚类,将标题分词后得到的词语不是很多,顾省略了这一步骤。
5.文本向量化
文本向量化就是将分词结果进行一系列处理使之向量化。
这里分作两步骤:
(1)计算权重。

通过这一步处理后,就将文本分词结果的Document = {“尊敬”, “律师”, “本人” …“3.04万元”};
转化为DocumentVector ={weight1,weight2,weight3 …… weightN};(计算太麻烦…略)
(2)N维空间向量模型
将上一步得到的DocumentVector放到N维空间向量模型中,文档D在i坐标轴下的映射就是文档D的i词元的权重。

在N维空间向量模型中,两向量的夹角越小,我们认为它们越相似。可以利用余弦相似度公式:
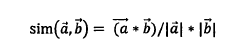
余弦相似度为1表示两个向量完全相同,相似度为0表示两个向量相互垂直(完全不相似)。
5.将相似文档归类
6.验证
聚类算法
关于聚类的算法有许多但没有一种聚类算法能够适用于所有类型数据。总得来说有以下几种。
层次聚类(Hierarchical Clustering)
基于密度的聚类(Density-Based Clustering)
基于网格的聚类(grid-based Clustering)
基于划分的聚类(Partitioning-Based Clustering)
蚁群聚类算法
群体智能聚类算法
关于以上几种聚类算法,大牛博客里都有相关的讲解。
主要讲讲关于层次聚类(Hierarchical Clustering)
假设有N个待聚类的样本,对于层次聚类来说,基本步骤就是:
1.(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
2.寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
3.重新计算新生成的这个类与各个旧类之间的相似度;
4.重复2和3直到所有样本点都归为一类,结束。
在聚类过程中,可以在第二步上设置一个阀值,当最近的两个类的距离大于这个阀值,那么可以认为迭代可以终止。
关于第三步判断两个类的相似度(可参照上文的“4.文本向量化”)一般在层次聚类中有四种连接方式:
单连接法(SingleLinkage):又叫做nearest-neighbor,两类的距离定义为一类的所有个体与另一类的所有个体之间的距离最小者。也就是说,最近两个样本之间的距离越小,这两个类之间的相似度就越大。容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。
全连接法(CompleteLinkage):这个则完全是 Single Linkage 的反面极端,取两个集合中距离最远的两个点的距离作为两个集合的距离。其效果也是刚好相反的,限制非常大,两个 cluster 即使已经很接近了,但是只要有不配合的点存在,就顽固到底,老死不相合并,也是不太好的办法。这两种相似度的定义方法的共同问题就是指考虑了某个有特点的数据,而没有考虑类内数据的整体特点。

组平均距离层次聚类(Average-linkage):这种方法就是把两个集合中的点两两的距离全部放在一起求一个平均值,相对也能得到合适一点的结果。
质心聚类(Centroid Clustering):average-linkage的一个变种就是取两两距离的中值,与取均值相比更加能够解除个别偏离样本对结果的干扰。

对最开始的那个数据的聚类结果如下:

程序运行了大概3-5秒钟左右的样子。
“四川眉山12岁住校女生宿舍内死亡 当地警方公布案情”相似的新闻数据有219条。
看,聚类技术在对新闻的筛选有着非常显著的作用!
如果人为从4500条数据筛选相似的数据的话,那将是灾难性的工作。
后记
博主的第一篇博客!ps:写博客真的很耗时间…

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树