Redis学习笔记01--NoSQL/Redis概述
2016-07-04 15:48
453 查看
1.关于NoSQL
NoSQL(Not Only SQl),意思是反SQL运动,是一项全新的数据库革命性运动,早期就有人提出,发展至2009年越发高涨,指的是非关系型数据库(例如,MySQL,Sql Server和Oracle等),随着互联网web2.0的兴起,特别是超大规模和高并发的SNS类型的web纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系数据库,则由于其本身的特点而得到非常快速的发展,Redis就是其中典型的代表。NoSql是key-value形式存储(json便是一种典型的ke-value形式的结构),和传统的关系型数据库不同,不遵循传统数据库的一些要求,比如遵循SQL标准,ACID事务特点(原子性,隔离性,一致性和永久性),表结构等,这些数据库有如下特点:
● 非关系型;
● 分布式的;
● 开源的;
● 水平可扩展
>>NoSQL具有以下的优势:
● 处理超大规模的数据;● 可以运行在较为便宜的PC服务器集群上;
● 性能高。
>>NoSQL的适应场景:
● 对数据高并发读写,如果对MySQL进行每秒上万次的查询尚可,但是对写操作便效率低下了,而NoSQL没有这种瓶颈;● 对海量数据的高效率存储和访问;
● 对数据的高可扩展性和高可用性,NoSQL对分布式支持的很好,而且没有固定的表结构,是一种松散的数据形式。
2.关于Redis
>>关于Redis
Redis是一个开源,先进的key-value存储,通常被称为数据结构服务器,因为键可以包括:字符串(Strings),哈希(Hashes),链表(Lists),集合(Sets)和有序集合(Zsets),并用于构建高性能,可扩展的Web应用程序的完美解决方案。Redis从它的许多竞争继承来的三个主要特点:
- ● Redis数据库完全在内存中,使用磁盘仅用于持久性;
- ● 相比许多键值数据存储,Redis拥有一套较为丰富的数据类型,五种数据结构;
- ● Redis可以将数据复制到任意数量的从服务器。
Redis上述的数据结构,均支持push/pop,add/remove以及取交集和并集及更丰富的操作,Redis支持各种不同方式的排序。为了保证效率,数据都是缓存在内存中,也可以周期性的把更新的数据写入磁盘(数据库快照)或者把修改操作写入追加的记录文件(Aof持久化)。
>>Redis的优势
● 异常快速:Redis的速度非常快,每秒能执行约11万集合,每秒约81000+条记录,因为数据是存在于内存中的;● 支持丰富的数据类型:Redis支持最大多数开发人员已经知道像列表,集合,有序集合,散列数据类型,这使得它非常容易解决各种各样的问题,因为我们知道哪些问题是可以处理通过它的数据类型更好。
● 操作都是原子性:所有Redis操作是原子的,这保证了如果两个客户端同时访问的Redis服务器将获得更新后的值。
● 多功能实用工具:Redis是一个多实用的工具,可以在多个用例如缓存,消息,队列使用(Redis原生支持发布/订阅),任何短暂的数据,应用程序,如Web应用程序会话,网页命中计数等。
>>应用实例
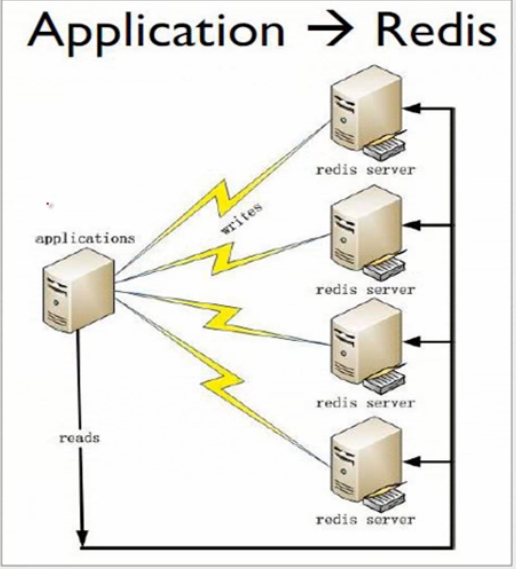
目前Redis最大的全球用户是新浪微博,在新浪微博Redis的部署场景:- 1. 应用程序直接访问Redis数据库服务,这种情况比较简单,如果Redis down机,数据会丢失;
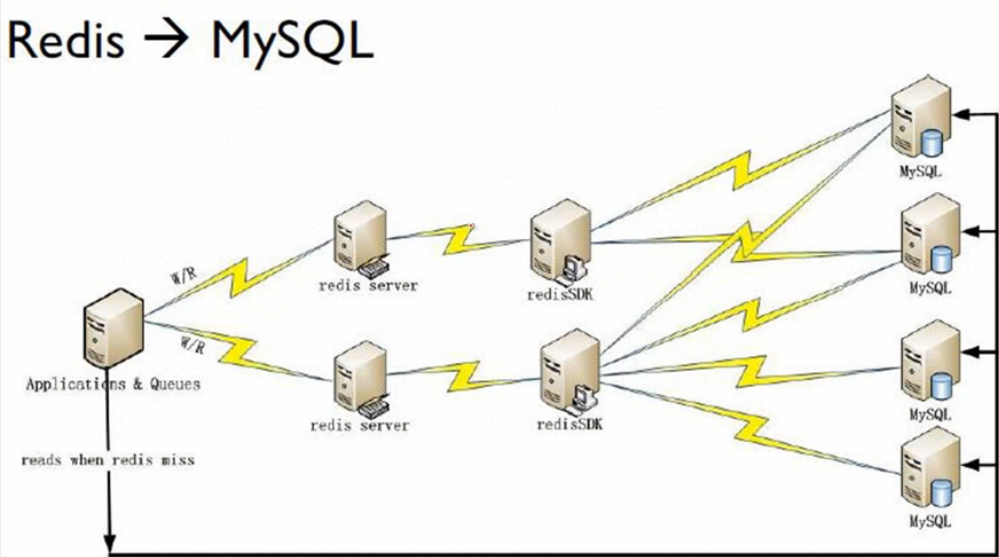
- 2. 应用程序直接访问Redis,只有在Redis访问失败时会访问MySQL。
3.Redis一些具体的使用场合
>> 取最新的N个数据,显示最新的数据项目列表;
例如微博中列出最新的100条回复,如果使用关系型数据库,则需要排序SELECT * FROM foo WHERE … ORDER BY time DESC LIMIT 10,随着数据库中数据项的增加,排序操作会变得越来越困难和费时。类似的问题利用Redis来解决变得很简单,对于每条回复我们都有一个唯一递增的ID字段,同时维持一个指定长度的列表,每次有新的评论来时,便将评论LPUSH到列表中,每次我们需要获取最新评论时,就可以利用lrange函数来获取,例如获取回复的100条:lrange 0 99。>>排行榜TOP N的操作;
Sorted Sets是将 Set 中的元素增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列。典型的比如在线游戏的排行榜,比如一个Facebook的游戏,根据得分你通常想要:列出前100名高分选手,列出某用户当前的全球排名。
这些操作对于Redis来说也很简单,即使你有几百万个用户,每分钟都会有几百万个新的得分。
每次获得新得分时,我们用这样的代码:
ZADD leaderboard ,当然可以用userID来取代username,得到前100名高分用户很简单:ZREVRANGE leaderboard 0 99
>>精确设置过期时期;
Redis中对于每个Key都可以利用expire命令来设置key的有效时间,这为需要精确设置过期时间的应用提供了一个很简单的实现方式。>>计数器;
Redis提供的incr和incrby命令使得Redis自然成为一种很好的计数器,而且这些计数操作都是原子的。例如按日期统计一个网站的访问量,我们可以把日期带入计数器key就可以了:#假定操作 2014-07-06 数据
#获取注册用户数
get total_users:2014-07-06
# 2014-07-06 注册用户数增加一位
incr total_users:2014-07-06
# 设置 48 小时过期时间 172800 = 48 * 60 * 60
expire total_users:2014-07-06 172800
>>Uniq排重
Redis提供了Set集合数据结构,集合中元素是不能重复的,因此我们仅仅需要将待排重的数据存到set中即可,还是以微博应用为例,对于一篇微博,一位用户只能点赞一次,那我们可以为这篇微博维护一个Set,这样对于一个已经点过赞的用户便加入到Set中,如果这个用户再次试图点赞时,Set便不能重复加入这个用户,这样赞的总个数便是set中元素的个数。>>实时分析系统,反垃圾系统,反垃圾邮件等;
同样,Set的功能功能,可以统计一个终端用户是否进行了某个操作,可以找到其操作的集合并进行分析统计对比等。>>pub/sub构建实时消息系统;
Redis的Pub/Sub非常非常简单,运行稳定并且快速。支持模式匹配,能够实时订阅与取消频道。Redis的Pub/Sub系统可以构建实时的消息系统,比如很多用Pub/Sub构建的实时聊天和群聊系统的例子。>>构建消息队列系统;
Redis提供的List结构既可以作为先进先出的栈,又可以作为后进先出的队列来使用,利用list来实现队列系统也很简单,利用消息队列可以实现消息生产者和消费者的解耦,实现消息的异步处理。>>实现缓存;
这大概是现在Redis最经常使用的场景了,因为Redis的数据操作全是在内存中进行的,所以其速度很可观。据研究,其性能要优于Memcached,且数据结构更多样化,完全可以代替Memcached。
相关文章推荐
- Android之获取手机上的图片和视频缩略图thumbnails
- redis安装问题小结
- nosql
- 数据库链接字符串查询网站
- DB2实例管理
- DB2实例管理
- 保障MySQL数据安全的14个最佳方法
- mysql问答汇集
- 使用 Redis 和 Python 构建一个共享单车的应用程序
- 第三章 数据库备份和还原
- Redis偶发连接失败案例实战记录
- 创建一个空的IBM DB2 ECO数据库的方法
- Access 2000 数据库 80 万记录通用快速分页类
- 开通一个数据库失败的原因的和解决办法
- 一个简单的asp数据库操作类
- CentOS下DB2数据库安装过程详解
- EasyASP v1.5发布(包含数据库操作类,原clsDbCtrl.asp)第1/2页
- sql2008 还原数据库解决方案
- Oracle 数据库自动存储管理-安装配置